one-shot learning
one-shot learning
引言
今天来给大家介绍一种深度学习网络。在介绍之前,先来给大家聊一聊题外话。
相信大家都学过cnn卷积神经网络吧,知道卷积神经网络包含卷积层、池化层和全连接层。其工作原理大致为:
图片(输入)->卷积层(提取特征)->池化层(减少参数量)->全连接层(计算每一类的得分值)->softmax处理(得出每一类对应的概率)
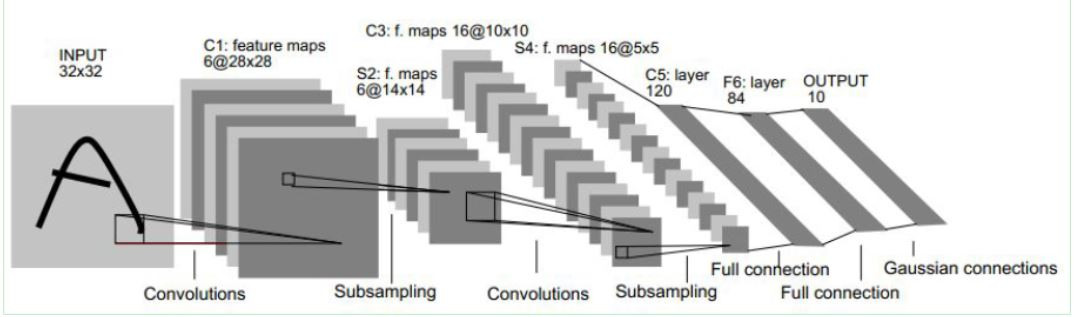
对于cnn卷积神经网络来说(其实其他网络也一样)都需要足够大的数据集来支撑,才能得出比较好的模型,最终才能预测出比较精准的结果。
但自然界中,能够支持我们每一次都能找到足够多的照片来训练我们的模型吗?结果很显然是不能的。
那么,有人可能会说了,既然数据不够,那可以用数据增强(Data Augmentation),在原来图片的基础上来生成多组图片呀。其实啊,这样解决问题还是不行的,为什么不行我们后面再说,解决问题还是要从根源上解决问题。
介绍
为此我们需要提出一种新的神经网络——Siamese Neural Network(孪生神经网络)
听名字,你可能觉得很难,但其实很简单,实现的原理也和cnn卷积神经网络差不多,也是基于cnn卷积神经网络来实现的。大家都知道cnn卷积神经网络训练的时候是输入一张一张的图片和对应的一个一个的标签。当然这是在数据集足够的情况下。那么对于数据集不够的情况我们又将如何去做呢?难道又是一张图片对应一个标签那样的输入吗?当然不是,我们想让训练的时候由少量数据集变多,怎么变呢?我们可以两张两张输入,两张可以由不同的图片组成(可以是同类,可以是不同类),那样我们的数据就会呈现指数级别的增加了,因为不同照片可以实现两两搭配。
那么大家可能会问了:怎么实现将两张图片一起输入到神经网络中呢?怎么让两张图片对应一个标签呢?
我们可以定义一个容器,这个容器可以装两张照片
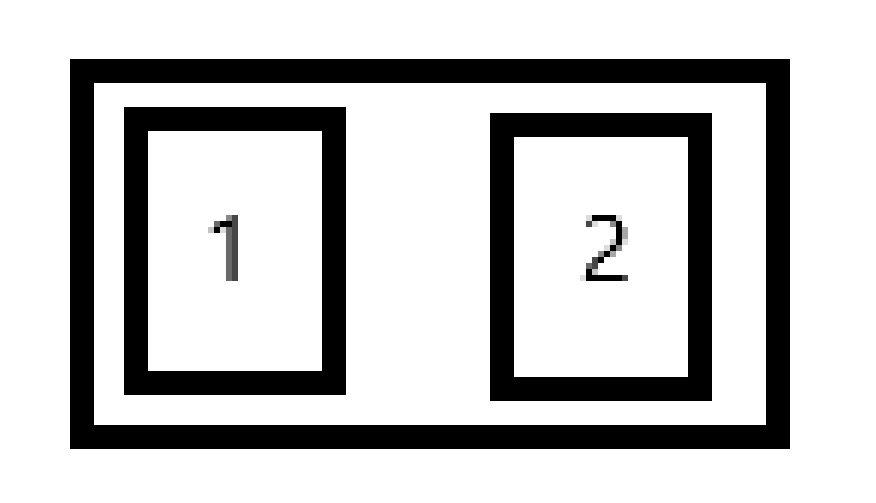
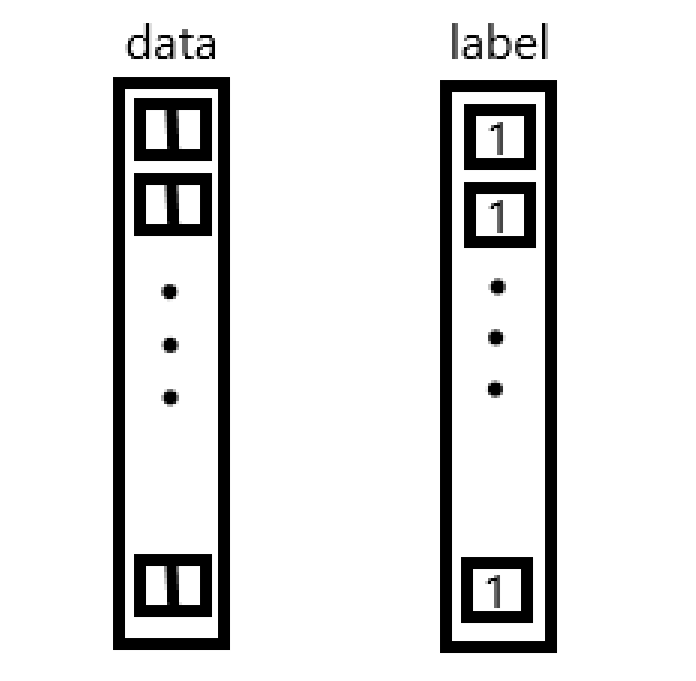
当照片是同类时,标签为1,否则标签为0。
那么我们输入的时候就可以一个容器对应一个标签的来输入的。大致方法跟cnn卷积神经网络差不多。
那怎么进行训练呢?大家都知道:模型应该定义一个损失函数以体现目前的模型好坏,然后不断地调整模型参数以获得最优模型。那孪生神经网络也要有损失函数。那损失函数有点复杂,在这里我就不过多介绍了,后面我会专门出一期文章来介绍。
模型的建立
首先先建立一个大模型(即Siamese神经网络),其输入是一个框(包含两张图片)对应一个标签的方法来输入,在大模型内部建立一个cnn卷积神经网络训练模型(怎么建立可以看我之前的文章),最后再加上一些含有loss函数、optimation函数等训练要用的函数的计算层。这样就建立起了一个Siamese神经网络。
模型的工作原理
具体的工作原理:1、以一个框对应一个标签的方式输入数据到大模型中,然后提取框中的两张图片(img1,img2)。
2、将img1和img2分别放入其中的cnn卷积神经网络,然后分别用vec1和vec2来接收两张图片经过cnn卷积神经网络之后输出的特征向量(即img1和img2分别对于每个类别的得分值向量)
3、计算img1和img2之间的空间距离dist,dist的计算公式为:
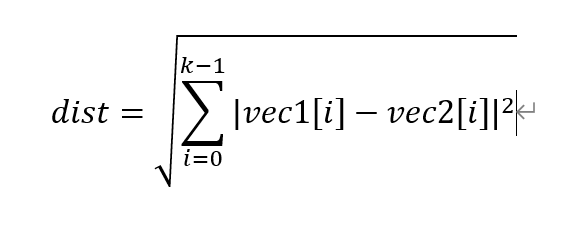
k为向量的长度,loss函数里面会用到dist,模型预测predict中也会用到dist。当然loss函数中不仅仅只有dist,还包括了一系列的参数。
4、开始训练,模型根据loss函数反馈回来的结果,再不断地调整模型的参数,使之成为一个好的模型。
模型的预测
用户输入一张图片,模型从每个类中各取一张图片和用户的图片组合输入到模型当中,跟上面训练过程一样,先计算各自的特征向量vec,再计算它们的dist,看看哪个类的图片和用户图片算出来的dist最小,用户的图片就属于哪个类。
代码
下面我会选取ORL数据集作为本次演示的数据集(大家可以在网上搜,下载就可以了)
import re
import numpy as np
from PIL import Image
from sklearn.model_selection import train_test_split
from tensorflow.keras import backend as K
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Input, Lambda, Dense, Dropout, Convolution2D, MaxPooling2D, Flatten
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.optimizers import RMSprop
def read_image(filename, byteorder='>'):
#first we read the image, as a raw file to the buffer
with open(filename, 'rb') as f:
buffer = f.read()
#using regex, we extract the header, width, height and maxval of the image
header, width, height, maxval = re.search(
b"(^P5\s(?:\s*#.*[\r\n])*"
b"(\d+)\s(?:\s*#.*[\r\n])*"
b"(\d+)\s(?:\s*#.*[\r\n])*"
b"(\d+)\s(?:\s*#.*[\r\n]\s)*)", buffer).groups()
#then we convert the image to numpy array using np.frombuffer which interprets buffer as one dimensional array
return np.frombuffer(buffer,
dtype='u1' if int(maxval) < 256 else byteorder+'u2',
count=int(width)*int(height),
offset=len(header)
).reshape((int(height), int(width)))
Image.open("D:\\42\\orl\\s1\\1.pgm")
img = read_image('D:\\42\\orl\\s1\\1.pgm')
img.shape
size = 2
total_sample_size = 10000
def get_data(size, total_sample_size):
#read the image
image = read_image('D:\\42\\orl\\s' + str(1) + '\\' + str(1) + '.pgm', 'rw+')
#reduce the size
image = image[::size, ::size]
#get the new size
dim1 = image.shape[0]
dim2 = image.shape[1]
count = 0
#initialize the numpy array with the shape of [total_sample, no_of_pairs, dim1, dim2]
x_geuine_pair = np.zeros([total_sample_size, 2, 1, dim1, dim2]) # 2 is for pairs
y_genuine = np.zeros([total_sample_size, 1])
for i in range(40):
for j in range(int(total_sample_size/40)):
ind1 = 0
ind2 = 0
#read images from same directory (genuine pair)
while ind1 == ind2:
ind1 = np.random.randint(10)
ind2 = np.random.randint(10)
# read the two images
img1 = read_image('D:\\42\\orl\\s' + str(i+1) + '\\' + str(ind1 + 1) + '.pgm', 'rw+')
img2 = read_image('D:\\42\\orl\\s' + str(i+1) + '\\' + str(ind2 + 1) + '.pgm', 'rw+')
#reduce the size
img1 = img1[::size, ::size]
img2 = img2[::size, ::size]
#store the images to the initialized numpy array
x_geuine_pair[count, 0, 0, :, :] = img1
x_geuine_pair[count, 1, 0, :, :] = img2
#as we are drawing images from the same directory we assign label as 1. (genuine pair)
y_genuine[count] = 1
count += 1
count = 0
x_imposite_pair = np.zeros([total_sample_size, 2, 1, dim1, dim2])
y_imposite = np.zeros([total_sample_size, 1])
for i in range(int(total_sample_size/10)):
for j in range(10):
#read images from different directory (imposite pair)
while True:
ind1 = np.random.randint(40)
ind2 = np.random.randint(40)
if ind1 != ind2:
break
img1 = read_image('D:\\42\\orl\\s' + str(ind1+1) + '\\' + str(j + 1) + '.pgm', 'rw+')
img2 = read_image('D:\\42\\orl\\s' + str(ind2+1) + '\\' + str(j + 1) + '.pgm', 'rw+')
img1 = img1[::size, ::size]
img2 = img2[::size, ::size]
x_imposite_pair[count, 0, 0, :, :] = img1
x_imposite_pair[count, 1, 0, :, :] = img2
#as we are drawing images from the different directory we assign label as 0. (imposite pair)
y_imposite[count] = 0
count += 1
#now, concatenate, genuine pairs and imposite pair to get the whole data
X = np.concatenate([x_geuine_pair, x_imposite_pair], axis=0)/255
Y = np.concatenate([y_genuine, y_imposite], axis=0)
return X, Y
tt=np.zeros([1,1,1,1,1])
print(tt)
X, Y = get_data(size, total_sample_size)
X.shape
X=X.reshape((20000,2,56,46,1))
X.shape
import matplotlib.pyplot as plt
test=X[0]
test.shape
img1,img2=test
plt.imshow(img1)
plt.show()
print(img1.shape)
plt.imshow(img2)
plt.show()
img2.shape
Y.shape
print(Y)
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=.25)
def build_base_network(input_shape):
model = Sequential()
nb_filter = [6, 12]
kernel_size = 3
#convolutional layer 1
model.add(Convolution2D(nb_filter[0], kernel_size, kernel_size, input_shape=input_shape,padding='valid'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(.25))
#convolutional layer 2
model.add(Convolution2D(nb_filter[1], kernel_size, kernel_size, padding='valid'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(.25))
#flatten
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.1))
model.add(Dense(50, activation='relu'))
return model
input_dim = x_train.shape[2:]
print(input_dim)
img_a = Input(shape=input_dim)
print(img_a)
img_b = Input(shape=input_dim)
print(img_b)
base_network = build_base_network(input_dim)
# base_network相当于model
feat_vecs_a = base_network(img_a) # 分别求两张图片各自的特征向量
print(feat_vecs_a)
feat_vecs_b = base_network(img_b)
print(feat_vecs_b)
def euclidean_distance(vects):
x, y = vects
return K.sqrt(K.sum(K.square(x - y), axis=1, keepdims=True))
def eucl_dist_output_shape(shapes):
shape1, shape2 = shapes
print(shape1)
return (shape1[0], 1)
distance = Lambda(euclidean_distance, output_shape=eucl_dist_output_shape)([feat_vecs_a, feat_vecs_b]) # 求两张图片之间的距离
epochs = 13
rms = RMSprop()
model = Model(inputs=[img_a, img_b], outputs=distance)
def contrastive_loss(y_true, y_pred): # 定义损失函数
margin = 1
return K.mean(y_true * K.square(y_pred) + (1 - y_true) * K.square(K.maximum(margin - y_pred, 0)))
model.compile(loss=contrastive_loss, optimizer=rms)
img_1 = x_train[:, 0]
img2 = x_train[:, 1]
import os
os.environ['CUDA_VISIBLE_DEVICES']='0'
model.fit([img_1, img2], y_train, validation_split=.25,
batch_size=128, verbose=2, epochs=epochs)
pred = model.predict([x_test[:, 0], x_test[:, 1]])
def compute_accuracy(predictions, labels):
return labels[predictions.ravel() < 0.5].mean()
compute_accuracy(pred, y_test) # 求准确率
代码的讲解我会后面再出一篇文章。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号