Hadoop(23)Mapreduce当中的join操作
Mapreduce当中的join操作
案例需求
订单数据表t_order:
| id | date | pid | amount |
|---|---|---|---|
| 1001 | 20150710 | P0001 | 2 |
| 1002 | 20150710 | P0002 | 3 |
| 1002 | 20150710 | P0003 | 3 |
| 1003 | 20150812 | P0003 | 1 |
商品信息表t_product
| pid | pname | category_id | price |
|---|---|---|---|
| P0001 | 小米5 | 1000 | 2000 |
| P0002 | 锤子T1 | 1000 | 3000 |
| P0003 | iphone11 | 5000 | 8000 |
假如数据量巨大,两表的数据是以文件的形式存储在HDFS中,需要用mapreduce程序来实现一下SQL查询运算:
select a.id,a.date,b.name,b.category_id,b.price from t_order a join t_product b on a.pid = b.id
将pid相同的数据进行关联合并
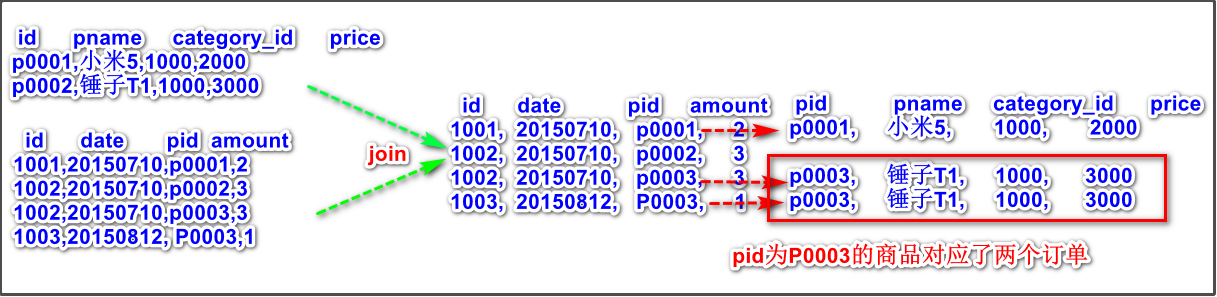
案例分析
特别要注意,从上图中可以看出,一个pid可能出现在不同的id订单中,所以商品信息对订单是一对多的关系,这个问题要解决。
进行join操作,可以在map端,也可以在reduce端。
reduce端的join操作
通过将关联的条件pid作为map输出的key,将两表满足join条件的数据并携带数据所来源的文件信息,发往同一个reduce task(默认的分区逻辑就是相同的key的数据会进入同一个reducetask),然后在reduce端中进行数据的串联 。
将pid作为key后,根据默认的分组逻辑,相同key(pid)的数据作为一组,会调用一次reduce()。

步骤1:定义map逻辑
package com.jimmy.day03;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
public class ReduceJoinMapper extends Mapper<LongWritable,Text,Text,Text> {
//现在我们读取了两个文件,我们要确定读取到的内容是商品信息还是订单信息
//因此可以有以下两种逻辑:
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//第一种逻辑, 通过文件名判断:
//切割数据:
String[]split=value.toString().split(",");
//获取文件的切片:
FileSplit inputSplit = (FileSplit) context.getInputSplit();
//获取文件名称
String name = inputSplit.getPath().getName();
if(name.equals("orders.txt")){
context.write(new Text(split[2]),value);
}else{
context.write(new Text(split[0]),value);
}
//=========================================
//第二种逻辑,判断文件内容是否以"p"开头
/*
String[] split = value.toString().split(",");
if( value.toString().startsWith("p")){
context.write(new Text(split[0]),value);
}else{
context.write(new Text(split[2]),value);
}
*/
/*第一种逻辑更靠谱,因为通过文件内容是否以p开头的话,
如果p为大写或者p前面有空格就识别不出来是商品信息了
*/
}
}
步骤2:定义reduce逻辑
定义reduce逻辑的时候,特别注意一个商品信息可能对应多个订单(一个商品可能别个人买)。因此,需要创建一个订单数组来保存订单信息,再遍历订单数组进行join操作。
package com.jimmy.day03;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.ArrayList;
public class ReduceJoinReducer extends Reducer<Text,Text,Text,NullWritable> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//按照默认的分组逻辑,相同的key(pid)的数据作为一组,调用一次reduce()方法
ArrayList<String> orderInfoList=new ArrayList<String>();
String productInfo = "";
for (Text value : values) {
if( value.toString().startsWith("p")){
//获取商品信息
productInfo = value.toString();
}else{
//把订单信息添加到订单数组中
orderInfoList.add(value.toString());
}
}
//遍历订单信息数组:
for(String odInfo:orderInfoList){
//进行join操作:
context.write(new Text(odInfo + "\t" + productInfo), NullWritable.get());
}
}
}
步骤3:定义组装类和main方法
package com.jimmy.day03;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class ReduceJoinMain extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
//获取job对象
Job job = Job.getInstance(super.getConf(), "reduceJoin");
//第一步:读取文件
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("file:///F://test4//"));
//第二步:设置自定义mapper逻辑
job.setMapperClass(ReduceJoinMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//分区,排序,规约,分组 省略
//第七步:设置reduce逻辑
job.setReducerClass(ReduceJoinReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//第八步:设置输出数据路径
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job, new Path("file:///F://test4//output"));
boolean b = job.waitForCompletion(true);
return b?0:1;
}
public static void main(String[] args) throws Exception {
int run = ToolRunner.run(new Configuration(), new ReduceJoinMain(), args);
System.exit(run);
}
}
运行结果

map端的join操作
上面的reduce端的join操作已经满足了我们的需求,为什么要使用map端来进行join操作。
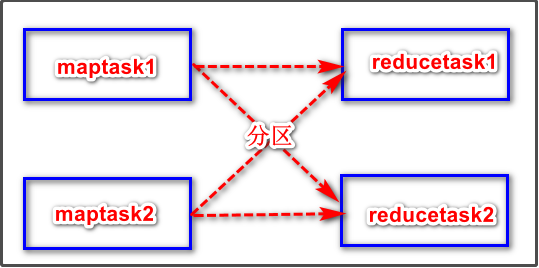
观察上图,假设reducetask不只有一个。
假如有某个商品是爆款,订单数量非常多。那么按照默认分区逻辑,相同的商品pid的订单数据或者商品数据,会进入同一个reducetask,如果还是使用reduce端的join操作方法的话,会导致要处理爆款商品相关join操作的reducetask所在节点压力非常大,出现了数据倾斜的问题。这时候就可以利用map端进行join操作,解决该问题。
解决数据倾斜问题的原理
假如有两个maptask,则这两个maptask都只会读取数据量很大的订单信息数据,数据量小的商品信息数据会被添加到分布式缓冲中,添加方法在通过main方法来调用。添加到分布式缓存后,在maptask开始运行之前,会调用mapper类里面的setup()方法,该方法是用来初始化的,通过该方法我们就可以将分布式缓存中的数据加载到每个maptask节点上,然后每个maptask开始进行join操作,最后输出出去,reduce逻辑不再需要定义了。
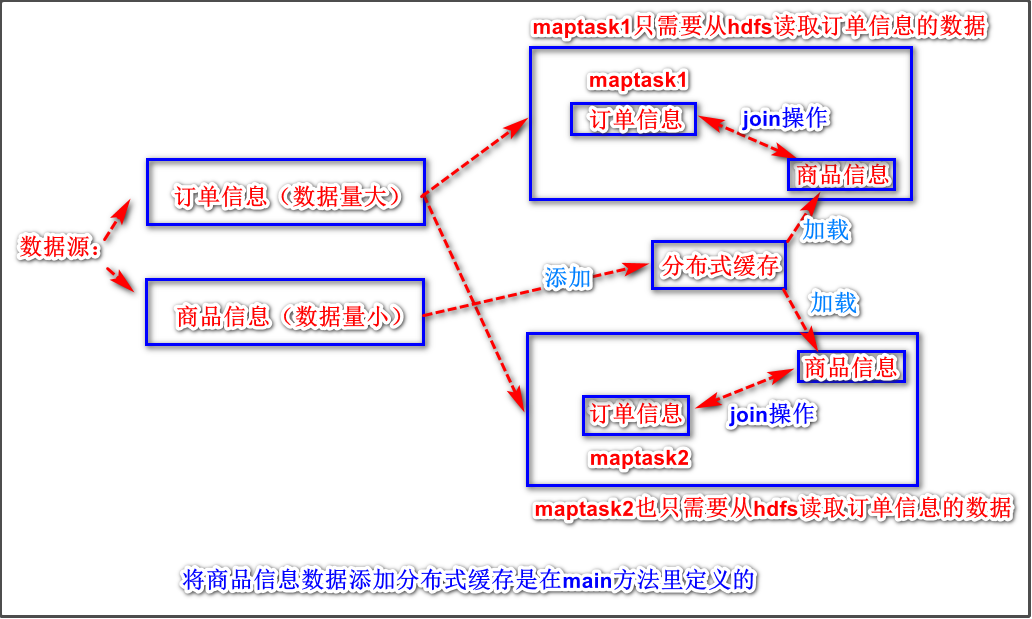
使用情形
适用于关联表中有小表的情形;
可以将小表分发到所有的map节点,这样,map节点就可以在本地对自己所读到的大表数据进行join并输出最终结果,可以大大提高join操作的并发度,加快处理速度。
步骤1:定义map逻辑
重写setup()方法,将分布式缓存中的数据加载到每个mapask节点上,然后定义map()逻辑进行join操作。
package com.jimmy.day02;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.HashMap;
import java.util.Map;
public class MapJoinMapper extends Mapper<LongWritable,Text,Text,NullWritable> {
private Map<String,String> pdtsMap ;
/**
* 初始化方法,只在程序启动调用一次
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void setup(Context context) throws IOException, InterruptedException {
pdtsMap = new HashMap<String, String>();
Configuration configuration = context.getConfiguration();
//获取到所有的缓存文件,但是现在只有一个缓存文件,是不是数组都无所谓
URI[] cacheFiles = DistributedCache.getCacheFiles(configuration);
//获取到 了我们放进去的缓存文件
URI cacheFile = cacheFiles[0];
//获取FileSystem
FileSystem fileSystem = FileSystem.get(cacheFile, configuration);
//读取文件,获取到输入流。这里面装的都是商品表的数据
FSDataInputStream fsDataInputStream = fileSystem.open(new Path(cacheFile));
/**
* p0001,xiaomi,1000,2
p0002,appale,1000,3
p0003,samsung,1000,4
*/
//包装成缓冲流,获取到BufferedReader 之后就可以一行一行的读取数据
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(fsDataInputStream));
String line =null;
while((line = bufferedReader.readLine()) != null){
String[] split = line.split(",");
pdtsMap.put(split[0],line);
}
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split(",");
//获取订单表的商品id
String pid = split[2];
//获取商品表的数据
String pdtsLine = pdtsMap.get(pid);
java
context.write(new Text(value.toString()+"\t" + pdtsLine), NullWritable.get());
}
}
步骤2:定义组装类和main方法
package com.jimmy.day02;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.net.URI;
public class MapJoinMain extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
URI uri = new URI("hdfs://node01:8020/cache/pdts.txt");
Configuration conf = super.getConf();
//添加缓存文件
DistributedCache.addCacheFile(uri,conf);
//获取job对象
Job job = Job.getInstance(conf, "mapJoin");
//读取文件,解析成为key,value对
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("file:///..."));
job.setMapperClass(MapJoinMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
//没有reducer逻辑,不用设置了
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("file:///..."));
boolean b = job.waitForCompletion(true);
return b?0:1;
}java
public static void main(String[] args) throws Exception {
int run = ToolRunner.run(new Configuration(), new MapJoinMain(), args);
System.exit(run);
}
}
