Hadoop(24) 初步认识yarn
yarn介绍
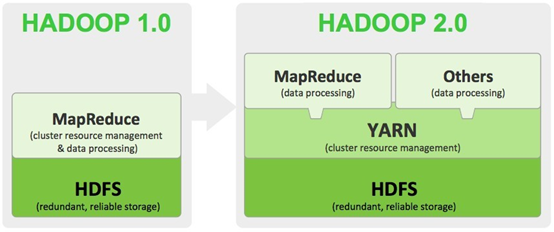
yarn(Yet Another Resource Negotiator)是一个新的资源管理器,hadoop2.0的时候开始引入yarn,引入yarn是为了分离hadoop的资源管理和计算组件。yarn是一个通用的管理框架,在yarn上不仅仅可以运行Mapreduce,还可以支持其它的分布式计算模式。
yarn架构
类似HDFS,YARN也是经典的主从(master/slave)架构
YARN服务由一个ResourceManager(RM)和多个NodeManager(NM)构成。ResourceManager为主节点(master)。NodeManager为从节点(slave)。
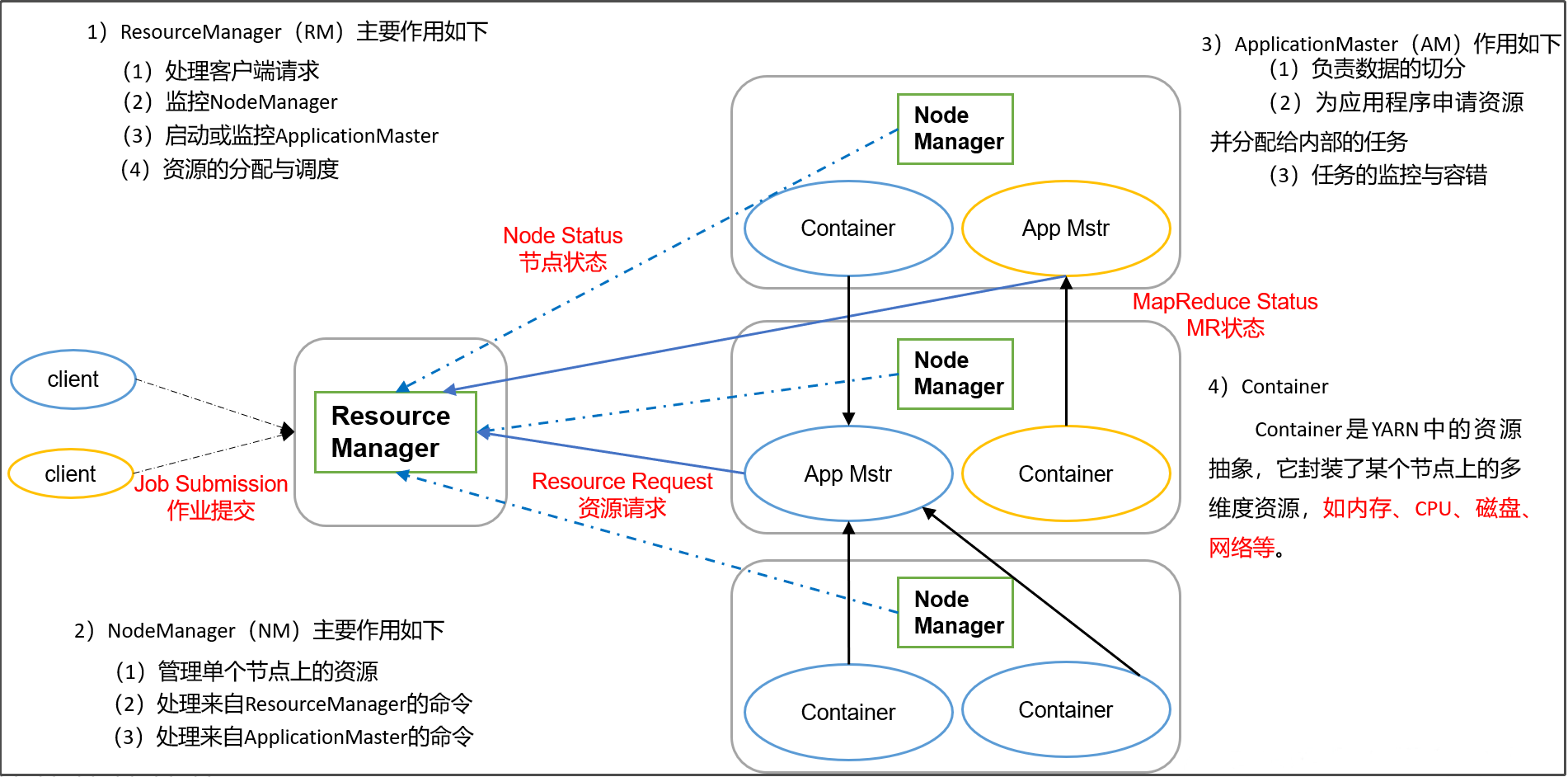
ResourceManager(RM)
ResourceManager是YARN中主的角色
RM是一个全局的资源管理器,集群只有一个对外提供服务- 负责整个系统的资源管理和分配
- 包括处理客户端请求
- 启动/监控
ApplicationMaster - 监控
NodeManager、资源的分配与调度
ResourceManager主要由两个组件构成(了解就行):
-
调度器(
Scheduler) -
应用程序管理器(
Applications Manager,ASM)
调度器Scheduler:
-
调度器根据容量、队列等限制条件(如每个队列分配一定的资源,最多执行一定数量的作业等),将系统中的资源分配给各个正在运行的应用程序。
-
需要注意的是,该调度器是一个“纯调度器”
-
它不从事任何与具体应用程序相关的工作,比如不负责监控或者跟踪应用的执行状态等,也不负责重新启动因应用执行失败或者硬件故障而产生的失败任务,这些均交由应用程序相关的
ApplicationMaster完成。 -
调度器仅根据各个应用程序的资源需求进行资源分配,而资源分配单位用一个抽象概念“资源容器”(
Resource Container,简称Container)表示,Container是一个动态资源分配单位,它将内存、CPU、磁盘、网络等资源封装在一起,从而限定每个任务使用的资源量。
应用程序管理器Applications Manager,ASM
-
应用程序管理器主要负责管理整个系统中所有应用程序
-
接收job的提交请求
-
为应用分配第一个
Container来运行ApplicationMaster,包括应用程序提交、与调度器协商资源以启动ApplicationMaster、监控ApplicationMaster运行状态并在失败时重新启动它等
NodeManager(NM)
NodeManager 是YARN中的 slave角色
- 每个计算节点,运行一个
NodeManager进程;通过心跳(每秒yarn.resourcemanager.nodemanagers.heartbeat-interval-ms)上报节点的资源状态(磁盘,内存,cpu等使用信息) NodeManager它负责接收ResourceManager的资源分配请求,分配具体的Container给应用。- 负责监控并报告
Container使用信息给ResourceManager。
Nodemanager功能:
NodeManager监控本节点上的资源使用情况和各个Container的运行状态(cpu和内存等资源)- 接收及处理来自
ResourceManager的命令请求,分配Container给应用的某个任务; - 定时地向
ResourceManager汇报以确保整个集群平稳运行,RM通过收集每个NodeManager的报告信息来追踪整个集群健康状态的,而NodeManager负责监控自身的健康状态; - 处理来自
ApplicationMaster的请求; - 管理着所在节点每个
Container的生命周期; - 管理每个节点上的日志;
- 当一个节点启动时,它会向
ResourceManager进行注册并告知ResourceManager自己有多少资源可用。 - 在运行期,通过
NodeManager和ResourceManager协同工作,这些信息会不断被更新并保障整个集群发挥出最佳状态。 NodeManager只负责管理自身的Container,它并不知道运行在它上面应用的信息。负责管理应用信息的组件是ApplicationMaster
Container
Container 是什么?
-
Container是YARN中的资源抽象,YARN以Container为单位分配资源。本质是JVM。 -
Container封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络。 -
当
ApplicationMaster向ResourceManager申请资源时,ResourceManager为ApplicationMaster返回的资源便是用Container表示的。 -
YARN会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。 -
任何一个
job或application必须运行在一个或多个Container中。
Container功能
- 对
task环境的抽象; - 描述一系列信息;
- 任务运行资源的集合(
cpu、内存、io等); - 任务运行环境
Container 和NodeManager节点的关系
-
一个
NodeManager节点可运行多个Container -
但一个
Container不会跨节点。 -
在
Yarn框架中,ResourceManager只负责告诉ApplicationMaster哪些Containers可以用,ApplicationMaster还需要去找NodeManager请求分配具体的Container。
注意事项
-
Container是一个动态资源划分单位,是根据应用程序的需求动态生成的。 -
目前为止,
YARN仅支持CPU和内存两种资源,且使用了轻量级资源隔离机制Cgroups进行资源隔离。
ApplicationMaster
功能:
-
获得数据分片;
-
为应用程序申请资源并进一步分配给内部任务(
TASK); -
任务监控与容错;
-
负责协调来自
ResourceManager的资源,并通过NodeManager监视容器的执行和资源使用情况。
ApplicationMaster 与 ResourceManager 之间的通信是整个 Yarn 应用从提交到运行的最核心部分,是 Yarn 对整个集群进行动态资源管理的根本步骤。
Yarn 的动态性,就是来源于多个Application 的 ApplicationMaster 动态地和 ResourceManager 进行沟通,不断地申请、释放、再申请、再释放资源的过程。
JobHistoryServer
JobHistoryServer (作业历史服务) 记录在yarn中调度的作业历史运行情况情况,可以通过历史任务日志服务器来查看hadoop的历史任务,出现错误都应该第一时间来查看日志日志
配置历史日志服务
第一步:修改mapred-site.xml
node01执行以下命令修改mapred-site.xml
cd /kkb/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop
vim mapred-site.xml
<property>
<name>mapreduce.jobhistory.address</name>
<value>node01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node01:19888</value>
</property>
注意:如果已经存在以上两项配置,那么就不需要再进行配置了
第二步:修改yan-site.xml
cd /kkb/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop
vim yarn-site.xml
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 多长时间聚合删除一次日志 此处 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>2592000</value><!--30 day-->
</property>
<!-- 时间在几秒钟内保留用户日志。只适用于如果日志聚合是禁用的 -->
<property>
<name>yarn.nodemanager.log.retain-seconds</name>
<value>604800</value><!-- 7 day -->
</property>
<!-- 指定文件压缩类型用于压缩汇总日志 -->
<property>
<name>yarn.nodemanager.log-aggregation.compression-type</name>
<value>gz</value>
</property>
<!-- nodemanager本地文件存储目录 -->
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/yarn/local</value>
</property>
<!-- resourceManager 保存最大的任务完成个数 -->
<property>
<name>yarn.resourcemanager.max-completed-applications</name>
<value>1000</value>
</property>
第三步:将修改后的文件同步到其他机器上面去
node01服务器执行以下命令,将修改后的文件同步发送到其他服务器上面去
cd /kkb/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop
scp mapred-site.xml yarn-site.xml node02:$PWD
scp mapred-site.xml yarn-site.xml node03:$PWD
第四步:重启yarn以及jobhistory服务
node01执行以下命令重启yarn以及jobhistory服务
cd /kkb/install/hadoop-2.6.0-cdh5.14.2
sbin/start-yarn.sh
sbin/mr-jobhistory-daemon.sh start historyserver
Timeline Server
用来写日志服务数据 , 一般来写与第三方结合的日志服务数据(比如spark等)
它是对jobhistoryserver功能的有效补充,jobhistoryserver只能对mapreduce类型的作业信息进行记录
它记录除了jobhistoryserver能够对作业运行过程中信息进行记录之外
还记录更细粒度的信息,比如任务在哪个队列中运行,运行任务时设置的用户是哪个用户。
根据官网的解释jobhistoryserver只能记录mapreduce应用程序的记录,timelineserver功能更强大,但不是替代jobhistory,两者是功能间的互补关系
