Hadoop(18)shuffle阶段(分区、排序、规约、分组)
Mapreduce--分区(shuffle)
分区partition
我们来回顾一下mapreduce编程指导思想中的第三个步骤(shuffle阶段的分区):
- 第三步:对输出的
key,value对进行分区:相同key的数据发送到同一个reduce task里面去,相同key合并,value形成一个集合。(这个分区的"区"本质是reduce task,将键值对数据分配到不同的reduce task)。分区是map端的组件。
示意图如下:
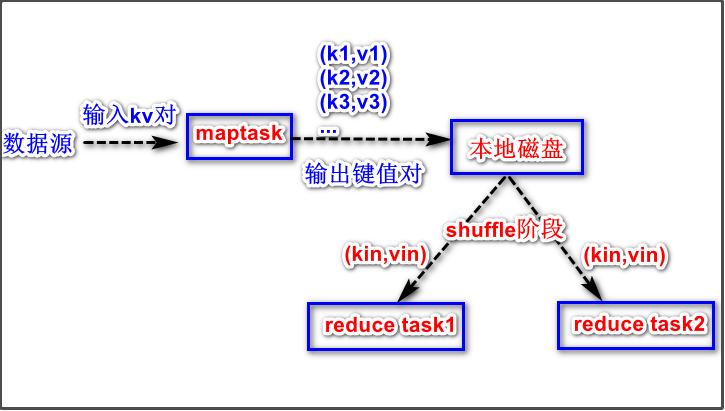
分区的个数是多少?怎么知道某个key的数据要进入到那个分区?
在mapreduce当中有一个抽象类叫做Partitioner,默认使用的实现类是HashPartitioner,我们可以通过HashPartitioner的源码,查看到分区的逻辑。
public class HashPartitioner<K, V> extends Partitioner<K, V> {
public HashPartitioner() {
}
//获取某个key的数据要进入分区:
public int getPartition(K key, V value, int numReduceTasks) {
return (key.hashCode() & 2147483647) % numReduceTasks;
//numReduceTasks是指reducetask的个数
}
}
从源码可知,分区公式为(key.hashCode() & 2147483647) % numReduceTasks,即对numReduceTasks的大小求余数。
假如说 numReduceTasks=4,则(key.hashCode() & 2147483647) % numReduceTasks的计算结果可能为0,1,2,3,因此,有4个分区。所以可以看到,分区的个数跟reduce task的个数是相一致的(从分区的作用就可以推测)。
因为key.hashCode()的存在,所以用户没法控制哪些key的数据进入哪些分区。但是我们可以定义自己的分区逻辑。
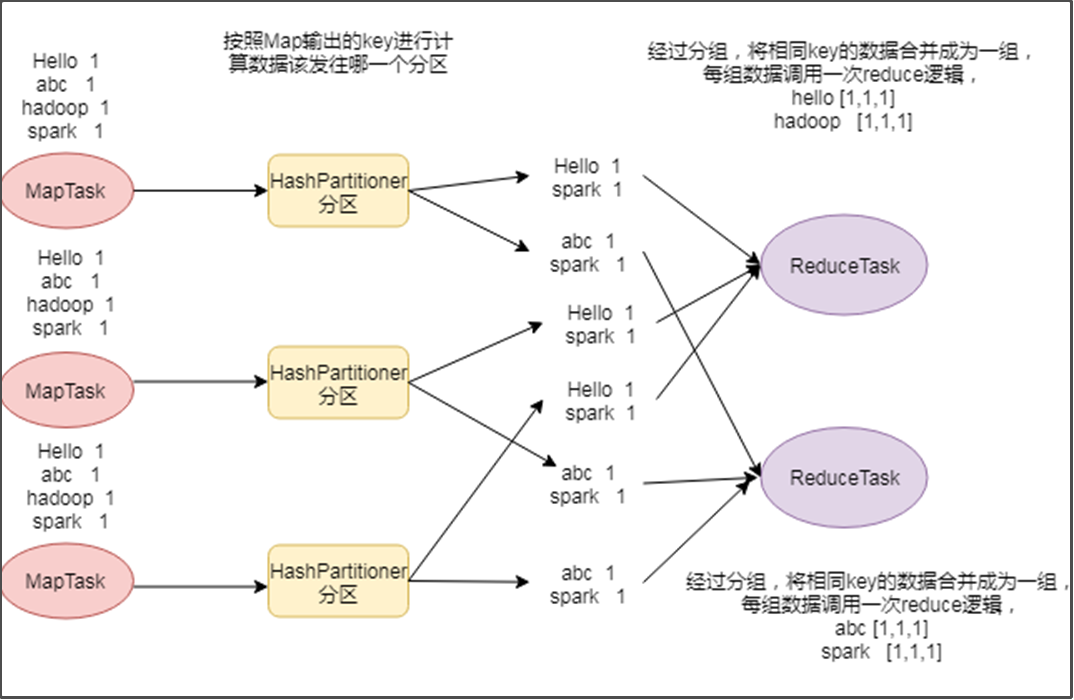
案例需求
基于手机流量数据,实现将不同的手机号的数据划分到不同的文件里面去
135开头的手机号分到一个文件里面去,
136开头的手机号分到一个文件里面去,
137开头的手机号分到一个文件里面去,
138开头的手机号分到一个文件里面去,
139开头的手机号分到一个文件里面去,
其他开头的手机号分到一个文件里面去
案例分析
要将不同手机号数据分到不同文件去,实际上就是分区,将手机号数据分到不同的reducetask处理,然后生成不同的part-r-输出文件。分区等价于将结果输出到不同的part-r-文件。
因此,我们要定义自己分区器(分区类),根据不同开头的手机号返回不同的分区。
要使用我们定义的分区器,还要在job驱动中,将分区器设置为我们自己定义的。
又因为分区个数跟reducetask个数是一致的,所以要根据分区逻辑设置相应个数的reducetask。
步骤1:定义自己的分区逻辑
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class PartitionOwn extends Partitioner<Text, FlowBean> {
@Override
public int getPartition(Text text, FlowBean flowBean, int numPartitions) {
String phoenNum = text.toString();
if(null != phoenNum && !phoenNum.equals("")){
if(phoenNum.startsWith("135")){
return 0;
}else if(phoenNum.startsWith("136")){
return 1;
}else if(phoenNum.startsWith("137")){
return 2;
}else if(phoenNum.startsWith("138")){
return 3;
}else if(phoenNum.startsWith("139")){
return 4;
}else {
return 5;
}
}else{
return 5;
}
}
}
步骤2:定义bean类型的可序列化类型
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class FlowBean implements Writable {
private Integer upFlow;
private Integer downFlow;
private Integer upCountFlow;
private Integer downCountFlow;
/**
* 序列化方法
* @param out
* @throws IOException
*/
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(upFlow);
out.writeInt(downFlow);
out.writeInt(upCountFlow);
out.writeInt(downCountFlow);
}
/**
* 反序列化方法
* @param in
* @throws IOException
*/
@Override
public void readFields(DataInput in) throws IOException {
this.upFlow= in.readInt();
this.downFlow= in.readInt();
this.upCountFlow = in.readInt();
this.downCountFlow = in.readInt();
}
public Integer getUpFlow() {
return upFlow;
}
public void setUpFlow(Integer upFlow) {
this.upFlow = upFlow;
}
public Integer getDownFlow() {
return downFlow;
}
public void setDownFlow(Integer downFlow) {
this.downFlow = downFlow;
}
public Integer getUpCountFlow() {
return upCountFlow;
}
public void setUpCountFlow(Integer upCountFlow) {
this.upCountFlow = upCountFlow;
}
public Integer getDownCountFlow() {
return downCountFlow;
}
public void setDownCountFlow(Integer downCountFlow) {
this.downCountFlow = downCountFlow;
}
@Override
public String toString() {
return "FlowBean{" +
"upFlow=" + upFlow +
", downFlow=" + downFlow +
", upCountFlow=" + upCountFlow +
", downCountFlow=" + downCountFlow +
'}';
}
}
步骤3:定义map逻辑
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class FlowMapper extends Mapper<LongWritable,Text,Text,FlowBean> {
private FlowBean flowBean ;
private Text text;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
flowBean = new FlowBean();
text = new Text();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split("\t");
String phoneNum = split[1];
String upFlow =split[6];
String downFlow =split[7];
String upCountFlow =split[8];
String downCountFlow =split[9];
text.set(phoneNum);
flowBean.setUpFlow(Integer.parseInt(upFlow));
flowBean.setDownFlow(Integer.parseInt(downFlow));
flowBean.setUpCountFlow(Integer.parseInt(upCountFlow));
flowBean.setDownCountFlow(Integer.parseInt(downCountFlow));
context.write(text,flowBean);
}
}
步骤4:定义reduce逻辑
package com.jimmy.day05;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FlowReducer extends Reducer<Text,FlowBean,Text,Text> {
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {
int upFlow = 0;
int donwFlow = 0;
int upCountFlow = 0;
int downCountFlow = 0;
for (FlowBean value : values) {
upFlow += value.getUpFlow();
donwFlow += value.getDownFlow();
upCountFlow += value.getUpCountFlow();
downCountFlow += value.getDownCountFlow();
}
context.write(key,new Text(upFlow +"\t" + donwFlow + "\t" + upCountFlow + "\t" + downCountFlow));
}
}
步骤5:创建组装类和定义main()方法
package com.jimmy.day05;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class FlowMain extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
//获取job对象
Job job = Job.getInstance(super.getConf(), "flowCount");
//如果程序打包运行必须要设置这一句
job.setJarByClass(FlowMain.class);
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path(args[0]));
job.setMapperClass(FlowMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
//关键代码:
//设置要使用的分区类,这里指定我们自己定义的:
job.setPartitionerClass(PartitionOwn.class);
//设置reducetTask的个数,默认值是1;
job.setNumReduceTasks(Integer.parseInt(args[2]));
job.setReducerClass(FlowReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path(args[1]));
boolean b = job.waitForCompletion(true);
return b?0:1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
configuration.set("mapreduce.framework.name","local");
configuration.set("yarn.resourcemanager.hostname","local");
int run = ToolRunner.run(configuration, new FlowMain(), args);
System.exit(run);
}
}
步骤6:运行
打包jar包到集群运行:
hadoop jar original-MrNline-1.0-SNAPSHOT.jar com.jimmy.day05.FlowMain /parinput /paroutput 6
可以看到运行输出了6个part-r文件

思考问题
如果reducetask的个数,跟分区逻辑设置的分区个数不一致,会怎么样?思考下列两个问题:
-
如果手动指定
6个分区,reduceTask个数设置为3个会出现什么情况 -
如果手动指定
6个分区,reduceTask个数设置为9个会出现什么情况
实验:设置不同的reducetask个数来运行jar包
hadoop jar original-MrNline-1.0-SNAPSHOT.jar com.jimmy.day05.FlowMain /parinput /paroutput2 3
//出错了,证明reducetask的个数不能少于分区个数
//---------------------------------------------------------------------------
hadoop jar original-MrNline-1.0-SNAPSHOT.jar com.jimmy.day05.FlowMain /parinput /paroutput3 9
//成功运行,证明reducetask的个数可以大于分区个数
//程序运行成功后,生成了9个part-r-文件,但是part-r-00006到part-r-00008这三个文件,没有任何内容,为空。原因是分区个数小于reducetask个数时,有三个reducetask是不需要处理任何数据的,没有数据传进到那三个reducetask。
//因此,设置过多reducetask没有必要
ReduceTask并行度对Job执行的影响
ReduceTask的并行度个数会影响整个Job的执行并发度和执行效率,但与MapTask的并发数由切片数决定不同,ReduceTask数量的决定是可以直接手动设置:
// 默认值是1,手动设置为4
job.setNumReduceTasks(4);
下面有个实验:测试ReduceTask多少合适
(1)实验环境:1个Master节点,16个Slave节点:CPU:8GHZ,内存: 2G,(数据量为1GB)
(2)实验结论:从下表可知道,reducetask不能太多,得不偿失,也不能太少,效率会较低下。
| MapTask =16 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
ReduceTask |
1 | 5 | 10 | 15 | 16 | 20 | 25 | 30 | 45 | 60 |
| 总时间 | 892 | 146 | 110 | 92 | 88 | 100 | 128 | 101 | 145 | 104 |
Mapreduce--排序(shuffle)
排序
排序是MapReduce框架中最重要的操作之一。
MapTask和ReduceTask均会对数据按照key进行排序。该操作属于Hadoop的默认行为。任何应用程序中的数据均会被排序,而不管逻辑上是否需要。
默认排序是按照字典顺序排序,且实现该排序的方法是快速排序。
对于MapTask,它会将处理的结果暂时放到环形缓冲区中,当环形缓冲区使用率达到一定阈值后,再对缓冲区中的数据进行一次快速排序,并将这些有序数据溢写到磁盘上,而当数据处理完毕后,它会对磁盘上所有文件进行归并排序。
对于ReduceTask,它从每个MapTask上远程拷贝相应的数据文件,如果文件大小超过一定阈值,则溢写磁盘上,否则存储在内存中。如果磁盘上文件数目达到一定阈值,则进行一次归并排序以生成一个更大文件;如果内存中文件大小或者数目超过一定阈值,则进行一次合并后将数据溢写到磁盘上。当所有数据拷贝完毕后,ReduceTask统一对内存和磁盘上的所有数据进行一次归并排序。
排序分类:
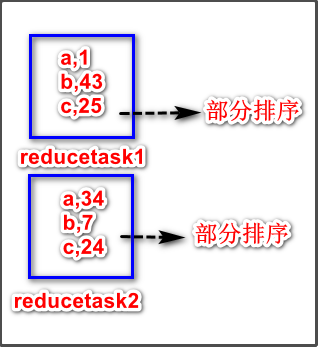
1、部分排序
MapReduce根据输入记录的键对数据集排序。保证输出的每个文件内部有序
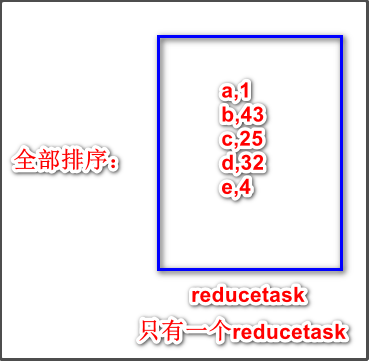
2、全排序
最终输出结果只有一个文件,且文件内部有序。实现方式是只设置一个ReduceTask。但该方法在处理大型文件时效率极低,因为一台机器处理所有文件,完全丧失了MapReduce所提供的并行架构
3、利用分区器实现全部排序
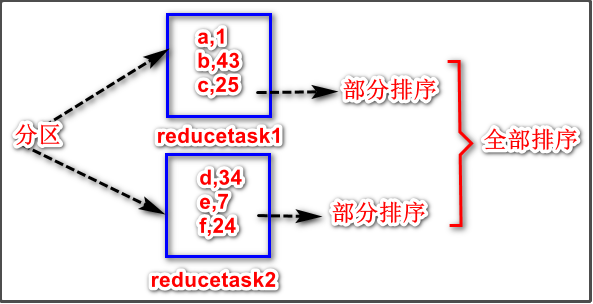
4、辅助排序
在Reduce端对key进行分组。应用于:在接收的key为bean对象时,想让一个或几个字段相同(全部字段比较不相同)的key进入到同一个reduce方法时,可以采用分组排序。
5、二次排序
先按照key中的某个属性(值)进行排序,再按照key中的另一个属性(值)进行排序,这个叫二次排序。在自定义排序过程中,如果compareTo中的判断条件为两个即为二次排序。
案例需求
在前面的序列化当中在数据输出的时候,我们对上行流量,下行流量,上行总流量,下行总流量进行了汇总,汇总结果如下:
//手机号 上行流量 下行流量 上行总流量 下行总流量
13480253104 3 3 180 180
13502468823 57 102 7335 110349
13560439658 33 24 2034 5892
13600217502 18 138 1080 186852
13602846565 15 12 1938 2910
13660577991 24 9 6960 690
13719199419 4 0 240 0
13726230503 24 27 2481 24681
13760778710 2 2 120 120
13823070001 6 3 360 180
13826544101 4 0 264 0
13922314466 12 12 3008 3720
13925057413 69 63 11058 48243
13926251106 4 0 240 0
13926435656 2 4 132 1512
15013685858 28 27 3659 3538
15920133257 20 20 3156 2936
15989002119 3 3 1938 180
18211575961 15 12 1527 2106
18320173382 21 18 9531 2412
84138413 20 16 4116 1432
在上面的数据基础上,我们需要对下行流量,以及上行总流量进行排序,如果下行流量相等就按照上行总流量进行排序(二次排序)。
步骤1:定义可序列化的java bean类
把手机手机号、上行流量、下行流量、上行总流量、下行总流量这5个数据封装到一个Java bean类中,该类要实现WritableComparable接口,表示既是可序列的,又是可排序的。实现该接口后,要重写compareTo()方法,用于排序。
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
//Writable表示可序列化,Comparable表示可排序
public class FlowSortBean implements WritableComparable<FlowSortBean> {
private String phone;
private Integer upFlow;
private Integer downFlow;
private Integer upCountFlow;
private Integer downCountFlow;
//重写compareTo方法,用于排序
@Override
public int compareTo(FlowSortBean o) {
int i = this.downCountFlow.compareTo(o.downCountFlow);
if(i == 0){
//升序:
i = this.upCountFlow.compareTo(o.upCountFlow);
//降序:
//i = -this.upCountFlow.compareTo(o.upCountFlow);
}
return i;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(phone);
out.writeInt(upFlow);
out.writeInt(downFlow);
out.writeInt(upCountFlow);
out.writeInt(downCountFlow);
}
@Override
public void readFields(DataInput in) throws IOException {
this.phone = in.readUTF();
this.upFlow= in.readInt();
this.downFlow= in.readInt();
this.upCountFlow = in.readInt();
this.downCountFlow = in.readInt();
}
@Override
public String toString() {
return phone + "\t" + upFlow + "\t" +downFlow + "\t" + upCountFlow + "\t" + downCountFlow ;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public Integer getUpFlow() {
return upFlow;
}
public void setUpFlow(Integer upFlow) {
this.upFlow = upFlow;
}
public Integer getDownFlow() {
return downFlow;
}
public void setDownFlow(Integer downFlow) {
this.downFlow = downFlow;
}
public Integer getUpCountFlow() {
return upCountFlow;
}
public void setUpCountFlow(Integer upCountFlow) {
this.upCountFlow = upCountFlow;
}
public Integer getDownCountFlow() {
return downCountFlow;
}
public void setDownCountFlow(Integer downCountFlow) {
this.downCountFlow = downCountFlow;
}
}
步骤2:定义map逻辑
package com.jimmy.day06;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* LongWritable:行偏移量
* Text: 一行的内容
* FlowSortBean:封装了手机号等5个数据的自己定义的类的对象
* NullWritable:无
*/
public class FlowSortMapper extends Mapper<LongWritable,Text,FlowSortBean, NullWritable> {
private FlowSortBean flowSortBean;
//初始化:
@Override
protected void setup(Context context) throws IOException, InterruptedException {
flowSortBean = new FlowSortBean();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split("\t");
flowSortBean.setPhone(split[0]);
flowSortBean.setUpFlow(Integer.parseInt(split[1]));
flowSortBean.setDownFlow(Integer.parseInt(split[2]));
flowSortBean.setUpCountFlow(Integer.parseInt(split[3]));
flowSortBean.setDownCountFlow(Integer.parseInt(split[4]));
context.write(flowSortBean,NullWritable.get());
}
}
步骤3:定义reduce逻辑
package com.jimmy.day06;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FlowSortReducer extends Reducer<FlowSortBean, NullWritable,FlowSortBean,NullWritable> {
@Override
protected void reduce(FlowSortBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
步骤4:定义组装类和main()方法
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class FlowSortMain extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
//获取job对象
Job job = Job.getInstance(super.getConf(), "flowSort");
//如果程序打包运行必须要设置这一句
job.setJarByClass(FlowSortMain.class);
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("file:///F://test3//"));
job.setMapperClass(FlowSortMapper.class);
job.setMapOutputKeyClass(FlowSortBean.class);
job.setMapOutputValueClass(NullWritable.class);
job.setReducerClass(FlowSortReducer.class);
job.setOutputKeyClass(FlowSortBean.class);
job.setOutputValueClass(NullWritable.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("file:///F://test2//sortoutput"));
boolean b = job.waitForCompletion(true);
return b?0:1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
int run = ToolRunner.run(configuration, new FlowSortMain(), args);
System.exit(run);
}
}
运行输出结果
13719199419 4 0 240 0
13826544101 4 0 264 0
13760778710 2 2 120 120
13480253104 3 3 180 180
13823070001 6 3 360 180
15989002119 3 3 1938 180
13660577991 24 9 6960 690
84138413 20 16 4116 1432
13926435656 2 4 132 1512
18211575961 15 12 1527 2106
18320173382 21 18 9531 2412
13602846565 15 12 1938 2910
15920133257 20 20 3156 2936
15013685858 28 27 3659 3538
13922314466 12 12 3008 3720
13560439658 33 24 2034 5892
13726230503 24 27 2481 24681
13925057413 69 63 11058 48243
13502468823 57 102 7335 110349
13600217502 18 138 1080 186852
Mapreduce--规约(shuffle)
Conbiner规约
Combiner是MR程序中Mapper和Reducer之外的一种组件。Combiner本质上是一个reduce,因为它的父类是Reducer。Combiner和Reducer的区别在于运行的位置Combiner是在每一个maptask所在的节点运行Reducer是接收全局所有mapper的输出结果
combiner的作用是对每一个maptask的输出进行局部合并汇总,以减少网络传输量combiner能够应用的前提是不能影响最终的业务逻辑,而且Combiner的输出kv对要跟Reducer的输入kv对的类型对应起来。
规约效果示意图(以词频统计为例):
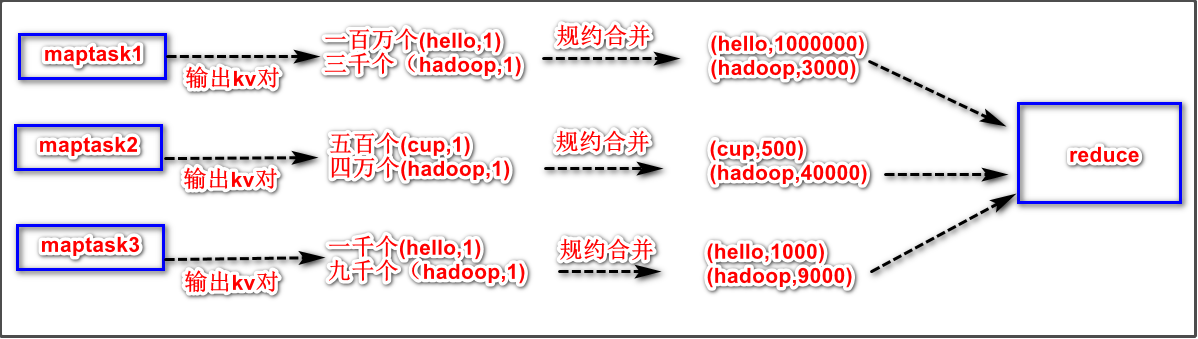
如果没有规约的处理阶段,将是下面的情形:
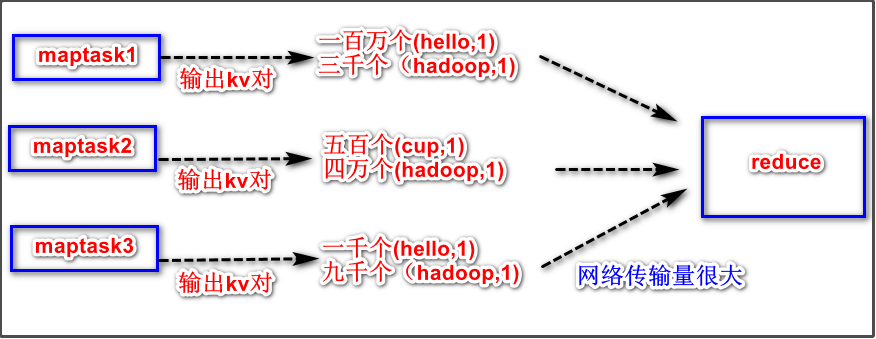
案例需求
对于我们前面的wordCount单词计数统计,我们加上Combiner过程,实现map端的数据进行汇总之后,再发送到reduce端,减少数据的网络拷贝。
步骤1:自定义Combiner类
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MyCombiner extends Reducer<Text, IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//合并求和:
int sum=0;
for (IntWritable value:values){
sum+=value.get();
}
context.write(key,new IntWritable(sum));
}
}
步骤2:自定义map逻辑
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MyMap extends Mapper<LongWritable,Text,Text,IntWritable> {
Text text = new Text();
IntWritable intW = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] split = line.split(",");
for (String word : split) {
text.set(word);
context.write(text,intW);
}
}
}
步骤3:自定义reduce逻辑
package com.jimmy.day07;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MyReduce extends Reducer<Text,IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int result = 0;
for (IntWritable value : values) {
result += value.get();
}
IntWritable intWritable = new IntWritable(result);
context.write(key,intWritable);
}
}
步骤4:定义组装类和main()方法
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class Assem extends Configured implements Tool{
@Override
public int run(String[] args) throws Exception {
Configuration conf = super.getConf();
Job job = Job.getInstance(conf, "mrdemo1");
job.setJarByClass(Assem.class);
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("file:///F://test3//"));
job.setMapperClass(MyMap.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设定规约类为自己定义的类
job.setCombinerClass(MyCombiner.class);
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("file:///F://test2//outr"));
boolean b = job.waitForCompletion(true);
return b?0:1;
}
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
int exitCode= ToolRunner.run(conf,new Assem(),args);
}
}
运行结果
部分运行输出信息如下:

从上图可以看出,规约前record键值对的个数是1132702,规约后输出的record键值对个数为73,极大地减少了要传输地键值对数,减少了网络传输。
Mapreduce--分组(shuffle)
GroupingComparator是mapreduce当中reduce端的一个功能组件,主要的作用是决定哪些数据作为一组,调用一次reduce的逻辑,默认是每个不同的key,作为多个不同的组,每个组调用一次reduce逻辑,我们可以自定义GroupingComparator实现不同的key作为同一个组,调用一次reduce逻辑。
注意:这里说的是每个组调用一次reduce逻辑,可以理解为调用一次reduc()方法,但不要理解为一个reducetask。
分组示意图:
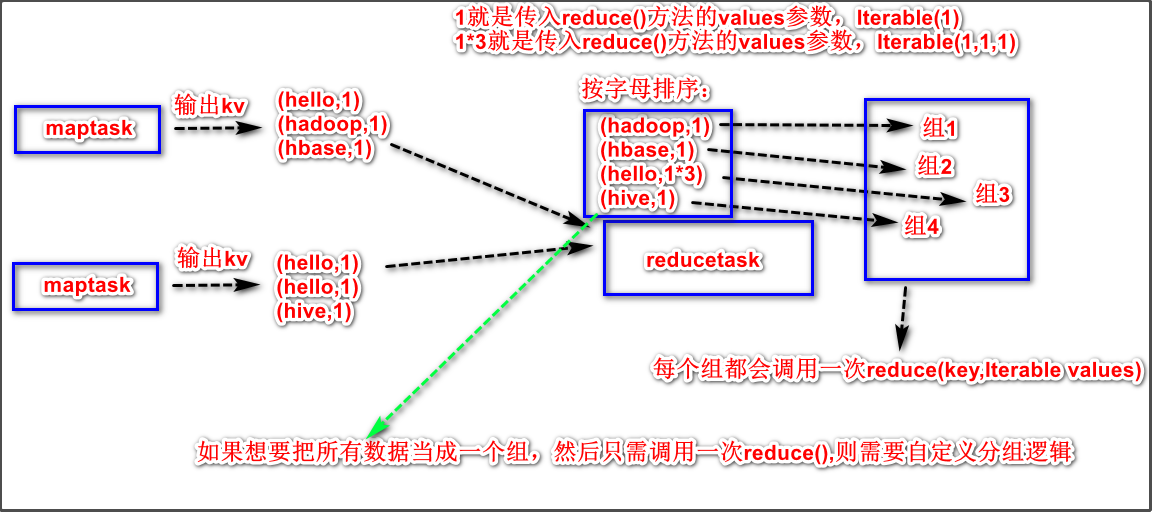
案例需求
现在有订单数据如下:
| 订单id | 商品id | 成交金额 |
|---|---|---|
| Order_0000001 | Pdt_01 | 222.8 |
| Order_0000001 | Pdt_05 | 25.8 |
| Order_0000002 | Pdt_03 | 522.8 |
| Order_0000002 | Pdt_04 | 122.4 |
| Order_0000002 | Pdt_05 | 722.4 |
| Order_0000003 | Pdt_01 | 222.8 |
现在需要求取每个订单当中金额最大的商品id。(不是所有订单)
案例分析
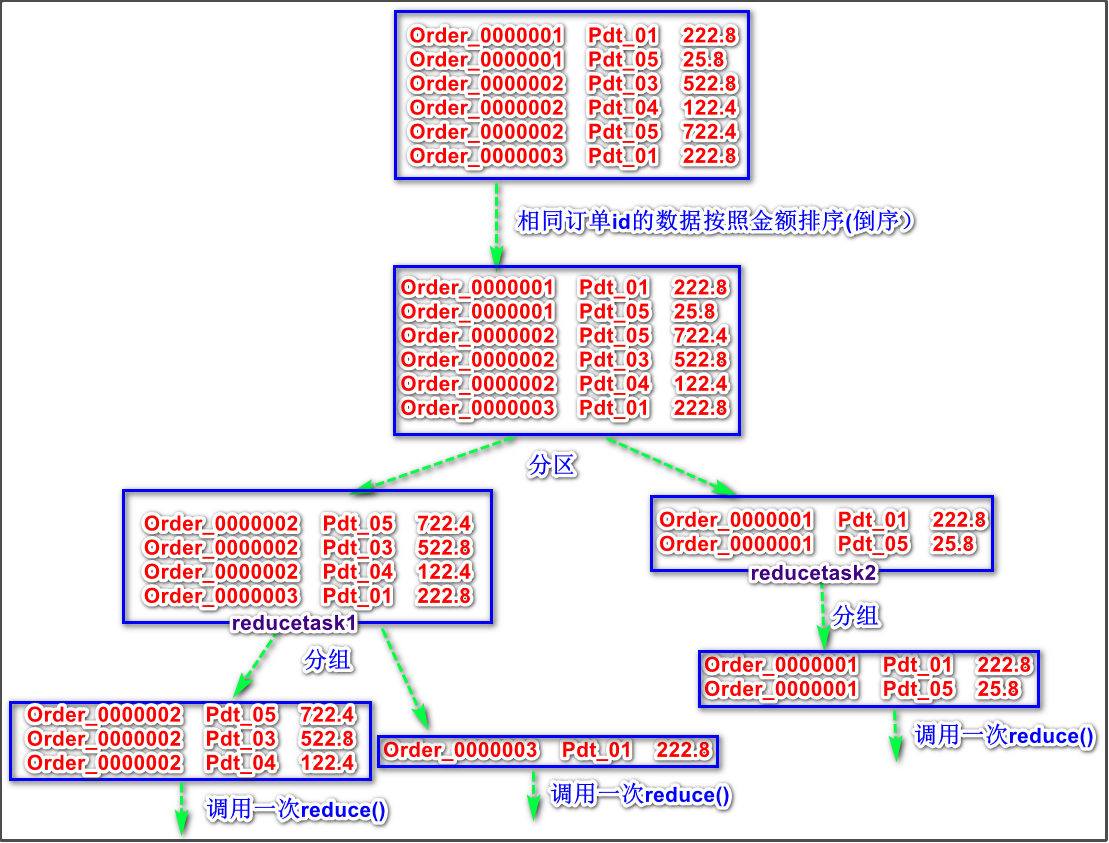
步骤1:创建可序列化可排序的Java bean类
该类是用来封装订单id、商品id、成交金额这三个数据的。
package com.jimmy.day08;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class OrderBean implements WritableComparable<OrderBean> {
private String orderId;
private Double price ;
private String productId;
@Override
public int compareTo(OrderBean o) {
//注意:如果是不同的订单之间,金额不需要排序,没有可比性
int orderIdCompare = this.orderId.compareTo(o.orderId);
if(orderIdCompare == 0){
//比较金额,按照金额进行排序
int priceCompare = this.price.compareTo(o.price);
return -priceCompare;
}else{
//如果订单号不同,没有可比性,直接返回订单号的排序即可
return orderIdCompare;
}
}
/**
* 序列化方法
* @param out
* @throws IOException
*/
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(orderId);
out.writeUTF(productId);
out.writeDouble(price);
}
/**
* 反序列化方法
* @param in
* @throws IOException
*/
@Override
public void readFields(DataInput in) throws IOException {
this.orderId = in.readUTF();
this.productId=in.readUTF();
this.price = in.readDouble();
}
public String getOrderId() {
return orderId;
}
public void setOrderId(String orderId) {
this.orderId = orderId;
}
public Double getPrice() {
return price;
}
public void setPrice(Double price) {
this.price = price;
}
public String getProductId() {
return productId;
}
public void setProductId(String productId) {
this.productId = productId;
}
@Override
public String toString() {
return (orderId + "\t" + productId + "\t" + price);
}
}
步骤2:定义自己的分区类
定义分区类,使用orderId作为分区的条件,保证相同的orderId进入到同一个reduceTask里面去。
这里要注意:虽然进行分区后能够保证相同orderId的数据进入到同一个reduceTask里面去,但是不能保证一个reduceTask里只有一种orderId的数据,有可能有不同orderId的数据。
因此,进行分区后,还要需要定义我们自己的分组类,使orderId相同的数据调用一次reduce()方法。
package com.jimmy.day08;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Partitioner;
public class GroupPartition extends Partitioner<OrderBean, NullWritable> {
@Override
public int getPartition(OrderBean orderBean, NullWritable nullw, int numReduceTasks) {
//(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
//注意这里:使用orderId作为分区的条件,来进行判断,保证相同的orderId进入到同一个reduceTask里面去
return (orderBean.getOrderId().hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
步骤3:定义自己的分组类
该类要继承WritableComparator接口,表示可序列化和可比较的。重写compare()方法
package com.jimmy.day08;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
import java.util.SortedMap;
/**
* 第六步:自定义分组逻辑
* Writable表示可序列化,Comparator表示可比较
*/
public class MyGroup extends WritableComparator {
/**
* 覆写默认构造器,通过反射,构造OrderBean对象
* 通过反射来构造OrderBean对象
* 接受到的key2 是orderBean类型,我们就需要告诉分组,以OrderBean接受我们的参数
*/
public MyGroup(){
//调用父类WritableComparator的有参构造方法,得到一个OrderBean对象
super(OrderBean.class,true);
}
/**
* compare方法接受到两个参数,这两个参数其实就是我们前面传过来的OrderBean
* @param a
* @param b
* @return
*/
@Override
public int compare(WritableComparable a, WritableComparable b) {
//类型强转:
OrderBean first = (OrderBean) a;
OrderBean second = (OrderBean) b;
//以orderId作为比较条件,判断哪些orderid相同作为同一组
return first.getOrderId().compareTo(second.getOrderId());
}
}
步骤4:自定义map逻辑
package com.jimmy.day08;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class GroupMapper extends Mapper<LongWritable,Text,OrderBean,NullWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split("\t");
OrderBean odb = new OrderBean();
odb.setOrderId(split[0]);
odb.setProductId(split[1]);
odb.setPrice(Double.valueOf(split[2]));
context.write(odb, NullWritable.get());
}
}
步骤5:自定义reduce逻辑
package com.jimmy.day08;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class GroupReducer extends Reducer<OrderBean,NullWritable, Text,NullWritable> {
@Override
protected void reduce(OrderBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
Text text=new Text();
text.set(key.getProductId());
context.write(text,NullWritable.get());
}
}
步骤6:定义组装类和Main方法
package com.jimmy.day08;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class GroupMain extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
//获取job对象
Job job = Job.getInstance(super.getConf(), "group");
//第一步:读取文件,解析成为key,value对
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("file:///F://test4//"));
//第二步:自定义map逻辑
job.setMapperClass(GroupMapper.class);
job.setMapOutputKeyClass(OrderBean.class);
job.setMapOutputValueClass(NullWritable.class);
//第三步:分区
job.setPartitionerClass(GroupPartition.class);
//第四步:排序 已经做了
//第五步:规约 combiner 省掉
//第六步:分组 自定义分组逻辑
job.setGroupingComparatorClass(MyGroup.class);
//第七步:设置reduce逻辑
job.setReducerClass(GroupReducer.class);
job.setOutputKeyClass(OrderBean.class);
job.setOutputValueClass(NullWritable.class);
//第八步:设置输出路径
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("file:///F://test2//groupoutput"));
boolean b = job.waitForCompletion(true);
return b?0:1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
int run = ToolRunner.run(new Configuration(), new GroupMain(), args);
System.exit(run);
}
}
案例拓展:
如何求每个分组(根据orderId分组)当中的top2的订单等信息???
输出格式:
Order_0000001 Pdt_01 222.8 222.8
Order_0000001 Pdt_05 25.8 25.8
Order_0000002 Pdt_05 822.4 822.4
Order_0000002 Pdt_04 522.4 522.4
修改map逻辑
package com.jimmy.day09;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MyMap extends Mapper<LongWritable,Text, OrderBean, DoubleWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split("\t");
OrderBean odb = new OrderBean();
odb.setOrderId(split[0]);
odb.setProductId(split[1]);
odb.setPrice(Double.valueOf(split[2]));
//输出kv对:(orderBean , price)
context.write(odb, new DoubleWritable(Double.valueOf(split[2])));
}
}
修改reduce逻辑
package com.jimmy.day09;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MyReduce extends Reducer<OrderBean, DoubleWritable, OrderBean,DoubleWritable> {
@Override
protected void reduce(OrderBean key, Iterable<DoubleWritable> values, Context context) throws IOException, InterruptedException {
//需要对我们集合只输出两个值
int i = 0;
for (DoubleWritable value : values) {
if(i<2){
context.write(key,value);
i ++;
}else{
break;
}
}
}
}
修改分区逻辑
package com.jimmy.day09;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Partitioner;
public class MyPartition extends Partitioner<OrderBean, DoubleWritable> {
@Override
public int getPartition(OrderBean orderBean, DoubleWritable dw, int numReduceTasks) {
//(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
//注意这里:使用orderId作为分区的条件,来进行判断,保证相同的orderId进入到同一个reduceTask里面去
return (orderBean.getOrderId().hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
修改组装类
package com.jimmy.day09;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class RunClass extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
//获取job对象
Job job = Job.getInstance(super.getConf(), "group");
//第一步:读取文件,解析成为key,value对
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("file:///F://test4//"));
//第二步:自定义map逻辑
job.setMapperClass(MyMap.class);
job.setMapOutputKeyClass(OrderBean.class);
job.setMapOutputValueClass(DoubleWritable.class);
//第三步:分区
job.setPartitionerClass(MyPartition.class);
//第四步:排序 已经做了
//第五步:规约 combiner 省掉
//第六步:分组 自定义分组逻辑
job.setGroupingComparatorClass(MyGroup.class);
//第七步:设置reduce逻辑
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(OrderBean.class);
job.setOutputValueClass(DoubleWritable.class);
//第八步:设置输出路径
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("file:///F://test2//groupoutput4"));
boolean b = job.waitForCompletion(true);
return b?0:1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
int run = ToolRunner.run(new Configuration(), new RunClass(), args);
System.exit(run);
}
}
