《Redis深度历险》五(持久化和线程IO模型)
GeoHash
增加
geoadd指令携带集合名称以及多个经纬度名称三元组,这里可以加入多个三元组。
127.0.0.1:6379> geoadd company 116.48105 39.996764 mike
(integer) 1
127.0.0.1:6379> geoadd company 116.2323 39.992424 jack
(integer) 1
127.0.0.1:6379> geoadd company 116.44243 39.32324 kobe 116.88854 44.32324 ben
(integer) 2
Geo存储结构上使用的是zset,可以使用zset相关的指令来操作GEO,所以元素删除指令可以直接使用zrem。
距离
geodist 指令可以用来计算两个元素之间的距离,携带集合名称,两个名称和距离单位。
127.0.0.1:6379> GEODIST company mike kobe km
"74.9865"
距离单位可以是m, km, ml(英里), ft(尺)
获取元素位置
geopos指令可以获取集合中任意元素的经纬度坐标,可一次获取多个
127.0.0.1:6379> geopos company kobe
1) 1) "116.44243150949478149"
2) "39.32323950019029724"
获取元素的hash值
可以获取元素的经纬度编码字符串,是一个base32编码
127.0.0.1:6379> geohash company kobe
1) "wwfz9wwf3r0"
附近的元素
georadiusbymember,用来查询指定元素附近的其他元素
- 范围900公里以内最多3个元素按距离正排,不会排除自身
127.0.0.1:6379> GEORADIUSBYMEMBER company kobe 900 km count 3 asc
1) "kobe"
2) "mike"
3) "jack"
-
withdis可以显示距离
127.0.0.1:6379> GEORADIUSBYMEMBER company kobe 900 km withcoord withdist withhash count 3 asc 1) 1) "kobe" 2) "0.0000" 3) (integer) 4069130657920200 4) 1) "116.44243150949478149" 2) "39.32323950019029724" 2) 1) "mike" 2) "74.9865" 3) (integer) 4069887154387415 4) 1) "116.48104995489120483" 2) "39.99676307192869018" 3) 1) "jack" 2) "76.5748" 3) (integer) 4069880183825535 4) 1) "116.23230189085006714" 2) "39.99242362930389305" 127.0.0.1:6379>
根据坐标值来查询附近的元素的指令georadius,可以根据用户的定位来计算附近的车,附近的餐馆。参数和georadiusbymember基本一致,唯一差别是将目标元素改为经纬度坐标。
127.0.0.1:6379> GEORADIUS company 116.55555 39.4433 100 km withdist count 3 asc
1) 1) "kobe"
2) "16.5195"
2) 1) "mike"
2) "61.8887"
3) 1) "jack"
2) "67.0463"
注意事项
如果几百万条数据放在一个zset中,单个key数据过大,会对集群的迁移工作造成影响,在鸡群中单个key对应的数据量不宜超过1mb,否则会导致集群迁移卡顿现象。建议geo的数据使用单独的redis实例部署,不使用集群环境。
如果数据量过亿,需要对geo进行拆分,按国家,按省,市,区分。以此来降低单个zset集合的大小。
SCAN
从redis实例的上千万key中找出特定前缀的key
keys *
keys code*
keys code*aaa
缺点:
- 没有offset,limit参数,一次性取出所有的。
- keys采用遍历算法,复杂度是On,因为redis是单线程,所以其他指令要等待遍历结束才可以继续使用。
scan特点
- 复杂度也是On,但是通过游标分布进行,不会阻塞线程。
- 提供limit参数
- 同keys一样,提供模式匹配功能。
- 服务器不需要为游标保存状态,唯一状态就是scan返回给客户端的游标整数。
- 返回的结果可能会有重复,需要用户端去重
- 遍历的过程中如果有数据修改,改动后的数据不能遍历到是不确定的
- 单词返回的结果是空并不意味遍历结束,而是看游标值是否为0
scan 0 match key* count 100
第一个参数是cursor的整数值,第二个是key的正则,第三个是遍历的limit。
第一次遍历时,cursor为0,然后返回结果中第一个整数值作为下一次的cursor,直到返回的cursor为0结束。
limit虽然定义的是100,但是返回的没有100,这是limit不限定返回结果的数量,而是限定服务器单词遍历的字典槽位数量,如果将limit设置为10,会发现结果是空的,但是游标不为0,意味着遍历没有结束。
字典结构
redis的key存储在很大的字典中,结构和java中的hashmap一样,是一对数组-链表结构。每次扩容,大小空间加倍。
scan返回的游标是第一位数组的位置索引,称为曹(slot),如果不考虑字典扩容,直接按数组下标挨个遍历,limit表示需要遍历的槽位数,之所以会返回不同的结果个数,是因为每个槽位都会挂接链表,有些是空的,所以每次遍历都会将limit数量的槽位上挂接所有的链表元素进行模式匹配过滤后,一次性返回。
遍历顺序(重要)
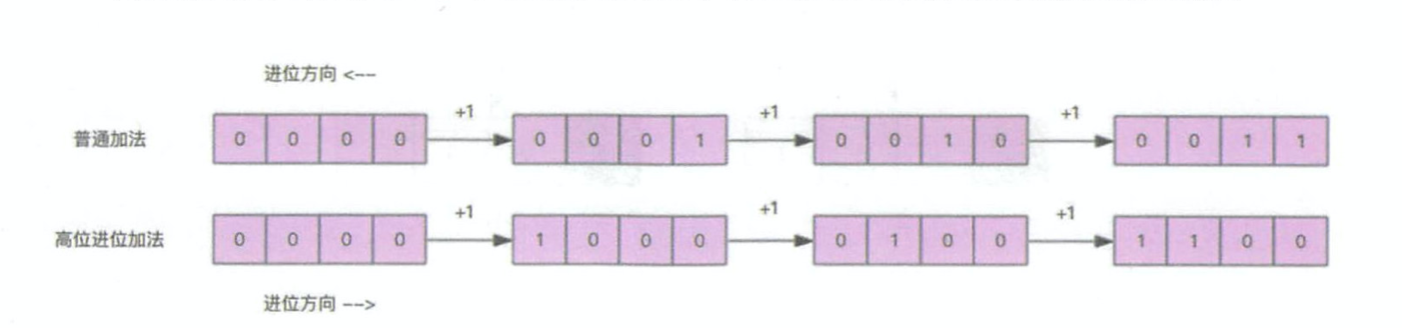
scan是采用了高位进位加法遍历,原因和字典扩容有关。
字典扩容(重要)
当需要扩容时,将所有元素全部rehash挂载到新数组下面,rehash就是将元素的hash值对数组长度进行取模运算,因为长度变了,所以每个元素挂接的槽位可能也发生了变化。又因为数组的长度是2的n次方,所以取模运算等价于位与操作。
a mode 8 = a & (8-1) = a & 7
这里的7被称为字典的mask值,作用是保留hash值的低位,高位设为0.
例如:当前字典的数组长度由8扩容到16,那么3号槽位011将会被rehash到3号和11号,也就是说该槽位链表中大约有一半的元素还是3号槽位,其他元素会放到11号。3号槽位(0011)11号槽位(1011)
假设要遍历110这个位置,扩容后当前位置所有元素对应的槽位是0110和1110,也就是在二进制数增加了一个高位0或1,这是可以从0110这个位置继续高位往后遍历,之前的是遍历过的,所以可以避免进行重复遍历。
结论:扩容或缩容和rehash有关,会从高位增0增1或补0补1,如果用普通加法,遍历过的槽位,扩容后会再次遍历。但是用高位进位加法就会忽略扩容影响。缩容也不会产生影响。
拓展
zscan对zset遍历集合元素,hscan遍历hash字典元素,sscan遍历set集合元素。
大key扫描
过大的redis对象比如key或hash,zset,导致迁移时卡顿,内存分配上如果一个key太大,需要扩容时申请内存会导致卡顿,被删除内存回收也会卡顿。所以尽量避免大key的产生。
定位大key
redis-cli -h 127.0.0.1 -p 7001 --bigkeys [-i 0.1]
这个指令会抬升redis的ops导致报警,可以增加一个休眠参数0.1,每100条scan休眠0.1s,防止reids的ops剧烈抬升。
线程IO模型
非阻塞IO
调用套接字的读写方法,默认是阻塞的,比如read方法要传递一个参数n,表示读取这么多字节后再返回,如果没有读够线程就会卡在那里,知道新数据到来,或者连接关闭,read方法才可以返回,线程才能继续处理。而write方法一般不会阻塞,除非内核为套接字分配的缓冲区写满了,才会阻塞,直到缓存区种有空闲空间挪出来。
非阻塞IO再套接字上加了一个选项NoBlocking,当这个选项打开时,读写方 法不会阻塞,而是能读多少读多少,能写多少写多少。能读多少取决于内核为套接字分配的 读缓冲区内部的数据字节数,能写多少取决于内核为套接字分配的写缓冲区的空闲空间字节数。读方法和写方法都会通过返回值来告知程序实际读写了多少字节。
有了非阻塞 IO 意味着线程在读写 IO 时可以不必再阻塞了,读写可以瞬间完成然后线 程可以继续干别的事了。
事件轮询
非阻塞IO有个问题,线程读数据,读了一部分就返回,如何知道继续读。写也是一样,写满了,剩下的数据何时才应该继续写。
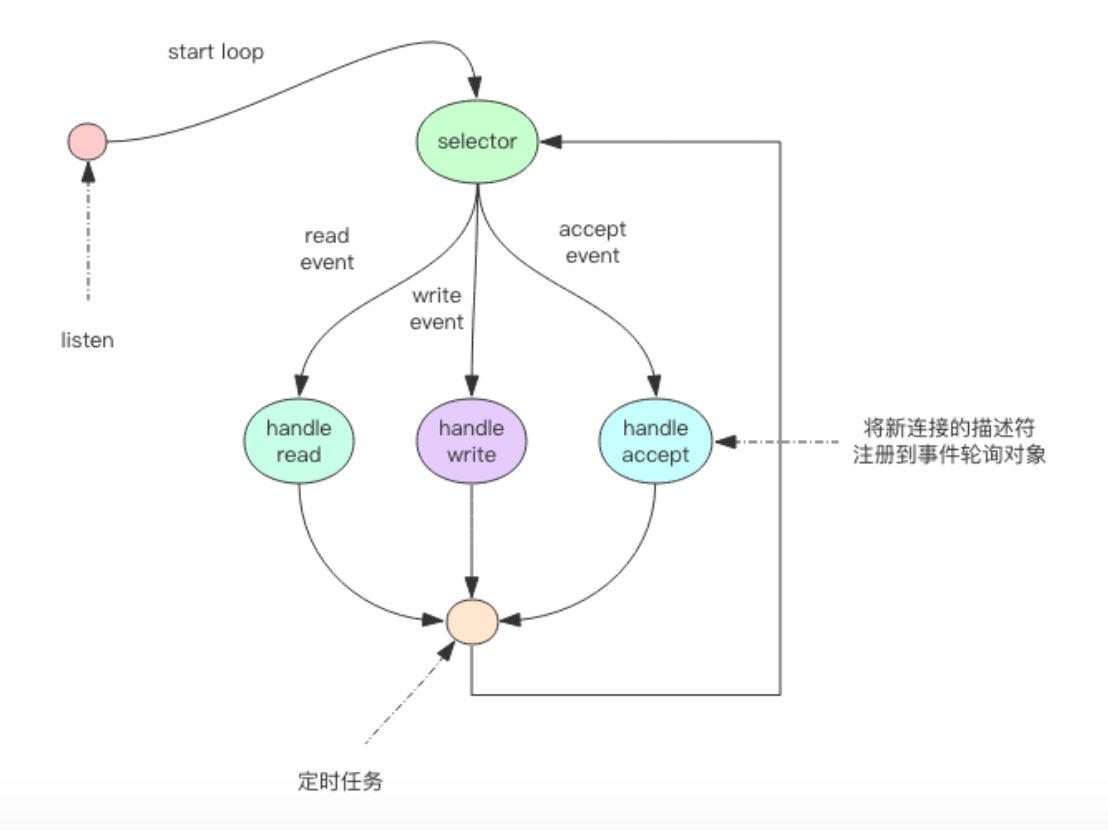
最简单的事件轮询 API 是 select 函数,它是 操作系统提供给用户程序的 API。输入是读写描述符列表 read_fds & write_fds,输出是与之 对应的可读可写事件。同时还提供了一个 timeout 参数,如果没有任何事件到来,那么就最多等待 timeout 时间,线程处于阻塞状态。一旦期间有任何事件到来,就可以立即返回。时间过 了之后还是没有任何事件到来,也会立即返回。拿到事件后,线程就可以继续挨个处理相应 的事件。处理完了继续过来轮询。于是线程就进入了一个死循环,我们把这个死循环称为事 件循环,一个循环为一个周期。
伪代码
read_events, write_events = select(read_fds, write_fds, timeout) for event in read_events:
handle_read(event.fd) for event in write_events:
handle_write(event.fd)
handle_others() # 处理其它事情,如定时任务等
API。现代操作系统的多路复用 API 已经不再使用 select 系统调用,而 改用 epoll(linux)和 kqueue(freebsd & macosx),因为 select 系统调用的性能在描述符特别多时性能会非常差。
事件轮询 API 就是 Java 语言里面的 NIO 技术
指令队列
Redis 会将每个客户端套接字都关联一个指令队列。客户端的指令通过队列来排队进行顺序处理,先到先服务。
响应队列
Redis 同样也会为每个客户端套接字关联一个响应队列。Redis 服务器通过响应队列来将 指令的返回结果回复给客户端。 如果队列为空,那么意味着连接暂时处于空闲状态,不需要去获取写事件,也就是可以将当前的客户端描述符从 write_fds 里面移出来。等到队列有数据 了,再将描述符放进去。避免 select 系统调用立即返回写事件,结果发现没什么数据可以 写。出这种情况的线程会飙高 CPU。
定时任务
如果线程阻塞在select系统调用上,定时任务无法得到准时调度。
Redis 的定时任务会记录在一个称为最小堆的数据结构中。这个堆中,最快要执行的任 务排在堆的最上方。在每个循环周期,Redis 都会将最小堆里面已经到点的任务立即进行处 理。处理完毕后,将最快要执行的任务还需要的时间记录下来,这个时间就是 select 系统调 用的 timeout 参数。因为 Redis 知道未来 timeout 时间内,没有其它定时任务需要处理,所以 可以安心睡眠 timeout 的时间。
持久化
两种机制,第一种是快照,第二种是AOF日志。快照是一次全量备份,aof是连续的增量备份。快照是内存数据的二进制序列化形式,存储上非常紧凑,AOF记录的是内存数据修改的指令记录文本。AOF在长期运行中会很庞大,重启时需要加载AOF日志重放,时间很长,需要对AOF进行重写,给AOF瘦身。
快照原理(RDB)
redis单线程,在服务线上的请求同时,还要进行文件IO操作。还有个问题是为了不阻塞线上的业务,需要边持久化边处理线上的请求。持久化的同时,内存数据结构还在改变,比如一个大型的hash字典正在持久化,结果另一个请求删除,如何处理。
fork(多进程)
Redis 在持久化时会调用 glibc 的函数 fork 产生一个子进程,快照持久化完全交给子进 程来处理,父进程继续处理客户端请求。
拿python伪代码为例
pid = os.fork()
if pid > 0:
handle_client_request() # 父进程处理客户端请求
if pid == 0:
handle_snapshot_write()
if pid < 0:
# error
子进程做数据持久化,并不会修改内存数据结构,只是对数据结构进行遍历读取,然后序列化写到磁盘。父进程必须持续服务客户端请求,然后对内存数据结构进行不间断的修改。
此时,会用操作系统的COW(copy on write)机制来进行数据段页面的分离。数据段是由很多操作系统的页面组合而成,当父进程对其中一个页面的数据进行修改,会把被共享的页面复制一份分离出来,然后对这个复制的页面进行修改。此时子进程相应的页面没有变化。还是进程产生时那一瞬间的数据。
父进程修改的进行,越来越多的共享页面被分离,内存就会持续增长。另外一个redis实例里冷数据占的比例往往比较高,很少会出现所有的页面都被分离。
子进程因为数据没有变化,能看到内存里的数据在进程产生的一瞬间就凝固,这就是redis的持久化叫快照的原因,接下来子进程就可以安心遍历数据进行序列化写磁盘了。
AOF原理
假设 AOF 日志记录了自 Redis 实例创建以来所有的修改性指令序列,那么就可以通过 对一个空的 Redis 实例顺序执行所有的指令,也就是「重放」,来恢复 Redis 当前实例的内 存数据结构的状态。
AOF重写
redis提供了bgrewriteaof指令用于对AOF进行瘦身,原理是开辟一个子进程对内存进行遍历,转换为一系列redis操作指令,序列化到一个新的AOF日志文件中,序列化完毕后,将增量AOF日志追加到AOF日志文件中,代替旧的AOF日志。
特点
- 快照遍历整个内存,大块写磁盘会加重系统负载。
- AOF的fsync是一个耗时IO操作,会降低Redis操作,也会增加系统负担。
混合持久化
将rdb文件的内容和增量的AOF日志存在一起,这时的AOF不再是全量日志,而是从持久化开始到持久化结束这段时间发生的增量AOF日志。
重启Redis时,可以先加载rdb的内容,再重放增量AOF日志,重启效率大幅提升。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号