Hadoop(14)Mapreduce的运行模式
Mapreduce的运行模式
本地模式
我们的上面的案例1的运行模式就是本地模式,mapreduce程序是被提交给LocalJobRunner在本地以单进程的形式运行,输入和输出路径既可以在本地文件系统,也可以在hdfs上。
本地模式非常便于进行业务逻辑的debug,只要在eclipse或IDEA中打断点即可
怎样实现本地运行?
-
写一个程序,不要带集群的配置文件
-
设置参数值:
mapreduce.framework.name=local -
设置参数值:
yarn.resourcemanager.hostname=local
本地模式运行代码设置:
public class MainClass {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapreduce.framework.name","local");
conf.set("yarn.resourcemanager.hostname","local");
//上面这两行代码实际上不写也可以,值默认是local的。
int exitCode = ToolRunner.run(conf, new Assem(), args);
System.exit(exitCode);
}
}
集群运行模式
集群运行模式是将mapreduce程序提交给yarn集群,分发到很多的节点上并发执行,处理的数据和输出结果应该位于hdfs文件系统
提交程序给集群的实现步骤:
1、将程序打成JAR包
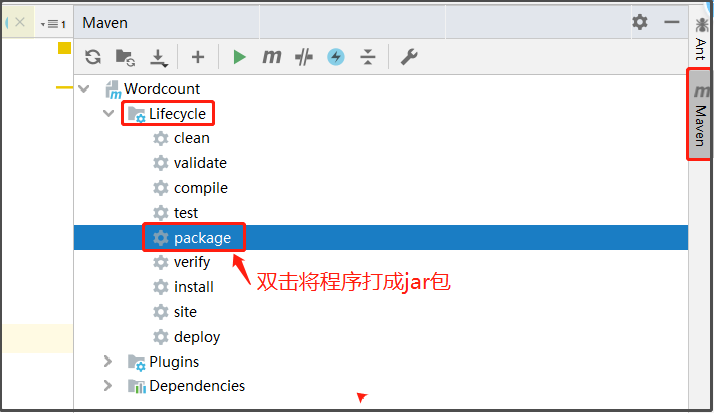
2、将jar包上传到Linux本地文件系统
3、通过JavaApi方式将数据源上传到hdfs文件系统(路径和程序中指定的一致)
4、在集群的任意一个节点上用hadoop或者yarn命令运行jar包。
//运行语法:hadoop jar jar的包名 main方法所在的类的相对路径(不要.java后缀) [参数1...参数2...]
hadoop jar Wordcount-1.0-SNAPSHOT.jar RunClass
或者
yarn jar Wordcount-1.0-SNAPSHOT.jar RunClass
注意事项:
程序中设定的输出路径不能事先存在,而且在填写main方法所在的类的相对路径时,要注意,如下图:
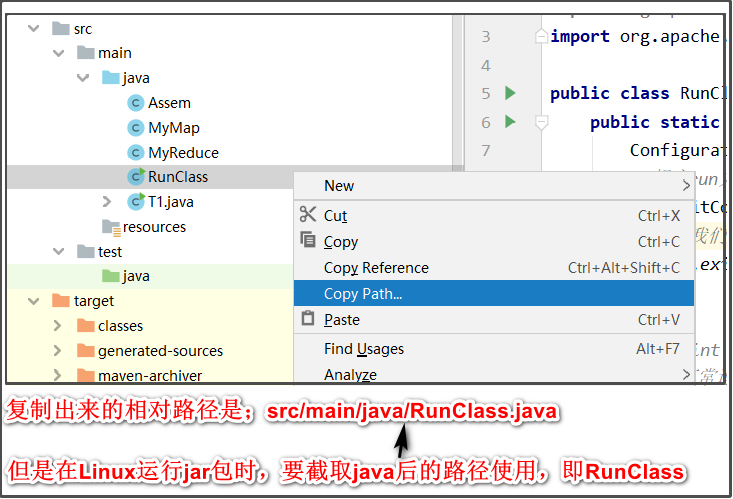
建议使用copy Reference,复制出来直接用,不用截取,不要使用copy Path。
