视频流和文件传输相关协议
视频编码的两大流派
- ITU(International Telecommunications Union)的VECG(Video Coding Experts Group),这个称为国际电联下的 VECG。
- ISO(International Standards Organization)的 MPEG(Moving Picture Experts Group),这个是ISO 旗下的 MPEG.
网络直播
网络协议将编码好的视频流,从主播端推送到服务器,在服务器上有个运行了同样协议的服务端来接收这些网络包,从而得到里面的视频流,这个过程称为接流。
服务端接到视频流之后,可以对视频流进行一定的处理,例如转码,也即从一个编码格式,转成 另一种格式。因为观众使用的客户端千差万别,要保证他们都能看到直播。
流处理完毕之后,就可以等待观众的客户端来请求这些视频流。观众的客户端请求的过程称为拉流。
当观众的客户端将视频流拉下来之后,就需要进行解码,也即通过上述过程的逆过程,将一串串看不懂的二进制,再转变成一帧帧生动的图片,在客户端播放出来
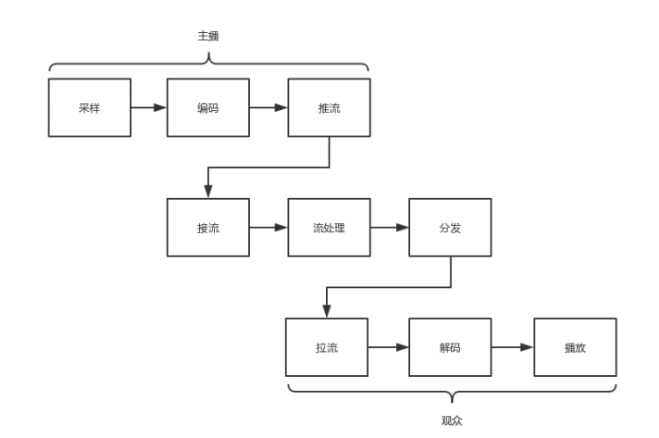
将这个二进制的流打包成网络包进行发送,这里我们使用RTMP 协议。RTMP 是基于 TCP 的,因而肯定需要双方建立一个 TCP 的连接。在有 TCP 的连接的基础上, 还需要建立一个 RTMP 的连接,也即在程序里面,你需要调用 RTMP 类库的 Connect 函数,显示创建一个连接。
RTMP作用是主要确认两个事情:,一个是版本号, 如果客户端、服务器的版本号不一致,则不能工作。另一个就是时间戳,视频播放中,时间是很重要的,后面的数据流互通的时候,经常要带上时间戳的差值,因而一开始双方就要知道对方的时间戳。
分发网络分为中心和边缘两层。边缘层服务器部署在全国各地及横跨各大运营商里,和用户距离很近。中心层是流媒体服务集群,负责内容的转发。智能负载均衡系统,根据用户的地理位置信息,就近选择边缘服务器,为用户提供推 / 拉流服务。中心层也负责转码服务,例如,把RTMP 协议的码流转换为 HLS 码流。
文件传输
FTP:文件传输协议,采用两个TCP链接来传输一个文件。
服务器以被动的方式,打开众所周知用于 FTP 的端口 21,客户端则主动发起连接。该连接将命令从客户端传给服务器,并传回服务器的应答。
P2P: P2P就是peer-to-peer。资源开始并不集中地存储在某些设备上,而是分散地存储在多台设备上。想要下载一个文件的时候,你只要得到那些已经存在了文件的 peer,并和这些 peer 之间,建立点对点的连接,而不需要到中心服务器上,就可以就近下载文件。一旦下载了文件,你也就成 为 peer 中的一员,你旁边的那些机器,也可能会选择从你这里下载文件,所以当你使用 P2P软件的时候,例如 BitTorrent,往往能够看到,既有下载流量,也有上传的流量,也即你自己也加入了这个 P2P 的网络,自己从别人那里下载,同时也提供给其他人下载。
种子(torrent)文件:由announce(tracker URL)和文件信息组成。
- 文件信息:
- info区:该种子有几个文件,文件有多长,目录结构以及目录和文件的名字
- name字段:顶层目录的名字
- 每个段的大小:BitTorrent协议把一个文件分成很多小段,然后分段下载。
- 段哈希值:将整个种子中,每个段的SHA-1哈希值拼在一起
下载时,BT 客户端首先解析.torrent 文件,得到 tracker 地址,然后连接 tracker 服务器。 tracker 服务器回应下载者的请求,将其他下载者(包括发布者)的 IP 提供给下载者。下载者 再连接其他下载者,根据.torrent 文件,两者分别对方告知自己已经有的块,然后交换对方没有 的数据。此时不需要其他服务器参与,并分散了单个线路上的数据流量,因此减轻了服务器的负 担。
从这个过程也可以看出,这种方式特别依赖 tracker。tracker 需要收集下载者信息的服务器, 并将此信息提供给其他下载者,使下载者们相互连接起来,传输数据。虽然下载的过程是非中心 化的,但是加入这个 P2P 网络的时候,都需要借助 tracker 中心服务器,这个服务器是用来登记有哪些用户在请求哪些资源。所以,这种工作方式有一个弊端,一旦 tracker 服务器出现故障或者线路遭到屏蔽,BT 工具就无法正常工作了。
DHT(Distributed Hash Table)去中心化网络:任何一个 BitTorrent 启动之后,它都有两个角色。一个是peer,监听一个 TCP 端口,用来上传 和下载文件,这个角色表明,我这里有某个文件。另一个角色DHT node,监听一个 UDP 的端口,通过这个角色,这个节点加入了一个 DHT 的网络。
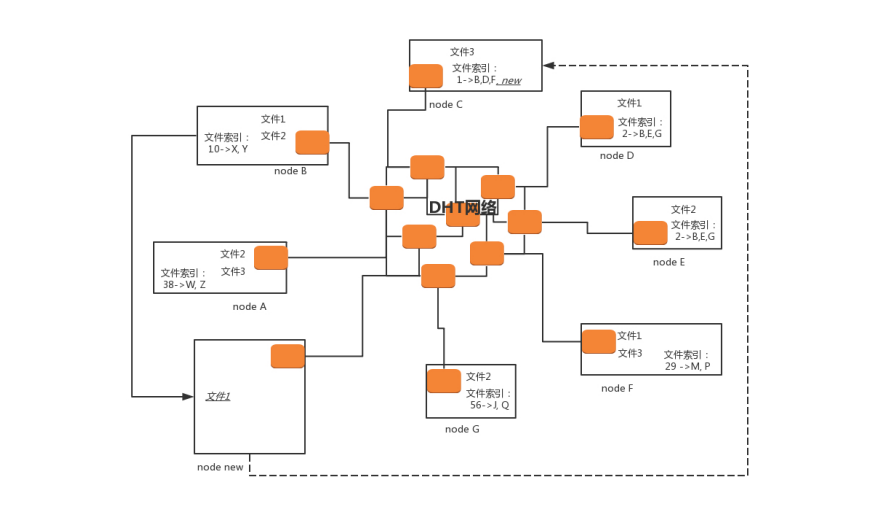
在 DHT 网络里面,每一个 DHT node 都有一个 ID。这个 ID 是一个很长的串。每个 DHT node 都有责任掌握一些知识,也就是文件索引,也即它应该知道某些文件是保存在哪些节点 上。它只需要有这些知识就可以了,而它自己本身不一定就是保存这个文件的节点。
每个文件可以算出一个哈希值,而DHT node的ID是和哈希值相同长度的串,DHT算法规定:如果一个文件计算出一个哈希值,泽合这个哈希值一样的DHT node,就有责任知道从哪里下载这个文件,即便他自己没保存。另外,除了一摸一样的DHT node应该知道,ID和这个哈希值非常接近的N个DHT node也应该知道。
接下来一个新的节点 node new 上线了。如果想下载文件 1,它首先要加入 DHT 网络,如何加入呢?
在这种模式下,种子.torrent 文件里面就不再是 tracker 的地址了,而是一个 list 的 node 的地址,而所有这些 node 都是已经在 DHT 网络里面的。当然随着时间的推移,很可能有退出的,有下线的,但是我们假设,不会所有的都联系不上,总有一个能联系上。 node new 只要在种子里面找到一个 DHT node,就加入了网络。

