《redis深度历险》八(字符串和字典)
字符串
SDS(Simple Dynamic String)是一个带长度信息的字节数组
struct SDS<T> {
T capacity; // 数组容量
T len; // 数组长度
byte flags; // 特殊标识
byte[] content; // 数组内容
}
content里存储了真正的字符串内容,类似于Java的ArrayList结构,需要比实际内容长度多分配一些冗余空间,capacity表示所分配数组的长度,len表示字符串的实际长度。字符串是可以修改的,要支持append操作,如果数组没有冗余空间,那么追加操作必然涉及到分配新数组,将旧内容复制,append新内容,如果字符串长度很长,这样分配和复制开销就会很大。
/* Append the specified binary-safe string pointed by 't' of 'len' bytes to the * end of the specified sds string 's'.
*
* After the call, the passed sds string is no longer valid and all the
* references must be substituted with the new pointer returned by the call. */ sds sdscatlen(sds s, const void *t, size_t len) {
size_t curlen = sdslen(s); // 原字符串长度
// 按需调整空间,如果 capacity 不够容纳追加的内容,就会重新分配字节数组并复制原字 符串的内容到新数组中
s = sdsMakeRoomFor(s,len);
if (s == NULL) return NULL; // 内存不足
memcpy(s+curlen, t, len); // 追加目标字符串的内容到字节数组中
sdssetlen(s, curlen+len); // 设置追加后的长度值
s[curlen+len] = '\0'; // 让字符串以\0 结尾,便于调试打印,还可以直接使用 glibc 的字符串
函数进行操作
return s; }
为什么使用泛型T而不使用int,因为字符串较短时,len和capacity可以用byte和short表示,对内存做了极致优化,不同长度的字符串可以使用不同的结构体表示。
redis规定字符串的长度不得超过512M,创建字符串时,len和capacity一样长,不会分配冗余空间,因为绝大多数场景不会修改字符串。
embstr vs raw
127.0.0.1:6379> set str abcdefghijklmnopqrstuvwxyz012345678912345678
OK
127.0.0.1:6379> debug object str
Value at:0x7fb20e50d8d0 refcount:1 encoding:embstr serializedlength:45 lru:11843071 lru_seconds_idle:8
127.0.0.1:6379> set codehole abcdefghijklmnopqrstuvwxyz0123456789123456789
OK
127.0.0.1:6379> debug object codehole
Value at:0x7fb20f90b690 refcount:1 encoding:raw serializedlength:46 lru:11843088 lru_seconds_idle:5
所有的redis对象都有下面这个结构头
struct RedisObject {
int4 type; // 4bits
int4 encoding; // 4bits
int24 lru; // 24bits
int32 refcount; // 4bytes
void *ptr; // 8bytes,64-bit system
} robj;
不同的对象具有不同的类型 type(4bit),同一个类型的 type 会有不同的存储形式 encoding(4bit),为了记录对象的 LRU 信息,使用了 24 个 bit 来记录 LRU 信息。每个对 象都有个引用计数,当引用计数为零时,对象就会被销毁,内存被回收。ptr 指针将指向对 象内容 (body) 的具体存储位置。这样一个 RedisObject 对象头需要占据 16 字节的存储空 间。
SDS对象头最少时19(16+3)字节
struct SDS {
int8 capacity; // 1byte
int8 len; // 1byte
int8 flags; // 1byte
byte[] content; // 内联数组,长度为 capacity
}
而内存分配器 jemalloc/tcmalloc 等分配内存大小的单位都是 2、4、8、16、32、64 等 等,为了能容纳一个完整的 embstr 对象,jemalloc 最少会分配 32 字节的空间,如果字符 串再稍微长一点,那就是 64 字节的空间。如果总体超出了 64 字节,Redis 认为它是一个 大字符串,不再使用 emdstr 形式存储,而该用 raw 形式。
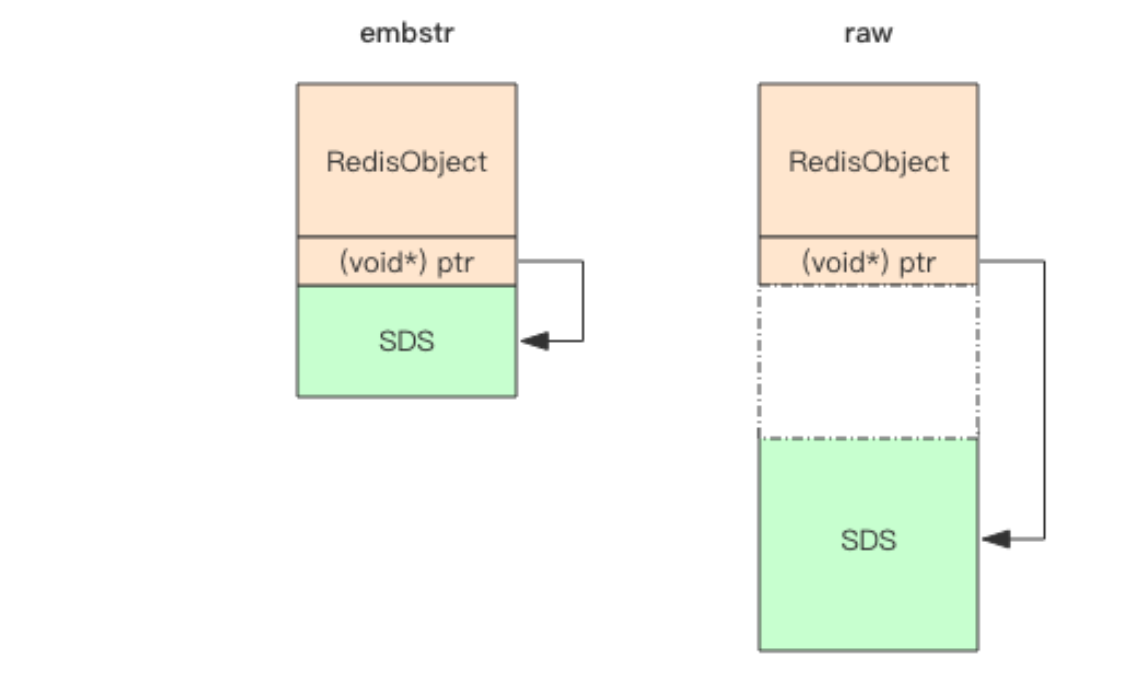
SDS 结构体中的 content 中的字符串是以字节\0 结尾的字符串,之所以 多出这样一个字节,是为了便于直接使用 glibc 的字符串处理函数,以及为了便于字符串的 调试打印输出。
看上面这张图可以算出,留给 content 的长度最多只有 45(64-19) 字节了。字符串又是
以\0 结尾,所以 embstr 最大能容纳的字符串长度就是 44。
扩容策略
字符串在长度小于 1M 之前,扩容空间采用加倍策略,也就是保留 100% 的冗余空 间。当长度超过 1M 之后,为了避免加倍后的冗余空间过大而导致浪费,每次扩容只会多分 配 1M 大小的冗余空间。
字典
dict内部结构
dict结构内层包含两个hashtable,通常只有一个hashtable有值,但是在dict扩容缩容时,需要分配新的hashtable,然后进行渐进式搬迁,搬迁完毕后,旧的hashtable被删除。

hashtable几乎和java重的hashmap数据结构一样,数组+链表。
查找过程
元素是在第二维的链表上,首先找出元素对应的链表。
func get(key){
let index = hash_func(key)%size;
let entry = table[index];
while(entry != null){
if entry.key = target{
return entry.value;
}
entry = entry.next;
}
}
hash_func,会将key映射为一个整数,不同的key会被映射成分布均匀的散乱整数,只有hash值均匀了,整个hashtable才是平衡的,所有的二维链表的长度就不会差很远,比较稳定。
扩容条件
正常情况下,当 hash 表中元素的个数等于第一维数组的长度时,就会开始扩容,扩容 的新数组是原数组大小的 2 倍。不过如果 Redis 正在做 bgsave,为了减少内存页的过多分 离 (Copy On Write),Redis 尽量不去扩容 (dict_can_resize),但是如果 hash 表已经非常满 了,元素的个数已经达到了第一维数组长度的 5 倍 (dict_force_resize_ratio),说明 hash 表 已经过于拥挤了,这个时候就会强制扩容。
缩容条件
当 hash 表因为元素的逐渐删除变得越来越稀疏时,Redis 会对 hash 表进行缩容来减少
hash 表的第一维数组空间占用。缩容的条件是元素个数低于数组长度的 10%。缩容不会考 虑 Redis 是否正在做 bgsave。
集合
Redis里面set的的结构底层实现也是字典,只不过所有的value都是null,其他特性和字典一样。
127.0.0.1:6379> sadd country china japan usa
(integer) 3
127.0.0.1:6379> debug object country
Value at:0x7fb20e60d3f0 refcount:1 encoding:hashtable serializedlength:17 lru:12015767 lru_seconds_idle:9
