Java实现十个经典排序算法(带动态效果图)
前言
排序算法是老生常谈的了,但是在面试中也有会被问到,例如有时候,在考察算法能力的时候,不让你写算法,就让你描述一下,某个排序算法的思想以及时间复杂度或空间复杂度。我就遇到过,直接问快排的,所以这次我就总结梳理一下经典的十大排序算法以及它们的模板代码。
算法分析
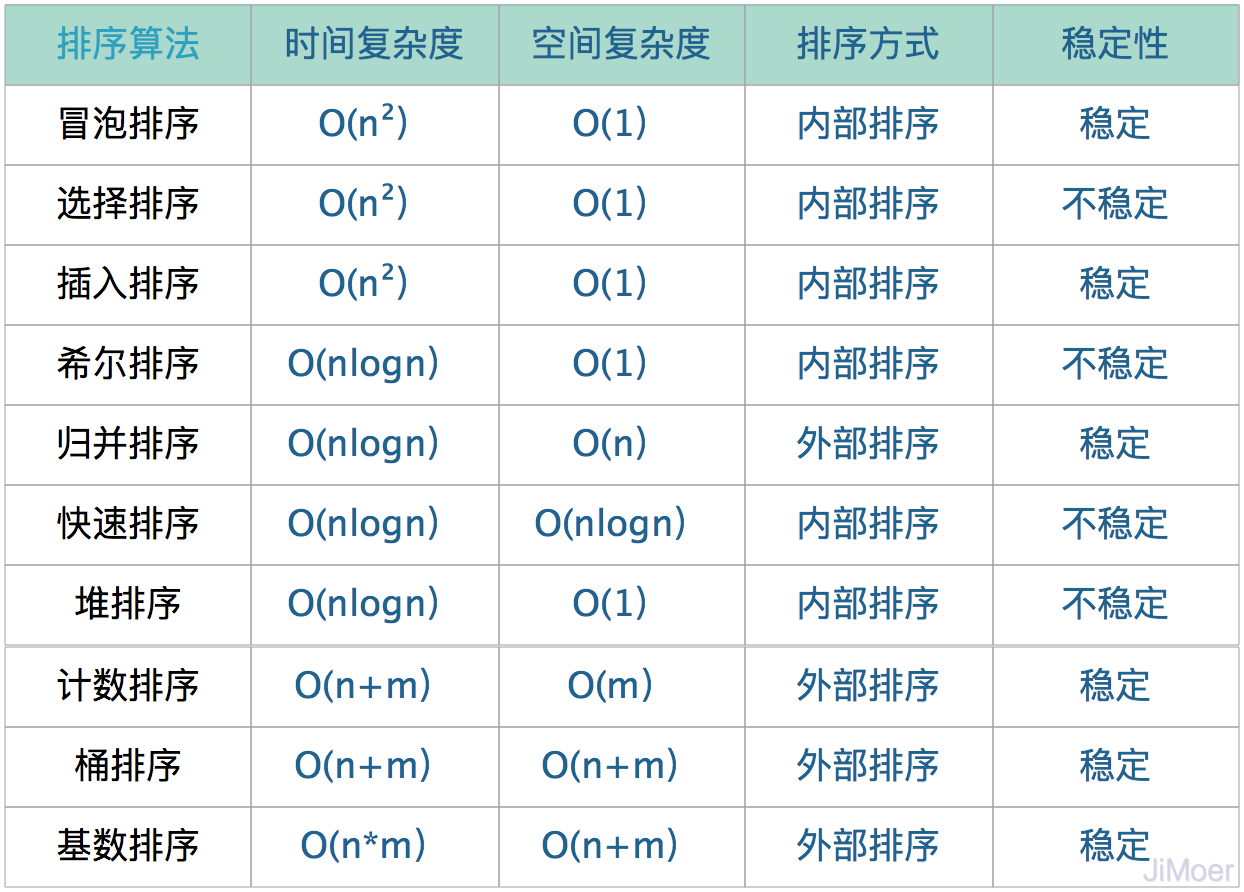
一个排序算法的好坏,一般是通过下面几个关键信息来分析的,下面先介绍一下这几个关键信息,然后再将常见的排序算法的这些关键信息统计出来。
名词介绍
- 时间复杂度:指对数据操作的次数(或是简单的理解为某段代码的执行次数)。举例:O(1):常数时间复杂度;O(log n):对数时间复杂度;O(n):线性时间复杂度。
- 空间复杂度:某段代码每次执行时需要开辟的内存大小。
- 内部排序:不依赖外部的空间,直接在数据内部进行排序;
- 外部排序:数据的排序,不能通过内部空间来完成,需要依赖外部空间。
- 稳定排序:若两个元素相等:a=b,排序前a排在b前面,排序后a仍然在b后面,称为稳定排序。
- 不稳定排序:若两个元素相等:a=b,排序前a排在b前面,排序后a有可能出现在b后面,称为不稳定排序。
常见的排序算法的这几个关键信息如下:
冒泡排序
冒泡排序是一种简单直观的排序算法,它需要多次遍历数据;
主要有这么几步:
- 将相邻的两个元素进行比较,如果前一个元素比后一个元素大那么就交换两个元素的位置,经过这样一次遍历后,最后一个元素就是最大的元素了;
- 然后再将除最后一个元素的剩下的元素,重复执行上面相邻两元素比较的步骤。
- 每次对越来越少的元素重复上面的步骤,直到就剩一个数字需要比较。
这样最终达到整体数据的一个有序性了。
动图演示

代码模板
/**
* 冒泡排序
* @param array
*/
public static void bubbleSort(int[] array){
if(array.length == 0){
return;
}
for(int i=0;i<array.length;i++){
// 每一次都减少i个元素
for(int j=0;j<array.length-1-i;j++){
// 若相邻的两个元素比较后,前一个元素大于后一个元素,则交换位置。
if(array[j]>array[j+1]){
int temp = array[j];
array[j] = array[j+1];
array[j+1] = temp;
}
}
}
}
冒泡排序总结
当数组中的元素已经是正序时,执行效率最高。
当数组中的元素是一个倒序时,执行效率最低,相邻的元素每次比较都需要交换位置。
而且冒泡排序是完全在数据内部进行的,不需要额外的空间,所以空间复杂度是O(1)。
选择排序
选择排序是一种简单粗暴的排序方式,每次都从数据中选出最大或最小的元素,最终选完了,那么选出来的数据就是排好序的了。
主要步骤:
- 先从全部数据中选出最小的元素,放到第一个元素的位置(选出最小元素和第一位位置交换位置);
- 然后再从除了第一个元素的剩余元素中再选出最小的元素,然后放到数组的第二个位置上。
- 循环重复上面的步骤,最终选出来的数据都放前面了,数据就排好序了。
动图演示

代码模板
public static void selectSort(int[] array){
for(int i=0;i<array.length;i++){
// 先以i为最小值的下标
int min = i;
// 然后从后面的数据中找出比array[min] 还小的值,就替换min为当前下标。
for(int j=i+1;j<array.length;j++){
if(array[j]<array[min]){
min = j;
}
}
// 最终如果最小值的下标不等于i了,那么将最小值与i位置的数据替换,即将最小值放到数组前面来,然后循环整个操作。
if(min != i){
int temp = array[i];
array[i] = array[min];
array[min] = temp;
}
}
}
选择排序总结
所有的数据经过选择排序,时间复杂度都是O(n^2);所以需要排序的数据量越小选择排序的效率越高。
插入排序
插入排序也是一种比较直观和容易理解的排序算法,通过构建有序序列,将未排序中的数据插入到已排序中序列,最终未排序全部插入到有序序列,达到排序效果。
主要步骤:
- 将原始数据的第一个元素当成已排序序列,然后将除了第一个元素的后面元素当成未排序序列。
- 从后面未排序元素中从前到后扫描,挨个取出元素,在已排序的序列中从后往前扫描,将从未排序序列中取出的元素插入到已排序序列的指定位置。
- 当未排序元素数量为0时,则排序完成。
动图演示

代码模板
public static void insertSort(int[] array){
// 第一个元素被认为默认有序,所以遍历无序元素从i1开始。
for(int i=1;i<array.length;i++){
int sortItem = array[i];
int j = i;
// 将当前元素插入到前面的有序元素里,将当前元素与前面有序元素从后往前挨个对比,然后将元素插入到指定位置。
while (j>0 && sortItem < array[j-1]){
array[j] = array[j-1];
j--;
}
// 若当前元素在前面已排序里面不是最大的,则将它插入到前面已经确定了位置里。
if(j !=i){
array[j] = sortItem;
}
}
}
插入排序总结
插入排序也是采用的内部排序,所以空间复杂度是O(1),但是时间复杂度就是O(n^2),因为基本上每个元素都要处理多次,需要反复将已排序元素移动,然后将数据插入到指定的位置。
希尔排序
希尔排序是插入排序的一个升级版,它主要是将原先的数据分成若干个子序列,然后将每个子序列进行插入排序,然后每次拆得子序列数量逐次递减,直到拆的子序列的长度等于原数据长度。然后再将数据整体来依次插入排序。
主要步骤:
选择一个增量序列 t1,t2,……,tk,其中 ti > tj, tk = 1;
按增量序列个数 k,对序列进行 k 趟排序;
每趟排序,根据对应的增量 ti,将待排序列分割成若干长度为 m 的子序列,分别对各子表进行直接插入排序。仅增量因子为 1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
过程演示
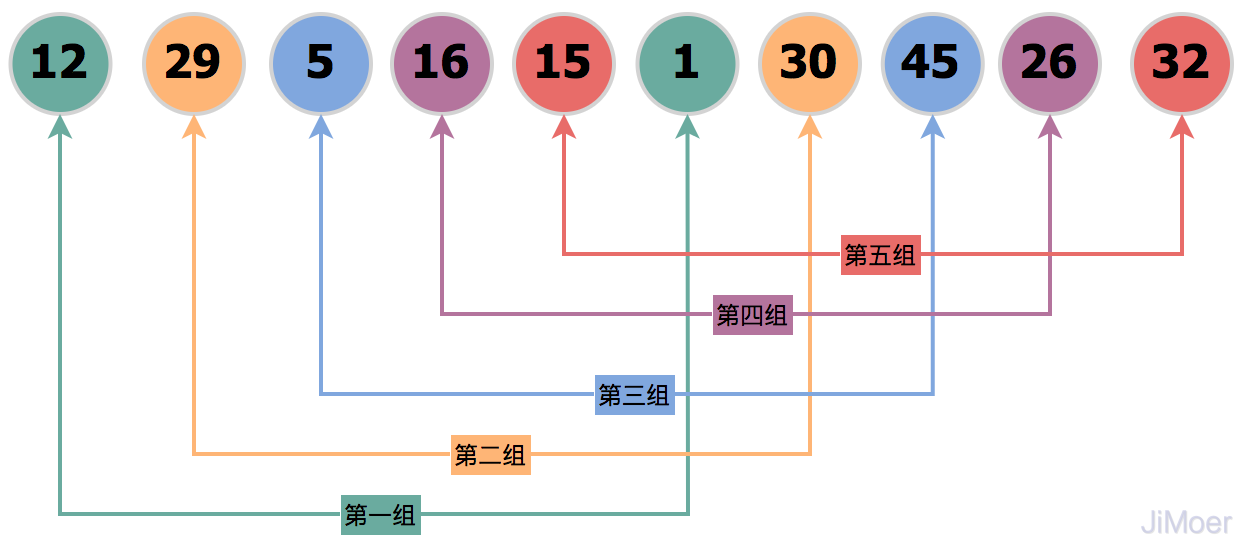
原始未排序的数据。

经过初始增量gap=array.length/2=5分组后,将原数据分为了5组,[12,1]、[29,30]、[5,45]、[16,26]、[15,32]。
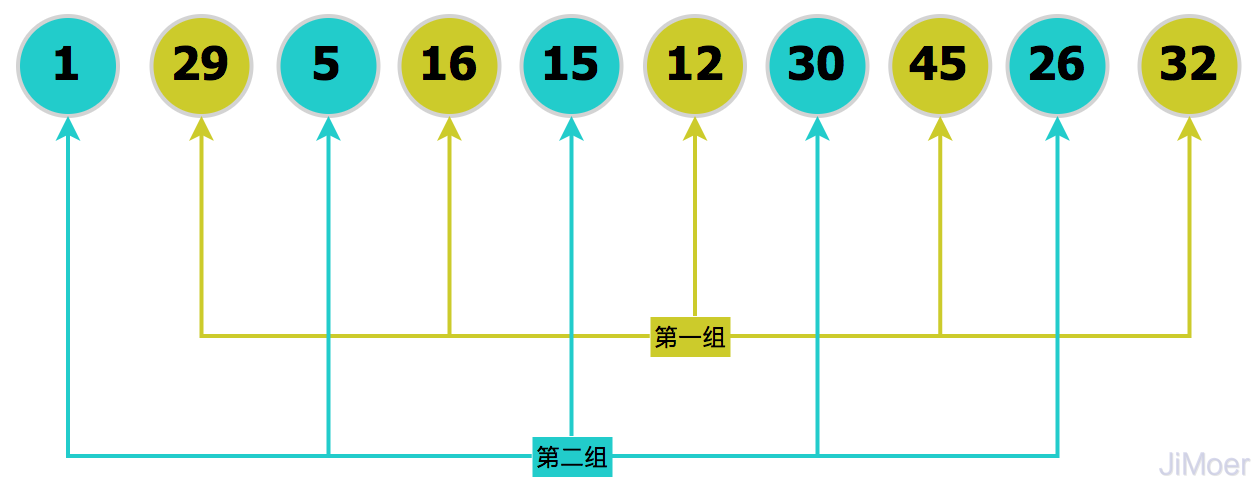
将分组后的数据,每一组数据都直接执行插入排序,这样数据已经慢慢有序起来了,然后再缩小增量gap=5/2=2,将数据分为2组:[1,5,15,30,26]、[29,16,12,45,32]。
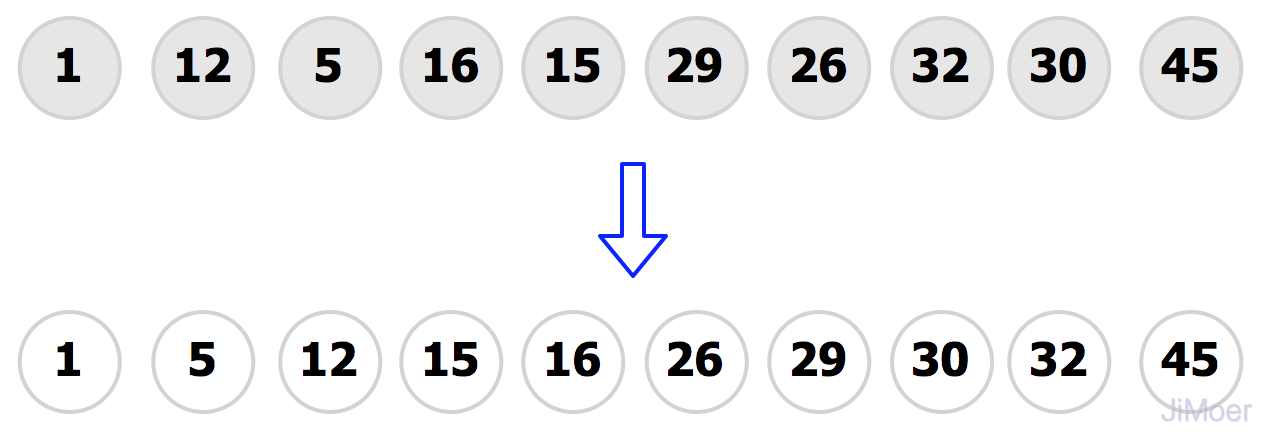
对上面已经分好的两组进行插入排序,整个数据就更加趋向有序了,然后再缩小增量gap=2/2=1,整个数据成为了1组,整个序列作为了表来处理,然后再执行一次插入排序,数据最终达到了有序。
代码模板
/**
* 希尔排序
* @param array
*/
public static void shellSort(int[] array){
int len = array.length;
int temp, gap = len / 2;
while (gap > 0) {
for (int i = gap; i < len; i++) {
temp = array[i];
int preIndex = i - gap;
while (preIndex >= 0 && array[preIndex] > temp) {
array[preIndex + gap] = array[preIndex];
preIndex -= gap;
}
array[preIndex + gap] = temp;
}
gap /= 2;
}
}
归并排序
归并排序是采用的分而治之的递归方式来完成数据排序的,主要是将已有序的两个子序列,合并成一个新的有序子序列。先将子序列分段有序,然后再将分段后的子序列合并成,最终完成数据的排序。
主要步骤:
- 将数据的长度从中间一分为二,分成两个子序列,执行递归操作,直到每个子序列就剩两个元素。
- 然后分别对这些拆好的子序列进行归并排序。
- 将排序好的子序列再两两合并,最终合并成一个完整的排序序列。
动图演示

代码模板
/**
* 归并排序
* @param array 数组
* @param left 0
* @param right array.length-1
*/
public static void mergeSort(int[] array,int left,int right){
if (right <= left){
return;
}
// 一分为二
int mid = (left + right)/2;
// 对前半部分执行归并排序
mergeSort(array, left, mid);
// 对后半部分执行归并排序
mergeSort(array, mid + 1, right);
// 将分好的每个子序列,执行排序加合并操作
merge(array, left, mid, right);
}
/**
* 合并加排序
* @param array
* @param left
* @param middle
* @param right
*/
public static void merge(int[] array,int left,int middle,int right){
// 中间数组
int[] temp = new int[right - left + 1];
int i = left, j = middle + 1, k = 0;
while (i <= middle && j <= right) {
// 若前面数组的元素小,就将前面元素的数据放到中间数组中
if(array[i] <= array[j]){
temp[k++] = array[i++];
}else {
// 若后面数组的元素小,就将后面数组的元素放到中间数组中
temp[k++] = array[j++];
}
}
// 若经过上面的比较合并后,前半部分的数组还有数据,则直接插入中间数组后面
while (i <= middle){
temp[k++] = array[i++];
}
// 若经过上面的比较合并后,后半部分的数组还有数据,则直接插入中间数组后面
while (j <= right){
temp[k++] = array[j++];
}
// 将数据从中间数组中复制回原数组
for (int p = 0; p < temp.length; p++) {
array[left + p] = temp[p];
}
}
归并排序总结
归并排序效率很高,时间复杂度能达到O(nlogn),但是依赖额外的内存空间,而且这种分而治之的思想很值得借鉴,很多场景都是通过简单的功能,组成了复杂的逻辑,所以只要找到可拆分的最小单元,就可以进行分而治之了。
快速排序
快速排序,和二分查找的思想很像,都是先将数据一份为二然后再逐个处理。快速排序也是最常见的排序算法的一种,面试被问到的概率还是比较大的。
主要步骤:
- 从数据中挑选出一个元素,称为 "基准"(pivot),一般选第一个元素或最后一个元素。
- 然后将数据中,所有比基准元素小的都放到基准元素左边,所有比基准元素大的都放到基准元素右边。
- 然后再将基准元素前面的数据集合和后面的数据集合重复执行前面两步骤。
动图演示

代码模板
/**
* 快速排序
* @param array 数组
* @param begin 0
* @param end array.length-1
*/
public static void quickSort(int[] array, int begin, int end) {
if (end <= begin) return;
int pivot = partition(array, begin, end);
quickSort(array, begin, pivot - 1);
quickSort(array, pivot + 1, end);
}
/**
* 分区
* @param array
* @param begin
* @param end
* @return
*/
public static int partition(int[] array, int begin, int end) {
// pivot: 标杆位置,counter: 小于pivot的元素的个数
int pivot = end, counter = begin;
for (int i = begin; i < end; i++) {
if (array[i] < array[pivot]) {
// 替换,将小于标杆位置的数据放到开始位置算起小于标杆数据的第counter位
int temp = array[counter];
array[counter] = array[i];
array[i] = temp;
counter++;
}
}
// 将标杆位置的数据移动到小于标杆位置数据的下一个位。
int temp = array[pivot];
array[pivot] = array[counter];
array[counter] = temp;
return counter;
}
快速排序总结
我找的快速排序的模板代码,是比较巧妙的,选择了最后一个元素作为了基准元素,然后小于基准元素的数量,就是基准元素应该在的位置。这样看起来是有点不好懂,但是看明白之后,就会觉得这个模板写的还是比较有意思的。
堆排序
堆排序其实是采用的堆这种数据结构来完成的排序,一般堆排序的方式都是采用的一种近似完全二叉树来实现的堆的方式完成排序,但是堆的实现方式其实不止有用二叉树的方式,其实还有斐波那契堆。
而根据排序的方向又分为大顶堆和小顶堆:
- 大顶堆:每个节点值都大于或等于子节点的值,在堆排序中用做升序排序。
- 小顶堆:每个节点值都小于或等于子节点的值,在堆排序中用做降序排序。
像Java中的PriorityQueue就是小顶堆。
主要步骤:
- 创建一个二叉堆,参数就是无序序列[0~n];
- 把堆顶元素和堆尾元素互换;
- 调整后的堆顶元素,可能不是最大或最小的值,所以还需要调整此时堆顶元素的到正确的位置,这个调整位置的过程,主要是和二叉树的子元素的值对比后找到正确的位置。
- 重复步骤2、步骤3,直至整个序列的元素都在二叉堆的正确位置上了。
动图演示

模板代码
/**
* 堆排序
* @param array
*/
public static int[] heapSort(int[] array){
int size = array.length;
// 先将数据放入堆中
for (int i = (int) Math.floor(size / 2); i >= 0; i--) {
heapTopMove(array, i, size);
}
// 堆顶位置调整
for(int i = size - 1; i > 0; i--) {
swapNum(array, 0, i);
size--;
heapTopMove(array, 0,size);
}
return array;
}
/**
* 堆顶位置维护
* @param array
* @param i
* @param size
*/
public static void heapTopMove(int[] array,int i,int size){
int left = 2 * i + 1;
int right = 2 * i + 2;
int largest = i;
if (left < size && array[left] > array[largest]) {
largest = left;
}
if (right < size && array[right] > array[largest]) {
largest = right;
}
if (largest != i) {
swapNum(array, i, largest);
heapTopMove(array, largest, size);
}
}
/**
* 比较交换
* @param array
* @param left
* @param right
*/
public static void swapNum(int[] array,int left,int right){
int temp = array[left];
array[left] = array[right];
array[right] = temp;
}
堆排序总结
堆排序的时间复杂度也是O(nlogn),这个也是有一定的概率在面试中被考察到,其实如果真实在面试中遇到后,可以在实现上不用自己去维护一个堆,而是用Java中的PriorityQueue来实现,可以将无序数据集合放入到PriorityQueue中,然后再依次取出堆顶数据,取出堆顶数据时要从堆中移除取出的这个元素,这样每次取出的就都是现有数据中最小的元素了。
计数排序
计数排序是一种线性时间复杂度的排序算法,它主要的逻辑时将数据转化为键存储在额外的数组空间里。计数排序有一定的局限性,它要求输入的数据,必须是有确定范围的整数序列。
主要步骤:
- 找出待排序的数组中最大和最小的元素;
- 统计数组中每个值为i的元素出现的次数,存入数组C的第i项;
- 对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加);
- 反向填充目标数组:将每个元素i放在新数组的第C(i)项,每放一个元素就将C(i)减去1。
动图演示

代码模板
/**
* 计数排序
* @param array
*/
public static void countSort(int[] array){
int bucketLen = getMaxValue(array) + 1;
int[] bucket = new int[bucketLen];
// 统计每个值出现的次数
for (int value : array) {
bucket[value]++;
}
// 反向填充数组
int sortedIndex = 0;
for (int j = 0; j < bucketLen; j++) {
while (bucket[j] > 0) {
array[sortedIndex++] = j;
bucket[j]--;
}
}
}
/**
* 获取最大值
* @param arr
* @return
*/
private static int getMaxValue(int[] arr) {
int maxValue = arr[0];
for (int value : arr) {
if (maxValue < value) {
maxValue = value;
}
}
return maxValue;
}
桶排序
桶排序算是计数排序的一个加强版,它利用特定函数的映射关系,将属于一定范围内的数据,放到一个桶里,然后对每个桶中的数据进行排序,最后再将排序好的数据拼接起来。
主要步骤:
- 设置一个合适长度的数组作为空桶;
- 遍历数据,将数据都放到指定的桶中,分布的越均匀越好;
- 对每个非空的桶里的数据进行排序;
- 将每个桶中排序好的数据拼接在一起。
动图演示

代码模板
/**
* 桶排序
* @param arr
* @param bucketSize
* @return
*/
private static int[] bucketSort(int[] arr, int bucketSize){
if (arr.length == 0) {
return arr;
}
int minValue = arr[0];
int maxValue = arr[0];
// 计算出最大值和最小值
for (int value : arr) {
if (value < minValue) {
minValue = value;
} else if (value > maxValue) {
maxValue = value;
}
}
// 根据桶的长度以及数据的最大值和最小值,计算出桶的数量
int bucketCount = (int) Math.floor((maxValue - minValue) / bucketSize) + 1;
int[][] buckets = new int[bucketCount][0];
// 利用映射函数将数据分配到各个桶中
for (int i = 0; i < arr.length; i++) {
int index = (int) Math.floor((arr[i] - minValue) / bucketSize);
// 将数据填充到指定的桶中
buckets[index] = appendBucket(buckets[index], arr[i]);
}
int arrIndex = 0;
for (int[] bucket : buckets) {
if (bucket.length <= 0) {
continue;
}
// 对每个桶进行排序,这里使用了插入排序
InsertSort.insertSort(bucket);
for (int value : bucket) {
arr[arrIndex++] = value;
}
}
return arr;
}
/**
* 扩容,并追加数据
*
* @param array
* @param value
*/
private static int[] appendBucket(int[] array, int value) {
array = Arrays.copyOf(array, array.length + 1);
array[array.length - 1] = value;
return array;
}
基数排序
基数排序是一种非比较型排序,主要逻辑时将整数按位拆分成不同的数字,然后再按照位数排序,先按低位排序,进行收集,再按高位排序,再进行收集,直到最高位。
主要步骤:
- 获取原始数据中的最大值以及最高位;
- 在原始数组中,从最低位开始取每个位组成基数数组;
- 对基数数组进行计数排序(利用计数排序适用于小范围数的特点);
动图演示

代码模板
/**
* 基数排序
* @param array
*/
public static void radixSort(int[] array){
// 获取最高位
int maxDigit = getMaxDigit(array);
int mod = 10;
int dev = 1;
for (int i = 0; i < maxDigit; i++, dev *= 10, mod *= 10) {
// 考虑负数的情况,这里扩展一倍队列数,其中 [0-9]对应负数,[10-19]对应正数 (bucket + 10)
int[][] counter = new int[mod * 2][0];
// 计数排序
for (int j = 0; j < array.length; j++) {
int bucket = ((array[j] % mod) / dev) + mod;
counter[bucket] = appendBucket(counter[bucket], array[j]);
}
// 反向填充数组
int pos = 0;
for (int[] bucket : counter) {
for (int value : bucket) {
array[pos++] = value;
}
}
}
}
/**
* 获取最高位数
*/
private static int getMaxDigit(int[] arr) {
int maxValue = getMaxValue(arr);
return getNumLength(maxValue);
}
/**
* 获取最大值
* @param arr
* @return
*/
private static int getMaxValue(int[] arr) {
int maxValue = arr[0];
for (int value : arr) {
if (maxValue < value) {
maxValue = value;
}
}
return maxValue;
}
/**
* 获取整数的位数
* @param num
* @return
*/
protected static int getNumLength(long num) {
if (num == 0) {
return 1;
}
int lenght = 0;
for (long temp = num; temp != 0; temp /= 10) {
lenght++;
}
return lenght;
}
/**
* 扩容,并追加数据
*
* @param array
* @param value
*/
private static int[] appendBucket(int[] array, int value) {
array = Arrays.copyOf(array, array.length + 1);
array[array.length - 1] = value;
return array;
}
基数排序总结
计数排序、桶排序、基数排序这三种排序算法都利用了桶的概念,但对桶的使用方法上有明显差异:
- 基数排序:根据键值的每位数字来分配桶;
- 计数排序:每个桶只存储单一键值;
- 桶排序:每个桶存储一定范围的数值;
总结
这次总结了10个经典的排序算法,也算是给自己早年偷的懒补一个补丁吧。一些常用的算法在面试中也算是一个考察方向,但是一般考察都是时间复杂度低的那几个即时间复杂度为O(nlogn)的:快速排序、堆排序、希尔排序。所以这几个要熟练掌握,起码要知道是怎样的实现逻辑(毕竟面试也有口述算法的时候)。
画图:AlgorithmMan


 浙公网安备 33010602011771号
浙公网安备 33010602011771号