Java(23)集合
集合
Java集合类存放于Java.util包中,是一个用来存放对象的容器。
- 集合只能用来存放对象。如果存放一个
int整型数据进入集合中,会自动将int转换成Integer包装类。 - 集合存放的是多个对象的引用,对象本身存放在堆内存中。
- 集合可以存放不同类型,不同数量的数据类型。
jdk5之后,Java提供了泛型,可以限制集合中的数据类型。
数组其实是一种特殊的集合,为什么还要有集合呢?
这是因为数组有如下限制:
- 数组初始化后大小不可变;
- 数组只能按索引顺序存取。
因此,我们需要各种不同类型的集合类来处理不同的数据,例如:
- 可变大小的顺序链表;
- 保证无重复元素的集合;
- ...
Java集合主要分为三大体系:
Set:无序、不可重复的集合List:有序,可重复的集合Map:具有映射关系的集合(key-value)
Set
HashSet类
HashSet是Set接口的实现类。HashSet按照Hash算法来存储集合中的元素,因此具有很好的存储和查找性能。
HashSet特点:
- 不能保证元素的排序:存入一个对象时会调用该对象的
hashCode()方法得到hashCode值,再根据hashCode值决定元素存储位置。 - 不可重复:不可重复的意思是
hashCode不能相同。 HashSet不是线程安全的。- 集合元素可以是
null。

案例1:
package day01;
import java.util.HashSet;
import java.util.Set;
public class DayB {
public static void main(String[] args) {
Set sa= new HashSet();
//添加元素
sa.add("I love you");
sa.add(34);
System.out.println(sa); //[34, I love you]
//判断是否包含元素
System.out.println(sa.contains(34)); //true
//移除元素
sa.remove(34);
System.out.println(sa); //[I love you]
//获取集合中元素个数:
System.out.println(sa.size());//1
//清空元素
sa.clear();
System.out.println(sa); //[]
}
}
案例2:遍历集合
package day01;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class DayB {
public static void main(String[] args) {
Set sb= new HashSet();
sb.add("a");
sb.add("b");
sb.add("c");
//使用迭代器遍历:
Iterator it=sb.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
//使用For each循环遍历:
for(Object a:sb){
System.out.println(a);
}
}
}
补充知识点(迭代器):
迭代器是一种设计模式,它是一个对象,它可以遍历并选择序列中的对象。使用方法
iterator()可要求容器(集合等)返回一个Iterator。iterator()方法是java.lang.Iterable接口,被Collection继承。
Iterator接口主要用于遍历Collection集合中的元素,Iterator对象称为迭代器。
使用`Iterator`的`next()`可获得序列中的下一个元素。第一次调用`next()`方法时,它返回序列的第一个元素。使用`Iterator`的`hasNext()`可检查序列中是否还有元素。使用`remove()`将迭代器新返回的元素删除。
案例3:泛型---将集合设置为只能存放某类型对象
package day01;
import java.util.HashSet;
import java.util.Set;
public class DayB {
public static void main(String[] args) {
Set <String>sc= new HashSet<String>();
sc.add("Hello");
sc.add(24); //编译会报错,只能存放字符串类型对象
Set sd=new HashSet();//相当于: Set<Object>sd=new HashSet<>();
}
}
//后面会详细将泛型
TreeSet类
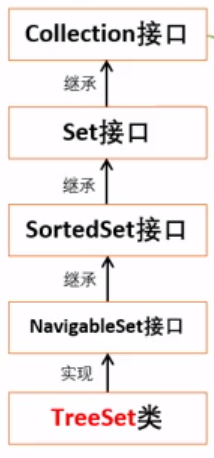
TreeSet是SortedSet接口的实现类:
-
HashSet是无序的,因为它实现了Set接口,并没有实现SortedSet接口 -
TreeSet是有序的,因为它实现了SortedSet接口。
TreeSet支持两种排序:自然排序(默认采用)和定制排序
- 自然排序:
TreeSet会调用集合元素的CompareTo(Object obj)方法比较元素间大小关系,并将集合元素按升序排序。TreeSet集合里,建议必须放入同样类型的对象(因为默认会进行排序),否则可能发生类型转换异常,可以通过泛型进行限制。 - 定制排序:若定制排序,需要存放到集合中的对象对应的类实现
Comparator接口,并重写int Compare()方法。
案例1:自然排序
package day01;
import java.util.Set;
import java.util.TreeSet;
public class DayB {
public static void main(String[] args) {
Set <Integer>sg= new TreeSet<Integer>();
sg.add(234);
sg.add(7);
sg.add(34);
for (Integer a:sg){
System.out.println(a);
}
}
}
/*运行结果为:
7
34
234
*/
案例2:定制排序----将Person类的对象存到集合中,并按照对象的age值来进行排序。
package day01;
import java.util.Comparator;
import java.util.Set;
import java.util.TreeSet;
public class DayB { //运行类
public static void main(String[] args) {
Set<Person> sk=new TreeSet<Person>(new Person()); //这里的泛型限制一定要加上,并且要将Person对象作为参数
Person p1=new Person("krystal",20);
Person p2=new Person("Jimmy",21);
Person p3=new Person("anna",14);
Person p4=new Person("bob",63);
sk.add(p1);
sk.add(p2);
sk.add(p3);
sk.add(p4);
for(Person a:sk){
System.out.println(a.getName()+" : "+a.getAge());
}
}
}
class Person implements Comparator<Person>{ //这里一定要加上泛型限制,不然报错
private int age;
private String name;
public Person(){
}
public Person(String name,int age){
this.name=name;
this.age=age;
}
public int getAge() {
return age;
}
public String getName() {
return name;
}
@Override
public int compare(Person o1, Person o2) { //注意这里的参数要是Person类
if(o1.getAge() > o2.getAge()){ //将>和<调换即可反向排序
return 1;
}else if(o1.getAge()<o2.getAge()){
return -1;
}else {
return 0;
}
}
}
/*运行结果为:
anna : 14
krystal : 20
Jimmy : 21
bob : 63
*/
List
ArrayList类

ArrayList是List接口的实现类。ArrayList是线程不安全的。
List是有序可重复的集合,集合中的元素都有对应的索引。List可以通过索引来访问集合指定位置的元素List将元素添加顺序设置为默认索引List添加了一些通过索引操作集合的方法,如上图
Vector(线程安全)也是List接口的实现类,虽然是线程安全的,但是比较古老了,不推荐使用。
案例1
import java.util.ArrayList;
import java.util.List;
public class DayB{
public static void main(String[] args) {
List<Integer> la=new ArrayList<Integer>();
la.add(3); //索引下标为0
la.add(53); //索引下标为1
la.add(21); //索引下标为2
System.out.println(la);
System.out.println(la.get(2)); //访问索引为2的元素
la.add(2,44); //在索引为2的位置添加元素44
System.out.println(la);
List lb=new ArrayList();
lb.add(99);
lb.add(100);
la.addAll(2,lb); //在索引位置添加另一个List集合
System.out.println(la);
la.add(99);
System.out.println(la);
System.out.println(la.indexOf(99)); //查看元素第一次出现的索引
System.out.println(la.lastIndexOf(99)); //查看元素最后一次出现的索引
la.remove(4);//移除索引4对应的元素
la.set(2,1024); //将索引为2的元素的值改为1024
List subl=la.subList(1,4);
//将1到3索引的元素作为子集subl,sublist()的作用是返回一个子集对象,左闭右开
System.out.println(subl);
}
}
Map
HashMap类
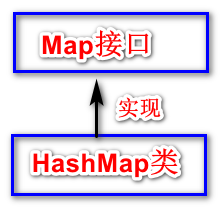
HashMap是Map接口的实现类,Map接口比较特别,它并没有去继承Collection接口。
- Map保存映射关系数据(key-value)
- Map中的Key不允许重复
案例1:常用方法
package day01;
import java.util.HashMap;
import java.util.Map;
public class DayB{
public static void main(String[] args) {
Map mp=new HashMap();
mp.put("krystal",20); //添加元素
mp.put("Jimmy",21);
System.out.println(mp);
Map<String,Integer> mp2=new HashMap<String,Integer>(); //给Map设置泛型
mp2.put("kobe",41);
mp2.put("gigi",13);
mp2.put("James",35);
mp2.remove("James"); //根据Key移除元素
System.out.println(mp2.size()); //返回map集合的长度
System.out.println(mp2.containsKey("kobe"));//判断是否包含某key
System.out.println(mp2.containsValue("41")); //判断是否包含某value
mp2.clear();//清空集合
}
}
/*运行结果为:
{krystal=20, Jimmy=21}
2
true
false
*/
案例2:遍历map集合
package day01;
import org.omg.PortableInterceptor.INACTIVE;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class DayB{
public static void main(String[] args) {
Map<String,Integer> mp2=new HashMap<String,Integer>(); //给Map设置泛型
mp2.put("kobe",41);
mp2.put("gigi",13);
mp2.put("James",35);
//方法1:创建key集合
Set<String> keys=mp2.keySet(); //创建key集合,keySet()可以返回key集合
for(String s:keys){
System.out.println(s+" : "+ mp2.get(s));
}
//方法2:使用entrySet()方法:
Set<Map.Entry<String, Integer>> a=mp2.entrySet();
for(Map.Entry<String,Integer> en:a){
System.out.println(en.getKey()+" : "+en.getValue());
}
}
}
HashMap与HashTable
HashMap和Hashtable是Map接口的两个典型实现类,两者区别:
- Hashtable是一个古老实现类,不推荐使用
- Hashtable线程安全,HashMap线程不安全
- Hashtable允许使用null作为key和value,HashMap可以
- Hashtable与HashMap都不能保证key-value的顺序
- Hashtable与HashMap判断两个key相同的标准都是equals()返回true,hashCode值也相等
import java.util.HashMap;
import java.util.Hashtable;
import java.util.Map;
public class DayB{
public static void main(String[] args) {
Map<String,Integer>ma=new HashMap<String,Integer>();
ma.put(null,null); //运行不会报错
Map<String,Integer>mt=new Hashtable<String,Integer>();
ma.put(null,null); //运行会报错
}
}
TreeMap类
TreeMap和TreeSet一样,是有序的。
TreeMap的Key的排序:
- 自然排序:
TreeMap的所有Key必须实现Comparable接口,且所有的Key应该是同一个类的对象,否则会抛出异常ClassCastException - 定制排序:
Map的Key不需要实现Comparable接口,但是要实现Comparator接口。
案例1:TreeMap自然排序
package day01;
import java.util.Map;
import java.util.TreeMap;
public class DayB{
public static void main(String[] args) {
Map<Integer,String> mL=new TreeMap<Integer, String>();
mL.put(3,"apple");
mL.put(2,"banana");
mL.put(5,"grape");
System.out.println(mL);
}
}
/*运行结果为:
{2=banana, 3=apple, 5=grape}
*/
//所有的基本数据类型的包装类都实现了Comparable接口,例如,Integer的源代码如下:
public final class Integer extends Number implements Comparable<Integer>{}
案例2:TreeMap定制排序
package day01;
import java.util.Comparator;
import java.util.Map;
import java.util.Set;
import java.util.TreeMap;
public class DayB {
public static void main(String[] args) {
Map<Shoe,String> mS = new TreeMap<Shoe, String>(new Shoe());
Shoe s1=new Shoe("Jimmy",21);
Shoe s2=new Shoe("Krystal",20);
Shoe s3=new Shoe("who",31);
mS.put(s1,"第一个人");
mS.put(s2,"第二个人");
mS.put(s3,"第三个人");
System.out.println(mS);
Set<Shoe> a= mS.keySet();
for(Shoe i:a){
System.out.println(i.age);
}
}
}
class Shoe implements Comparator<Shoe> {
public int age;
public String name;
public Shoe() {
}
public Shoe(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public int compare(Shoe o1, Shoe o2) {
if (o1.age > o2.age) {
return 1;
} else if (o1.age < o2.age) {
return -1;
} else {
return 0;
}
}
}
工具类Collections
注意这里说的是Collections类,是有s的,不是Collection接口。
