有助于改善性能的Java代码技巧
前言
程序的性能受到代码质量的直接影响。这次主要介绍一些代码编写的小技巧和惯例。虽然看起来有些是微不足道的编程技巧,却可能为系统性能带来成倍的提升,因此还是值得关注的。
慎用异常
在Java开发中,经常使用try-catch进行错误捕获,但是try-catch语句对系统性能而言是非常糟糕的。虽然一次try-catch中,无法察觉到她对性能带来的损失,但是一旦try-catch语句被应用于循环或是遍历体内,就会给系统性能带来极大的伤害。
以下是一段将try-catch应用于循环体内的示例代码:
@Test public void test11() { long start = System.currentTimeMillis(); int a = 0; for(int i=0;i<1000000000;i++){ try { a++; }catch (Exception e){ e.printStackTrace(); } } long useTime = System.currentTimeMillis()-start; System.out.println("useTime:"+useTime); }
上面这段代码运行结果是:
useTime:10
下面是一段将try-catch移到循环体外的代码,那么性能就提升了将近一半。如下:
@Test public void test(){ long start = System.currentTimeMillis(); int a = 0; try { for (int i=0;i<1000000000;i++){ a++; } }catch (Exception e){ e.printStackTrace(); } long useTime = System.currentTimeMillis()-start; System.out.println(useTime); }
运行结果:
useTime:6
使用局部变量
调用方法时传递的参数以及在调用中创建的临时变量都保存在栈(Stack)中,速度快。其他变量,如静态变量、实例变量等,都在堆(Heap)中创建,速度较慢。
下面是一段使用局部变量进行计算的代码:
@Test public void test11() { long start = System.currentTimeMillis(); int a = 0; for(int i=0;i<1000000000;i++){ a++; } long useTime = System.currentTimeMillis()-start; System.out.println("useTime:"+useTime); }
运行结果:
useTime:5
将局部变量替换为类的静态变量:
static int aa = 0; @Test public void test(){ long start = System.currentTimeMillis(); for (int i=0;i<1000000000;i++){ aa++; } long useTime = System.currentTimeMillis()-start; System.out.println("useTime:"+useTime); }
运行结果:
useTime:94
通过上面两次的运行结果,可以看出来局部变量的访问速度远远高于类成员变量。
位运算代替乘除法
在所有的运算中,位运算是最为高效的。因此,可以尝试使用位运算代替部分算术运算,来提高系统的运行速度。最典型的就是对于整数的乘除运算优化。
下面是一段使用算术运算的代码:
@Test public void test11() { long start = System.currentTimeMillis(); int a = 0; for(int i=0;i<1000000000;i++){ a*=2; a/=2; } long useTime = System.currentTimeMillis()-start; System.out.println("useTime:"+useTime); }
运行结果:
useTime:1451
将循环体中的乘除运算改为等价的位运算,代码如下:
@Test public void test(){ long start = System.currentTimeMillis(); int aa = 0; for (int i=0;i<1000000000;i++){ aa<<=1; aa>>=1; } long useTime = System.currentTimeMillis()-start; System.out.println("useTime:"+useTime); }
运行结果:
useTime:10
上两段代码执行了完全相同的功能,在每次循环中,都将整数乘以2,并除以2。但是运行结果耗时相差非常大,所以位运算的效率还是显而易见的。
提取表达式
在软件开发过程中,程序员很容易有意无意地让代码做一些“重复劳动”,在大部分情况下,由于计算机的高速运行,这些“重复劳动”并不会对性能构成太大的威胁,但若希望将系统性能发挥到极致,提取这些“重复劳动”相当有意义。
比如以下代码中进行了两次算术计算:
@Test public void testExpression(){ long start = System.currentTimeMillis(); double d = Math.random(); double a = Math.random(); double b = Math.random(); double e = Math.random(); double x,y; for(int i=0;i<10000000;i++){ x = d*a*b/3*4*a; y = e*a*b/3*4*a; } long useTime = System.currentTimeMillis()-start; System.out.println("useTime:"+useTime); }
运行结果:
useTime:21
仔细看能发现,两个计算表达式的后半部分完全相同,这也意味着在每次循环中,相同部分的表达式被重新计算了。
那么改进一下后就变成了下面的样子:
@Test public void testExpression99(){ long start = System.currentTimeMillis(); double d = Math.random(); double a = Math.random(); double b = Math.random(); double e = Math.random(); double p,x,y; for(int i=0;i<10000000;i++){ p = a*b/3*4*a; x = d*p; y = e*p; } long useTime = System.currentTimeMillis()-start; System.out.println("useTime:"+useTime); }
运行结果:
useTime:11
通过运行结果我们可以看出来具体的优化效果。
同理,如果在某循环中需要执行一个耗时操作,而在循环体内,其执行结果总是唯一的,也应该提取到循环体外。
例如下面的代码:
for(int i=0;i<100000;i++){ x[i] = Math.PI*Math.sin(y)*i; }
应该改进成下面的代码:
//提取复杂,固定结果的业务逻辑处理到循环体外 double p = Math.PI*Math.sin(y); for(int i=0;i<100000;i++){ x[i] = p*i; }
使用arrayCopy()
数组复制是一项使用频率很高的功能,JDK中提供了一个高效的API来实现它。
/** * @param src the source array. * @param srcPos starting position in the source array. * @param dest the destination array. * @param destPos starting position in the destination data. * @param length the number of array elements to be copied. * @exception IndexOutOfBoundsException if copying would cause * access of data outside array bounds. * @exception ArrayStoreException if an element in the <code>src</code> * array could not be stored into the <code>dest</code> array * because of a type mismatch. * @exception NullPointerException if either <code>src</code> or * <code>dest</code> is <code>null</code>. */ public static native void arraycopy(Object src, int srcPos, Object dest, int destPos, int length);
如果在应用程序中需要进行数组复制,应该使用这个函数,而不是自己实现。
下面来举例:
@Test public void testArrayCopy(){ int size = 100000; int[] array = new int[size]; int[] arraydest = new int[size]; for(int i=0;i<array.length;i++){ array[i] = i; } long start = System.currentTimeMillis(); for (int k=0;k<1000;k++){ //进行复制 System.arraycopy(array,0,arraydest,0,size); } long useTime = System.currentTimeMillis()-start; System.out.println("useTime:"+useTime); }
运行结果:
useTime:59
相对应地,如果在程序中,自己实现数组复制,其等价代码如下:
@Test public void testArrayCopy99(){ int size = 100000; int[] array = new int[size]; int[] arraydest = new int[size]; for(int i=0;i<array.length;i++){ array[i] = i; } long start = System.currentTimeMillis(); for (int k=0;k<1000;k++){ for(int i=0;i<size;i++){ arraydest[i] = array[i]; } } long useTime = System.currentTimeMillis()-start; System.out.println("useTime:"+useTime); }
运行结果:
useTime:102
通过运行结果可以看出效果。
因为System.arraycopy()函数是native函数,通常native函数的性能要优于普通函数。仅出于性能考虑,在程序开发时,应尽可能调用native函数。
使用Buffer进行I/O操作
除NIO外,使用Java进行I/O操作有两种基本方式;
1、使用基于InpuStream和OutputStream的方式;
2、使用Writer和Reader;
无论使用哪种方式进行文件I/O,如果能合理地使用缓冲,就能有效地提高I/O的性能。
InputStream、OutputStream、Writer和Reader配套使用的缓冲组件。
如下图:
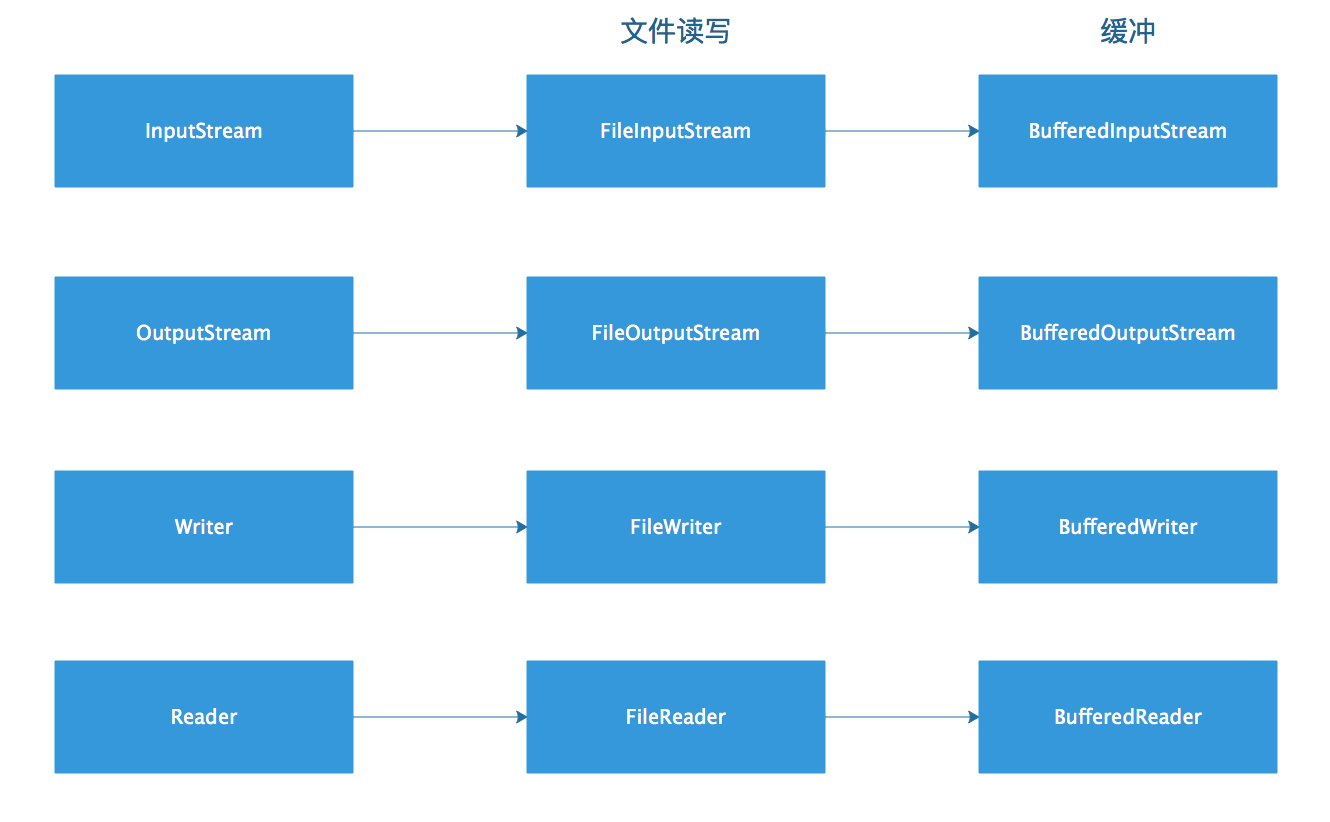
使用缓冲组件对文件I/O进行包装,可以有效提升文件I/O的性能。
下面是一个直接使用InputStream和OutputStream进行文件读写的代码:
@Test public void testOutAndInputStream(){ try { DataOutputStream dataOutputStream = new DataOutputStream(new FileOutputStream("/IdeaProjects/client2/src/test/java/com/client2/cnblogtest/teststream.txt")); long start = System.currentTimeMillis(); for(int i=0;i<10000;i++){ dataOutputStream.writeBytes(Objects.toString(i)+"\r\n"); } dataOutputStream.close(); long useTime = System.currentTimeMillis()-start; System.out.println("写入数据--useTime:"+useTime); //开始读取数据 long startInput = System.currentTimeMillis(); DataInputStream dataInputStream = new DataInputStream(new FileInputStream("/IdeaProjects/client2/src/test/java/com/client2/cnblogtest/teststream.txt")); while (dataInputStream.readLine() != null){ } dataInputStream.close(); long useTimeInput = System.currentTimeMillis()-startInput; System.out.println("读取数据--useTimeInput:"+useTimeInput); }catch (Exception e){ e.printStackTrace(); } }
运行结果:
写入数据--useTime:660
读取数据--useTimeInput:274
使用缓冲的代码如下:
@Test public void testBufferedStream(){ try { DataOutputStream dataOutputStream = new DataOutputStream( new BufferedOutputStream(new FileOutputStream("/IdeaProjects/client2/src/test/java/com/client2/cnblogtest/teststream.txt"))); long start = System.currentTimeMillis(); for(int i=0;i<10000;i++){ dataOutputStream.writeBytes(Objects.toString(i)+"\r\n"); } dataOutputStream.close(); long useTime = System.currentTimeMillis()-start; System.out.println("写入数据--useTime:"+useTime); //开始读取数据 long startInput = System.currentTimeMillis(); DataInputStream dataInputStream = new DataInputStream( new BufferedInputStream(new FileInputStream("/IdeaProjects/client2/src/test/java/com/client2/cnblogtest/teststream.txt"))); while (dataInputStream.readLine() != null){ } dataInputStream.close(); long useTimeInput = System.currentTimeMillis()-startInput; System.out.println("读取数据--useTimeInput:"+useTimeInput); }catch (Exception e){ e.printStackTrace(); } }
运行结果:
写入数据--useTime:22
读取数据--useTimeInput:12
通过运行结果,我们能很明显的看出来使用缓冲的代码,无论在读取还是写入文件上,性能都有了数量级的提升。
使用Wirter和Reader也有类似的效果。
如下代码:
@Test public void testWriterAndReader(){ try { long start = System.currentTimeMillis(); FileWriter fileWriter = new FileWriter("/IdeaProjects/client2/src/test/java/com/client2/cnblogtest/teststream.txt"); for (int i=0;i<100000;i++){ fileWriter.write(Objects.toString(i)+"\r\n"); } fileWriter.close(); long useTime = System.currentTimeMillis()-start; System.out.println("写入数据--useTime:"+useTime); //开始读取数据 long startReader = System.currentTimeMillis(); FileReader fileReader = new FileReader("/IdeaProjects/client2/src/test/java/com/client2/cnblogtest/teststream.txt"); while (fileReader.read() != -1){ } fileReader.close(); long useTimeInput = System.currentTimeMillis()-startReader; System.out.println("读取数据--useTimeInput:"+useTimeInput); }catch (Exception e){ e.printStackTrace(); } }
运行结果:
写入数据--useTime:221
读取数据--useTimeInput:147
对应的使用缓冲的代码:
@Test public void testBufferedWriterAndReader(){ try { long start = System.currentTimeMillis(); BufferedWriter fileWriter = new BufferedWriter( new FileWriter("/IdeaProjects/client2/src/test/java/com/client2/cnblogtest/teststream.txt")); for (int i=0;i<100000;i++){ fileWriter.write(Objects.toString(i)+"\r\n"); } fileWriter.close(); long useTime = System.currentTimeMillis()-start; System.out.println("写入数据--useTime:"+useTime); //开始读取数据 long startReader = System.currentTimeMillis(); BufferedReader fileReader = new BufferedReader( new FileReader("/IdeaProjects/client2/src/test/java/com/client2/cnblogtest/teststream.txt")); while (fileReader.read() != -1){ } fileReader.close(); long useTimeInput = System.currentTimeMillis()-startReader; System.out.println("读取数据--useTimeInput:"+useTimeInput); }catch (Exception e){ e.printStackTrace(); } }
运行结果:
写入数据--useTime:157
读取数据--useTimeInput:59
通过运行结果可以看出,使用了缓冲后,无论是FileReader还是FileWriter的性能都有较为明显的提升。
在上面的例子中,由于FileReader和FilerWriter的性能要优于直接使用FileInputStream和FileOutputStream所以循环次数增加了10倍。
后面会持续更新。。。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号