python接口自动化(3)数据驱动
数据驱动
ddt
python 的unittest 没有自带数据驱动功能。所以如果使用unittest,同时又想使用数据驱动,那么就可以使用DDT来完成。
一般进行接口测试时,每个接口的传参都不止一种情况,一般会考虑正向、逆向等多种组合。所以在测试一个接口时通常会编写多条case,而这些case除了传参不同外,其实并没什么区别。这个时候就可以利用ddt来管理测试数据,提高代码复用率。
使用方法:
ddt.ddt: 装饰类,装饰继承自unittest.TestCase的类
ddt.data: 装饰测试方法,参数是一系列的值
ddt.file_data: 装饰测试方法,参数是文件名,文件可以是json或者yaml类型
ddt.unpack: 传递的是复杂的数据结构时使用。比如使用元组或者列表,添加unpack之后,ddt会自动把元组或者列表对应到多个参数上。字典也可以这样处理。
简单使用:直接放入数值
实例1:
import requests
import unittest
import ddt
data=[
{"user":"admin1","psw":"111111", "expect":False},
{"user":"admin2","psw":"222222", "expect":True},
{"user":"admin3","psw":"xxxxxx", "expect":False},
]
str1='hello'
@ddt.ddt
class Test1(unittest.TestCase):
@ddt.data(*data)
def test_01(self,testdata):
print(testdata)
@ddt.data(*str1)
def test_02(self,testdata2):
print(testdata2)
if __name__=='__main__':
unittest.main()
运行结果为:
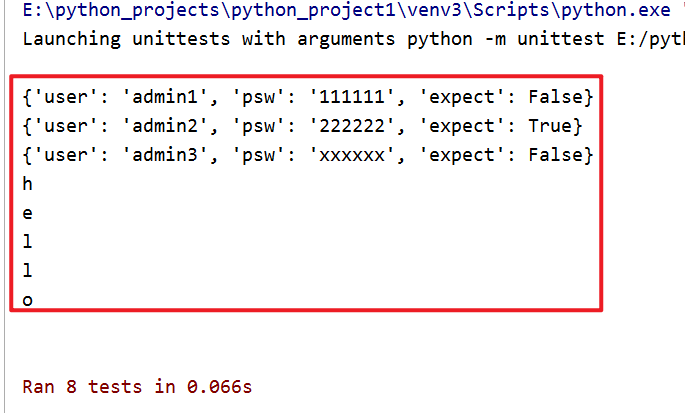
放入复杂结构数据
import unittest
import requests
import ddt
@ddt.ddt()
class Demo(unittest.TestCase):
@ddt.data((3,2),(9,5),(6,3))
@ddt.unpack
def test01(self,first_value,second_value):
self.assertTrue(first_value>second_value)
@ddt.data([7,4],[9,2],[8,3])
@ddt.unpack
def test02(self,first_value,second_value):
self.assertTrue(first_value>second_value)
@ddt.data({"name":34,"age":21},
{"name":54,"age":23})
@ddt.unpack
def test03(self,name,age):
self.assertTrue(name>age)
if __name__=='__main__':
suite=unittest.TestSuite
suite.addTest(Demo('test02'))
runner=unittest.TextTestRunner()
runner.run(suite)
注意:使用测试套件TestSuite时而且脚本内容涉及到ddt时,建议不使用python正常环境运行,否则可能报错,建议使用unittest in xxx方式来运行脚本。
案例:招生系统登录的数据驱动
import ddt
import unittest
import requests
import re
s=requests.Session()
data=[
{"user":"admin","psw":"660B8D2D5359FF6F94F8D3345698F88C", "expect":['退出登录']},
{"user":"admin2","psw":"222222", "expect":[]},
{"user":"admin3","psw":"xxxxxx", "expect":[]},
]
def login(username,password):
url='http://192.168.239.135:8080/recruit.students/login/in'
payload={
"account":username,
"pwd":password
}
return s.post(url,params=payload)
@ddt.ddt
class Test1(unittest.TestCase):
def setUp(self) -> None:
self.s=requests.Session()
@ddt.data(*data)
def test_1(self,testdata):
print("本次测试数据为:{}".format(testdata))
user=testdata["user"]
pwd=testdata["psw"]
login_r=login(username=user,password=pwd)
login_r_text=print(re.findall("退出登录",login_r.text))
expect=testdata["expect"]
self.assertTrue(expect==expect)
def tearDown(self) -> None:
self.s.close()
if __name__=='__main__':
unittest.main()
excel数据读写
python操作excel主要用到xlrd和xlwt这两个库,即xlrd是读excel,xlwt是写excel的库。
安装xlrd和xlwt模块:
pip3 install xlrd -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
pip3 install xlwt -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
如果直接pip install xlrd/xlwt可能会报错,原因:可能资源在国外服务器,导致下载不下来,加上豆瓣,表示去豆瓣源上下载,较国外网址快一些
其他源地址:
读取excel数据
实例:
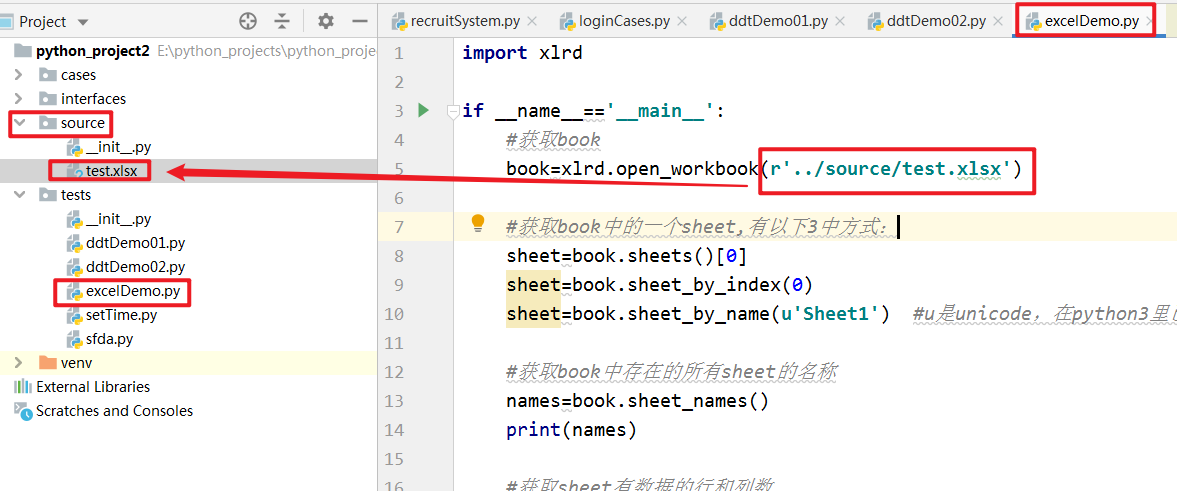
手动在项目的source package下,建立一个xlsx文件,如下:
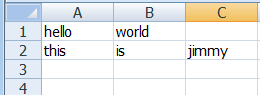
编写代码:
import xlrd
if __name__=='__main__':
#获取book
book=xlrd.open_workbook(r'../source/test.xlsx')
#获取book中的一个sheet,有以下3中方式:
sheet=book.sheets()[0]
sheet=book.sheet_by_index(0)
sheet=book.sheet_by_name(u'Sheet1') #u是unicode,在python3里已经有点多余了
#获取book中存在的所有sheet的名称
names=book.sheet_names()
print(names)
#获取sheet有数据的行和列数
nrows=sheet.nrows
ncols=sheet.ncols
# 获取sheet中的某行或者某列,以列表的形式返回
print(sheet.row_values(0)) #第一行
print(sheet.col_values(0)) #第一列
#获取sheet中某个单元格的数据
print(sheet.cell_value(1,1))
运行结果为:
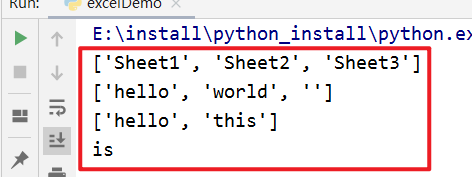
注意:在pycharm,如果使用if __name__=='__main__'来运行,那么相对路径最好有使用..或.,否则会报错:
如果是单独运行,一条条语句的运行,貌似按下面这样就可以了:

excel读取封装
下面封装excel的读取操作,将第一行作为key,将第2,3,4....行作为value,并封装到字典中,再将字典封装到列表中,如:
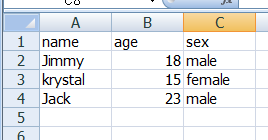
最终的实现效果是:
[{'name': 'Jimmy', 'age': 18.0, 'sex': 'male'}, {'name': 'krystal', 'age': 15.0, 'sex': 'female'}, {'name': 'Jack', 'age': 23.0, 'sex': 'male'}]
代码实现:
# coding=utf-8
import xlrd
class ExcelUtil():
def __init__(self,excelPath,sheetName='Sheet1'):
self.book=xlrd.open_workbook(excelPath)
self.sheet_t=self.book.sheet_by_name(sheetName)
#获取第一行作为key值
self.keys=self.sheet_t.row_values(0)
#获取总行数
self.rowNum=self.sheet_t.nrows
#获取总列数
self.colNum=self.sheet_t.ncols
def dict_data(self):
if self.rowNum<2:
print("总行数小于2")
else:
r=[]
j=1
for i in range(self.rowNum-1):
s={}
#从第二行取对应的values值
values=self.sheet_t.row_values(j)
for x in range(self.colNum):
s[self.keys[x]]=values[x] #写入字典中
r.append(s) #将字典追加到列表中
j+=1
return r
if __name__=='__main__':
excelPath="../source/test.xlsx"
sheetName="Sheet1"
myexcel=ExcelUtil(excelPath,sheetName=sheetName)
print(myexcel.dict_data())
运行结果为:

往excel写入数据
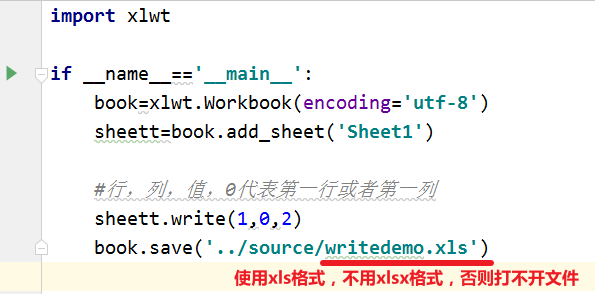
excel与ddt结合
准备excel表格excelDDT.xlsx:
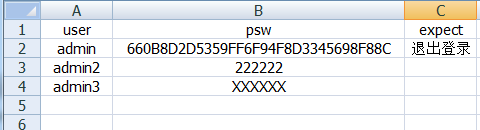
需求:将excel的数据转为字典,并用列表包起来,然后使用,进行招生系统的登录。
代码实现:
import requests
import xlrd
import ddt
import unittest
from tests import excelDemo2
import re
myexcel=excelDemo2.ExcelUtil('../source/excelDDT.xlsx','Sheet1')
data=myexcel.dict_data()
@ddt.ddt
class excelddt(unittest.TestCase):
def __int__(self):
pass
def setUp(self) -> None:
self.s=requests.session()
def login(self,account,pwd):
login_url='http://192.168.239.135:8080/recruit.students/login/in'
payload={
'account':account,
'pwd' : pwd
}
return self.s.get(login_url,params=payload)
@ddt.data(*data)
def test_0(self,testdata):
print("本次测试数据为:{}".format(testdata))
user=testdata['user']
pwd=testdata['psw']
login_r=self.login(user,pwd)
try:
expect=str(re.findall('退出登录',login_r.text)[0])
except Exception:
expect=''
self.assertTrue(expect==testdata['expect'])
if __name__=='__main__':
unittest.main()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号