Java NIO之理解I/O模型(二)
前言
上一篇文章讲解了I/O模型的一些基本概念,包括同步与异步,阻塞与非阻塞,同步IO与异步IO,阻塞IO与非阻塞IO。这次一起来了解一下现有的几种IO模型,以及高效IO的两种设计模式,也都是属于IO模型的基础知识。
UNIX下可用的五种I/O模型
根据UNIX网络编程对IO模型的分类,UNIX提供了5种IO模型,下面分别来介绍一下。
阻塞I/O模型
最常见的一种IO模型,之前介绍过,一个read操作是分两个阶段的,第一个阶段是,等待数据准备就绪,第二个阶段是将数据拷贝到调用这个IO的线程中。阻塞是发生在第一个阶段的,当数据没有准备好时,会一直阻塞用户线程,当数据就绪后再将数据拷贝到线程中,并返回结果给用户线程。
大致过程如下图。
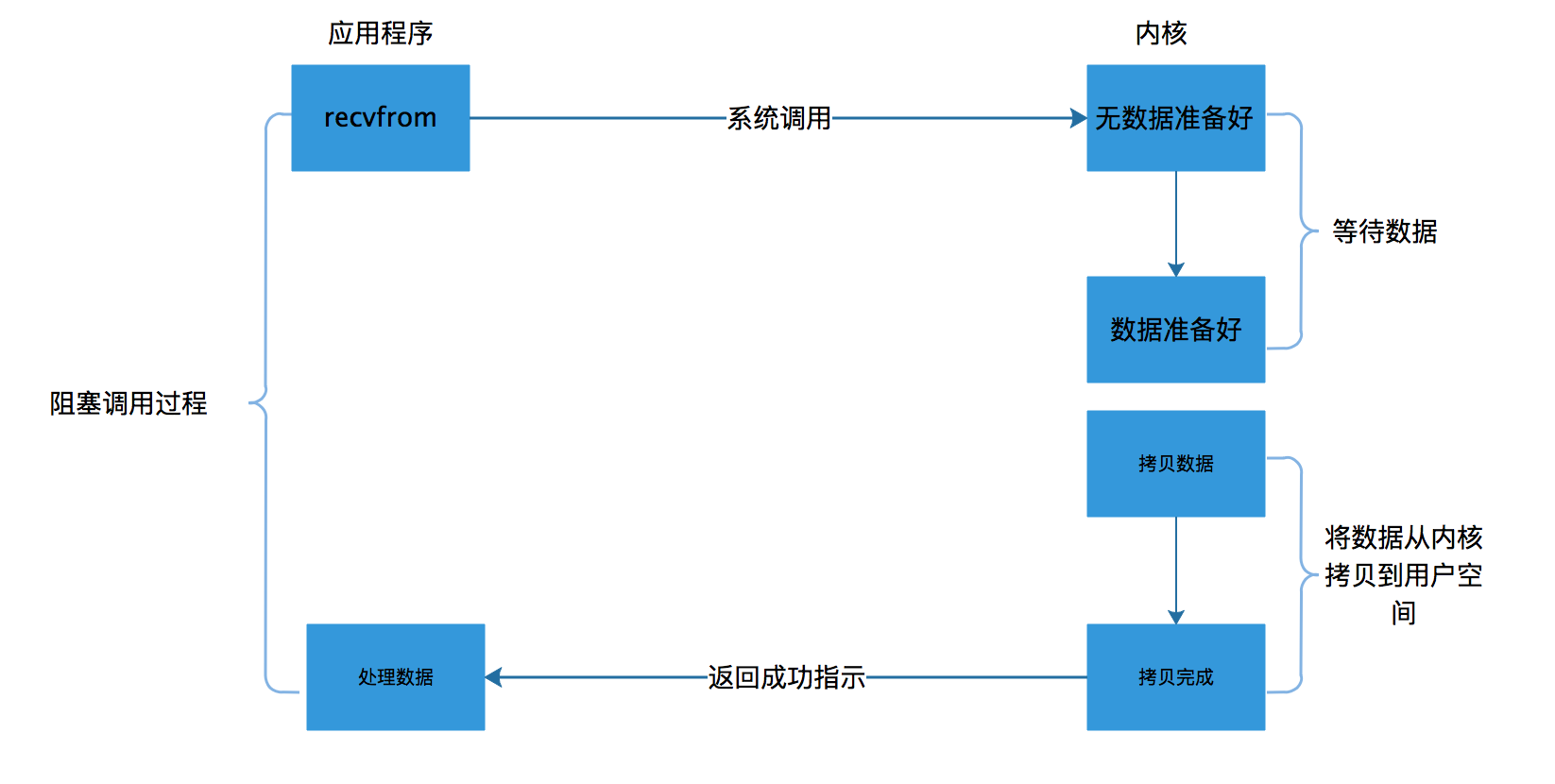
其实,大部分的socket接口都是典型的阻塞型。所谓阻塞型的接口是指系统调用(一般是IO接口)不返回调用结果并让当前线程一直阻塞,只有当该系统调用获得结果或者超时出错时才返回。
通过介绍了阻塞IO,我们很容易就会发现它的问题,那就是阻塞会是用户线程无法进行任何运算和请求。一般我们的处理这种问题的情况是使用多线程,每个链接创建一个线程,或是使用线程池来管理线程,或许可以缓解部分压力,但是不能解决所有问题。多线程模型可以方便高效的解决小规模的服务请求,但面对大规模的服务请求,多线程模型也会遇到瓶颈,可以用非阻塞接口来尝试解决这个问题。
非阻塞I/O模型
非阻塞IO模型是这样一个过程,当应用程序发起一个read操作时,并不会阻塞,而是立刻会收到一个结果。应用程序的线程发现返回结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦数据准备好了,并且又再次收到了用户线程的请求,那么它马上就将数据拷贝到了用户内存,然后返回。
这样的一个过程,其实是需要用户线程不断的去询问系统是否准备好了数据,这样就会一直占用CPU资源。但是这种模型是在只专门提供某种功能的系统才有。
大致过程如下: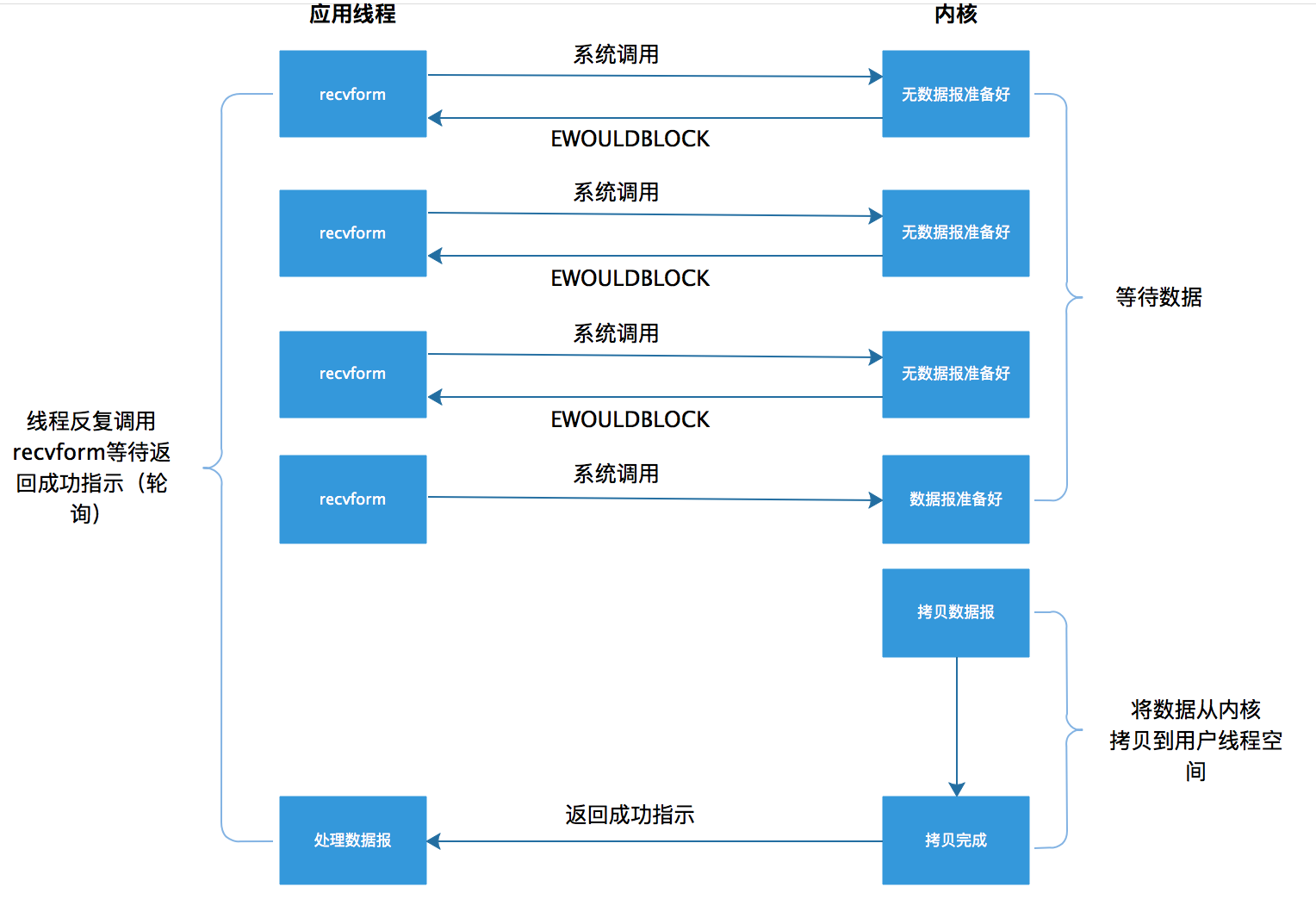
多路I/O复用模型
在介绍多路复用I/O时就要先简单说明一下,select函数和poll函数。
select函数
select函数允许进程指示内核等待多个事件中的任何一个事件发生,并且只在有一个或多个事件发生或经历一段指定的时间后才唤醒它。
- 举个例子,我们可以调用select,告知内核仅在下列情况发生时才返回:
- 集合 {1,4,5} 中的任何描述符准备好读;
- 集合 {2,7} 中的任何描述符准备好写;
- 集合 {1,4} 中的任何描述符有异常条件待处理;
- 已经经历10.2秒;
也就是说,我们调用select告知内核对哪些描述符(读、写或异常条件)感兴趣以及等待多长时间。
poll函数
poll函数起源于SVR3,最初局限于流设备。SVR4取消了这种限制,允许poll工作在任何描述符上。poll函数提供的功能与select函数类似,但是poll没有最大文件描述符数量的限制。
select函数和poll函数将就绪的文件描述符告诉进程后,如果进程没有对其进行IO操作,那么下次调用select函数或者poll函数时会再次报告这些文件描述符, 所以他们一般不会丢失就绪的消息,这种方式称为水平触发(Level Triggered)。
简单的解了select函数和poll函数后,下面我们就继续说多路I/O复用模型。多路IO复用模型就是调用select或poll函数,并且此模型的阻塞过程就是发生在调用这两个函数中的,而不是发生在真正的的I/O系统调用上的,使用select或poll的好处在于可以用单个线程或进程,处理多个网络连接的IO。整个过程就是select或poll函数会不断的轮询所负责的socket,当某个socket有数据到达了,就通知用户线程或进程。
大概调用如下:

Java中的NIO实际上就是使用的多路IO复用模型,通过selector.select()去查询每个通道是否有到达事件,如果没有事件,则一直阻塞在那里,因此多路复用IO模型也会阻塞用户线程,只不过线程是被select函数阻塞的而不是被scoket IO阻塞的。
所以多路复用IO模型和非阻塞IO有类似之处,但是多路复用IO模型的效率是比非阻塞IO模型要高的,因为在非阻塞IO中,不断的询问scoket状态的是通过用户线程去进行的,而多路复用IO模型,轮询每个scoket状态是内核在进行的,这个效率是比用户线程要高很多的。这样也能看出来多路复用IO模型比较适合链接数比较多的情况。
不过此模型也是存在问题的,由于多路复用IO模型是通过轮询的方式来检测是否有事件到达,并对到达的事件逐一响应,一旦事件响应体很大或是响应事件数量过多,就会消耗大量的时间去处理事件,从而影响整个过程的及时性。为了应对这种情况linux系统提供了epoll接口,但是除了linux的其他操作系统对epoll接口的支持又有很多差异,所以虽然epoll解决了事件检测的时效性问题,但是在跨平台能力上却并不能得到很好的支持。
信号驱动IO模型
在信号驱动IO模型中,让内核在数据报准备就绪时发送SIGIO信号通知用户线程。
整个过程如下:

首先开启套接字的信号驱动式IO功能,并通过sigaction系统调用安装一个信号处理函数。该系统调用将立即返回,进程继续工作,也就是说没有被阻塞。当数据报准备好读取时,内核就为该进程产生一个SIGIO信号。我们随后就可以在信号处理函数中调用recvfrom读取数据报,并通知用户进程数据已经准备好了,可以读取了。
这种模型的优点在于等待数据报到达期间不会被阻塞,用户进程可以继续执行,只要等待来自信号处理函数的通知即可。
异步IO模型
异步IO模型的过程是这样的,当用户线程发起read操作时,告知内核启动读取数据操作,并让内核在整个操作(包括将数据从内核复制到我们自己的缓冲区)完成后通知我们。这样在内核执行读取数据操作时,用户线程可以继续执行,当接收到内核在整个操作都完成的信号时,就可以直接去使用数据了。
大致过程如下:
在异步IO模型中,IO操作的两个阶段都不会阻塞用户线程或进程,这两个阶段都是由内核完成的,然后发送一个信号告知用户线程或进程操作已完成。异步IO模型与信号驱动IO模型的区别在于,信号驱动IO模型是由内核通知用户线程何时启动一个IO操作,而异步IO模型是由内核通知我们IO操作何时完成,异步IO模型中用户线程并不需要进行实际的读写操作,只需要在内核操作完成后,接到读取完成信号后,直接使用数据即可。
异步IO是需要操作系统底层支持的,Linux从内核2.6版本才开始支持异步IO。在Java 7中就已经支持异步IO了。
两种高性能IO设计模式Reactor和Proactor
Reactor模式
Reactor的意思是反应器,字面意思就是立即反应。
Reactor的工作方式:
(1)应用程序注册读就绪事件和相关联的事件处理器
(2)Reactor阻塞等待内核事件通知
(3)Reactor收到通知,然后分发可读写事件(读写准备就绪)到用户事件处理函数
(4)用户读取数据,并处理数据
(5)事件处理器完成实际的读操作,处理读到的数据,注册新的事件,然后返还控制权。
大致过程是,每个应用程序宣布它对某个socket感兴趣,然后就需要到Reactor中注册感兴趣事件以及相关的处理函数。当socket发现有事件到达时,就会按顺序对每个事件进行处理(调用处理函数),当所有事件处理完成后,会继续循环这整个操作。
过程如下图所示:

从这个设计模式的处理过程中可以看出,多路IO复用模型就是使用的 Reactor模式,并且这种设计模式还是体现的同步IO。
Proactor模式
Proactor的意思是主动器,主动去完成相应的工作不影响主流程。
Proactor模式的工作方式:
(1)应用程序初始化一个异步读取操作,然后注册相应的事件处理器,此时事件处理器不关注读取就绪事件,而是关注读取完成事件,这是区别于Reactor的关键。
(2)事件分离器等待读取操作完成事件
(3)在事件分离器等待读取操作完成的时候,操作系统调用内核线程完成读取操作,并将读取的内容放入用户传递过来的缓存区中。这也是区别于Reactor的一点,Proactor中,应用程序需要传递缓存区。
(4)事件分离器捕获到读取完成事件后,激活应用程序注册的事件处理器,事件处理器直接从缓存区读取数据,而不需要进行实际的读取操作。
异步IO模型就是使用的Proactor模式。
参考资料:
《Unix网络编程》
https://www.cnblogs.com/dolphin0520/p/3916526.html
https://www.cnblogs.com/findumars/p/6361627.html
http://ifeve.com/io%E6%A8%A1%E5%9E%8B%E8%A7%A3%E6%83%91/


 浙公网安备 33010602011771号
浙公网安备 33010602011771号