python正则表达式基础,以及pattern.match(),re.match(),pattern.search(),re.search()方法的使用和区别
正则表达式(regular expression)是一个特殊的字符序列,描述了一种字符串匹配的模式,可以用来检查一个字符串是否含有某种子字符串。
将匹配的子字符串替换或者从某个字符串中取出符合某个条件的子字符串,或者是在指定的文章中抓取特定的字符串等。
Python处理正则表达式的模块是re模块,它是Python语言中拥有全部的正则表达式功能的模块。
正则表达式由一些普通字符和一些元字符组成。普通字符包括大小写的字母、数字和打印符号,而元字符是具有特殊含义的字符。
正则表达式大致的匹配过程是:
拿正则表达式依次和字符串或者文本中的字符串做比较,如果每一个字符都匹配,则匹配成功,只要有一个匹配不成功的字符,则匹配不成功。
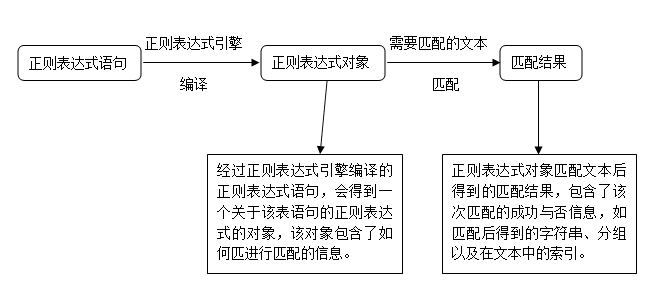
正则表达式模式
正则表达式是一种用来匹配字符串得强有力的武器。
它的设计思想是用一种描述性的语言来给字符串定义一个规则,凡是符合规则的字符串,我们就认为它“匹配”了,否则,就是匹配不成功。
模式字符串使用特殊的语法来表示一个正则表达式:
字母和数字匹配它们自身;
多数字母和数字前加一个反斜杠(\)时会有特殊的含义;
特殊的标点符号,只有被转义以后才能匹配自身;
反斜杠本身需要反斜杠来转义;
注意:
由于正则表达式通常包含反斜杠等特殊字符,所以我们最好使用原始字符串来表示他们。如:r’\d’,等价于’\\d’,表示匹配一个数字。
Python正则表达式中,数量词默认都是贪婪的,它们会尽力尽可能多的去匹配满足的字符,但是如果我们在后面加上问号“?”,就可以屏蔽贪婪模式,表示匹配尽可能少的字符。
如字符串:“xyyyyzs”,使用正则“xy*”,就会得到“xyyyy”;如果使用正则“xy*?”,将只会匹配“x”
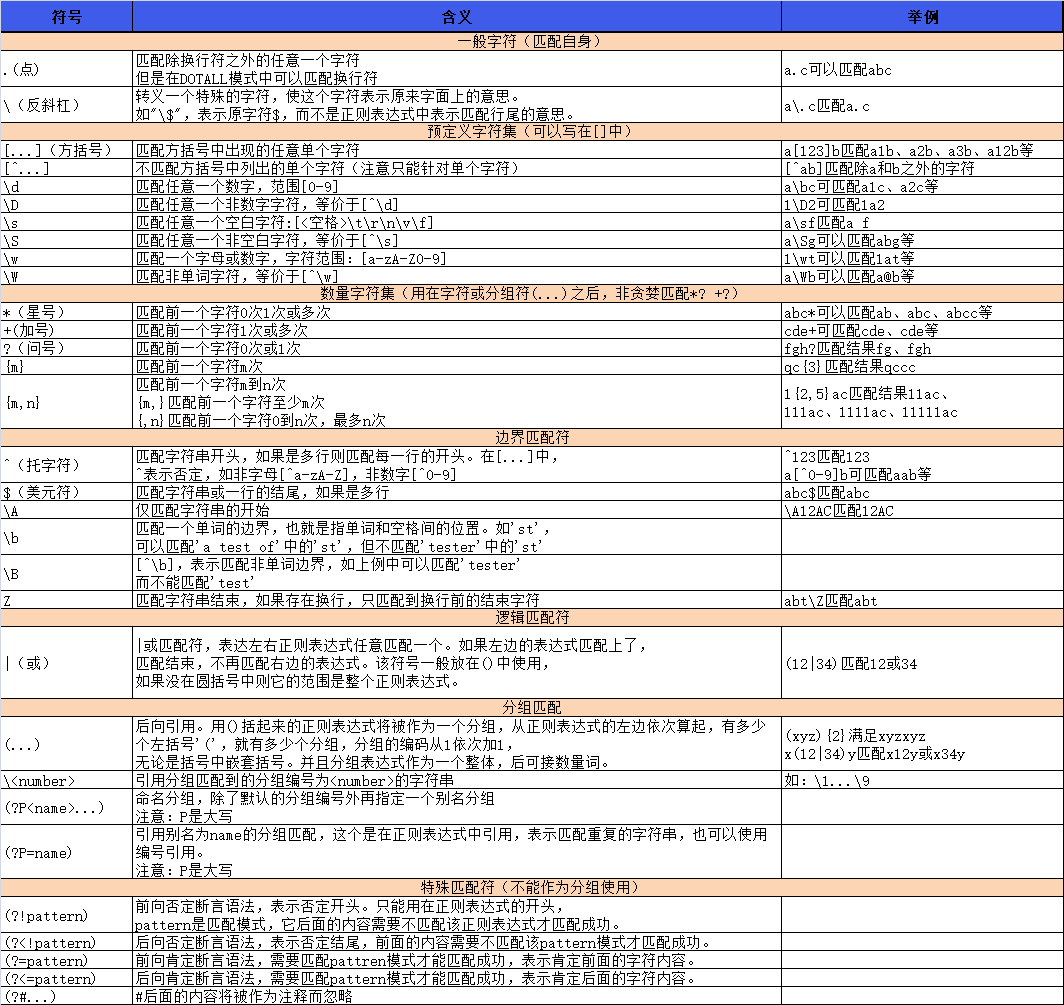
下表列出了正则表达式模式语法中的特殊元素。如果你是使用模式的同时提供了可选的标志参数,某些模式元素含义就会改变。
编译正则表达式基础
Python通过re模块提供对正则表达式的支持。使用re的一般步骤是先将正则表达式的字符串形式编译为pattern实例,然后使用pattern实例处理文本并获取匹配结果(一个Match实例),最后使用Match实例获取信息,进行其他的操作。
编辑正则表达式,可以提高程序的执行速度。
下面是pattern模式处理正则表达式的流程:
示例代码:
#coding=utf-8
import re
# 将正则表达式编译成Pattern对象
pattern = re.compile(r'hello')
# 使用Pattern匹配文本,获得匹配结果,无法匹配时将返回None
match = pattern.match('hello world!')
if match:
# 使用Match获得分组信息
print match.group()
结果:
c:\Python27\Scripts>python task_test.py
hello
正则表达式-- re.compile
re.compile(pattern, flags=0) 这个方法是pattern类的工厂方法,目的是将正则表达式pattern编译成pattern对象,并返回该对象。
它可以把正则表达式编译成一个正则表达式对象。
我们可以把那些经常使用的正则表达式编译成正则表达式对象,这样可以提高一定的效率。
第二个参数flag是匹配模式,取值可以使用按位或运算符“|”表示同时生效,比如re.I | re.M(忽略大小写,换行匹配)。
当然你也可以在regex字符串中指定模式,比如:
re.compile('pattern', re.I | re.M)
它等价于: re.compile('(?im)pattern'),例如:
>>> p=re.compile("\w+",re.I|re.M)
>>> p.match("sadf234").group()
'sadf234'
>>> p=re.compile("(?im)\w+")
>>> p.match("sadf234").group()
'sadf234'
re模块提供了很多用于完成正则表达式的功能。
那为什么还有使用pattern实例的相应方法替代呢? 使用该pattern模式唯一的好处就是,一处编译,多处复用。
pattern = re.compile(r'hello')
pattern.match('hello world!')
以上两句等价于re.match(r”hello”,”hello world!”)
示例代码:
#coding=utf-8
import re
# 将正则表达式编译成Pattern对象
pattern = re.compile(r'hello')
print pattern
# 使用Pattern匹配文本,获得匹配结果,无法匹配时将返回None
match1 = pattern.match('hello world!')
if match1:
print u"第一次使用"
# 使用Match获得分组信息
print match1.group()
match2 = pattern.match("hello, everyone, I am coming.")
if match2 :
print u"第二次使用"
print match2.group()
结果:
c:\Python27\Scripts>python task_test.py
<_sre.SRE_Pattern object at 0x04D5B7A0>
第一次使用
hello
第二次使用
hello
pattern对象下有哪些属性和方法:
Pattern对象是一个编译好的正则表达式,也就是通过re.compile()函数编译后得到结果。
通过pattern提供的一系列方法可以对文本进行匹配查找。
Pattern不能直接实例化,必须使用re.compile()函数进行构造。
pattern提供了几个可读属性及方法用于处理正则表达式。
pattern对象下有哪些属性和方法:
>>> pattern=re.compile(r"hello")
>>> dir(pattern)
['findall', 'finditer', 'flags', 'groupindex', 'groups', 'match', 'pattern', 'scanner', 'search', 'split', 'sub', 'subn']
pattern.match()方法:
这个方法将在字符串string的pos位置开始尝试匹配pattern(pattern就是通过re.compile()方法编译后返回的对象),如果pattern匹配成功,无论是否达到结束位置endpos,都会返回一个匹配成功后的Match对象;如果匹配不成功,或者pattern未匹配结束就达到endpos,则返回None。
参数说明:
string:被匹配的字符串
pos:匹配的起始位置,可选,默认为0
endpos:匹配的结束位置,可选,默认为len(string)
匹配到的Match对象,我们将使用其具有的group()方法取出匹配结果。
re.match方法从头开始匹配,匹配不到就返回None
pattern.match和re.match的区别是pattern.match可以指定匹配的起始位置
例子:
>>> import re
>>> pattern=re.compile(r"\w+")
>>> pattern.match("qwer123",0,2).group()
'qw'
>>> pattern.match("qwer123",0,3).group()
'qwe'
re.match()方法
该函数的作用是尝试从字符串string的起始位置开始匹配一个模式pattern,如果匹配成功返回一个匹配成功后的Match对象,否则返回None。
参数说明:
pattern:匹配的正则表达式
string:要匹配的字符串
flags:标志位,用于控制正则表达式的匹配方式。如是否区分大小写、是否多行匹配等。
例子:
>>> re.match(r"\w+","avde").group()
'avde'
re.match()方法与pattern.match()方法区别:
re.match()不能指定匹配的区间pos和endpos两个参数,pattern.match可以。
pattern. search()方法
函数作用:
该方法的作用是在string[pos, endpos]区间从pos下标处开始匹配pattern,如果匹配成功,返回匹配成功的Match对象;
如果没有匹配成功,则将pos加1后重新尝试匹配,直到pos=endpos时仍无法匹配则返回None。
参数说明:
string:被匹配的字符串
pos:匹配的起始位置,可选,默认为0
endpos:匹配的结束位置,可选,默认为len(string)
也就是说如果不指定pos和endpos这两个参数的话,该方法会扫描整个字符串。
例子:
>>> pattern=re.compile("\d+\w*")
>>> pattern.search("12abc123ABc123",0,10).group()
'12abc123AB'
>>> pattern.search("12abc123ABc123",0,9).group()
'12abc123A'
re.search方法:
扫描整个字符串并返回第一次成功的匹配对象,如果匹配失败,则返回None。
参数说明:
pattern:匹配的正则表达式
string:要匹配的字符串
flags:标志位,用于控制正则表达式的匹配方式。如是否区分大小写、是否多行匹配等。
>>> re.search(r"[abc]\*\d{2}","12a*23Gb*12ab").group()
'a*23'
re.search()方法与pattern.search()方法区别:
re.search()不能指定匹配的区间pos和endpos两个参数。
re.match与re.search的区别:
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,并返货None;
而re.search匹配整个字符串,直到找到一个匹配。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号