Hadoop集群常见脚本
集群启动/停止方法
1.各个模块分开启动/停止(配置ssh是前提)
(1)整体启动/停止HDFS
start-dfs.sh/stop-dfs.sh
(2)整体启动/停止YARN
start-yarn.sh/stop-yarn.sh
2.各个服务组件逐一启动/停止
(1)分别启动/停止HDFS 组件
hdfs --daemon start/stop namenode/datanode/secondarynamenode
(2)启动/停止YARN
yarn --daemon start/stop resourcemanager/nodemanager
Hadoop集群常用脚本
集群包括hadoop102,hadoop103,hadoop104
xsync分发脚本
循环复制文件到所有节点的相同目录下,格式:xsync [要同步的文件名称]
1 [jinci@hadoop102 ~]$ cd /home/jinci 2 [jinci@hadoop102 ~]$ mkdir bin 3 [jinci@hadoop102 ~]$ cd bin 4 [jinci@hadoop102 bin]$ vim xsync
编辑如下代码:
1 #!/bin/bash 2 3 #1. 判断参数个数 4 if [ $# -lt 1 ] 5 then 6 echo Not Enough Arguement! 7 exit; 8 fi 9 #2. 遍历集群所有机器 10 for host in hadoop102 hadoop103 hadoop104 11 do 12 echo ================= $host ================= 13 #3. 遍历所有目录,挨个发送 14 15 for file in $@ 16 do 17 #4. 判断文件是否存在 18 if [ -e $file ] 19 then 20 #5. 获取父目录 21 pdir=$(cd -P $(dirname $file); pwd) 22 23 #6. 获取当前文件的名称 24 fname=$(basename $file) 25 ssh $host "mkdir -p $pdir" 26 rsync -av $pdir/$fname $host:$pdir 27 else 28 echo $file does not exists! 29 fi 30 done 31 done
保存后退出,然后赋予脚本执行权限
[jinci@hadoop102 bin]$ chmod 777 xsync
分发失败原因有可能是未找到脚本,可尝试
1 [jinci@hadoop102 ~]$ sudo ./bin/xsync [要分发的文件位置]
若分发文件为配置环境变量信息,分发文件后记得执行
1 source /etc/profile
Hadoop集群启停脚本(包含HDFS,Yarn,Historyserver): myhadoop.sh
[jinci@hadoop102 ~]$ cd /home/jinci/bin
[jinci@hadoop102 bin]$ vim myhadoop.sh
输入如下内容
#!/bin/bash if [ $# -lt 1 ] then echo "No Args Input..." exit ; fi case $1 in "start") echo " =================== 启动 hadoop集群 ===================" echo " --------------- 启动 hdfs ---------------" ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh" echo " --------------- 启动 yarn ---------------" ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh" echo " --------------- 启动 historyserver ---------------" ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver" ;; "stop") echo " =================== 关闭 hadoop集群 ===================" echo " --------------- 关闭 historyserver ---------------" ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver" echo " --------------- 关闭 yarn ---------------" ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh" echo " --------------- 关闭 hdfs ---------------" ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh" ;; *) echo "Input Args Error..." ;; esac
保存后退出,然后赋予脚本执行权限
[jinci@hadoop102 bin]$ chmod 777 myhadoop.sh
启动/停止脚本
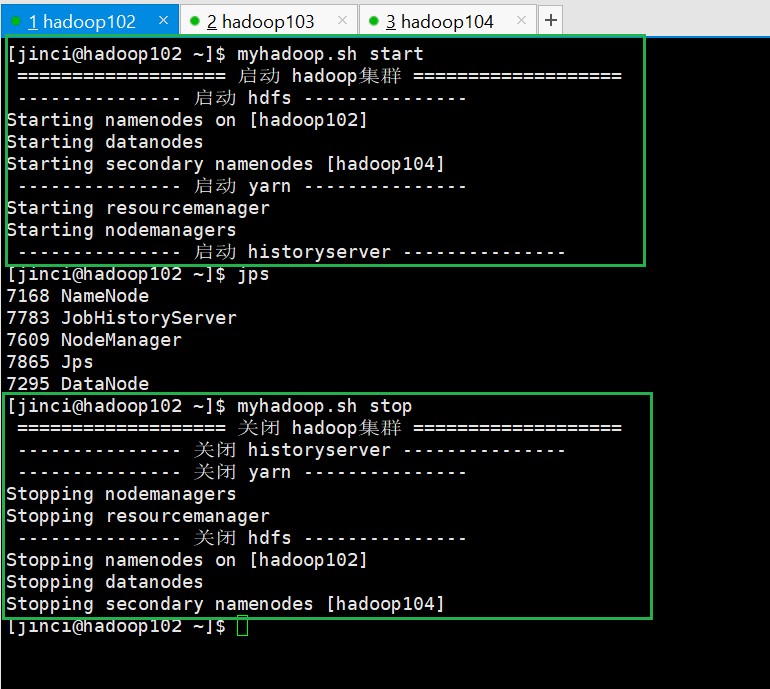
[jinci@hadoop102 ~]$ myhadoop.sh start/stop
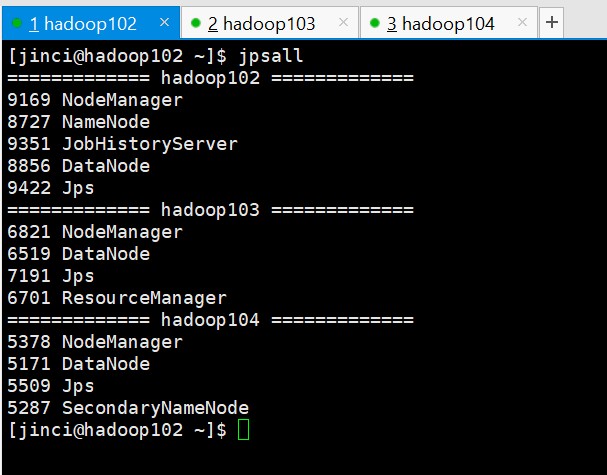
查看三台服务器Java进程脚本:jpsall
[jinci@hadoop102 ~]$ cd /home/jinci/bin
[jinci@hadoop102 bin]$ vim jpsall
输入以下内容:
#!/bin/bash for host in hadoop102 hadoop103 hadoop104 do echo =============== $host =============== ssh $host jps done
保存后退出,然后赋予脚本执行权限
[jinci@hadoop102 bin]$ chmod 777 jpsall
分发/home/jinci/bin 目录, 保证自定义脚本在三台机器上都可以使用
[jinci@hadoop102 ~]$ xsync /home/atguigu/bin/
运行效果:
myhadoop
jpsall
ZK集群启动停止脚本
在hadoop102的/home/jinci/bin目录下创建脚本zk.sh
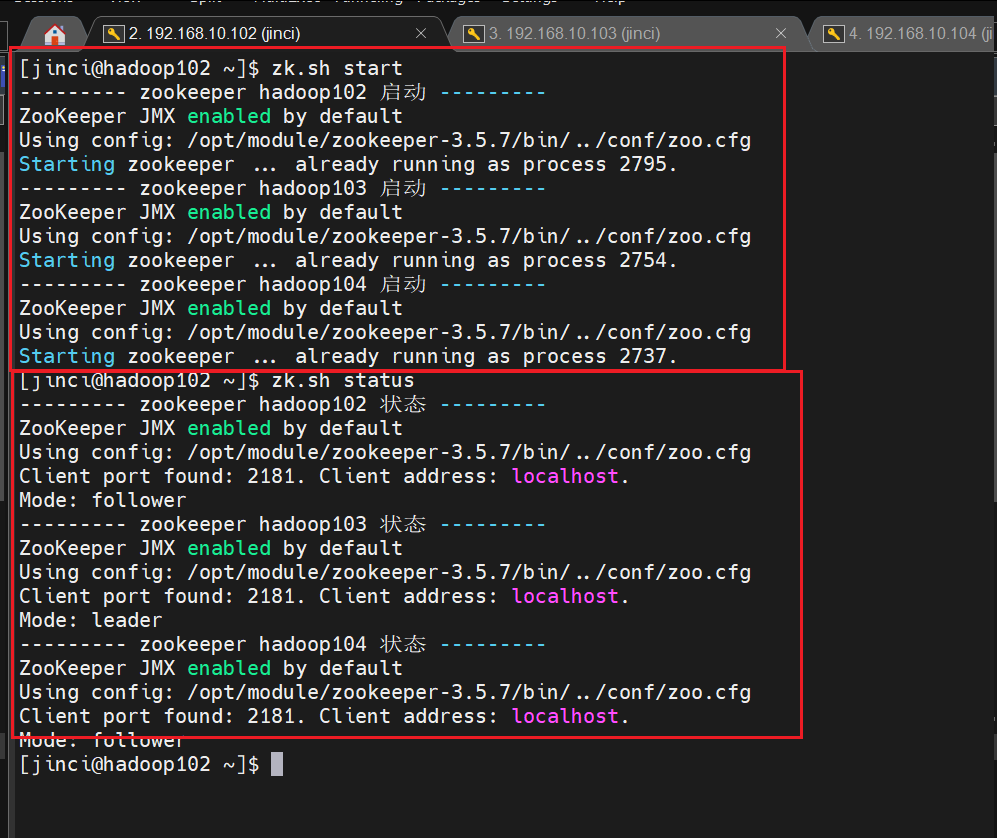
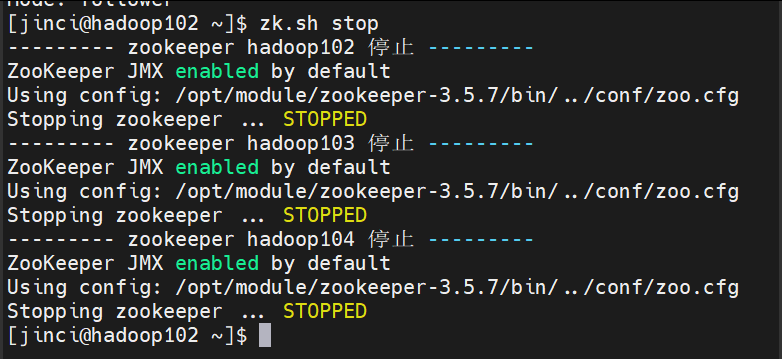
1 #!/bin/bash 2 3 case $1 in 4 "start"){ 5 for i in hadoop102 hadoop103 hadoop104 6 do 7 echo --------- zookeeper $i 启动 --------- 8 ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh start" 9 done 10 } 11 ;; 12 "stop"){ 13 for i in hadoop102 hadoop103 hadoop104 14 do 15 echo --------- zookeeper $i 停止 --------- 16 ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh stop" 17 done 18 } 19 ;; 20 "status"){ 21 for i in hadoop102 hadoop103 hadoop104 22 do 23 echo --------- zookeeper $i 状态 --------- 24 ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh status" 25 done 26 } 27 ;; 28 esac
保存后退出,然后赋予脚本执行权限
[jinci@hadoop102 bin]$ chmod 777 zk.sh
运行效果:
zk.sh
本文来自博客园,作者:锦此,转载请注明原文链接:https://www.cnblogs.com/jinci2022/p/16490002.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号