Hadoop(13)MapReduce编程实现--WordCount
Mapreduce编程实现案例 (wordcount)
案例需求
现有数据格式如下,每一行数据之间都是使用逗号进行分割,求取每个单词出现的次数
hello,hello
world,world
hadoop,hadoop
hello,world
hello,flume
hadoop,hive
hive,kafka
flume,storm
hive,oozie
案例分析
-
确定
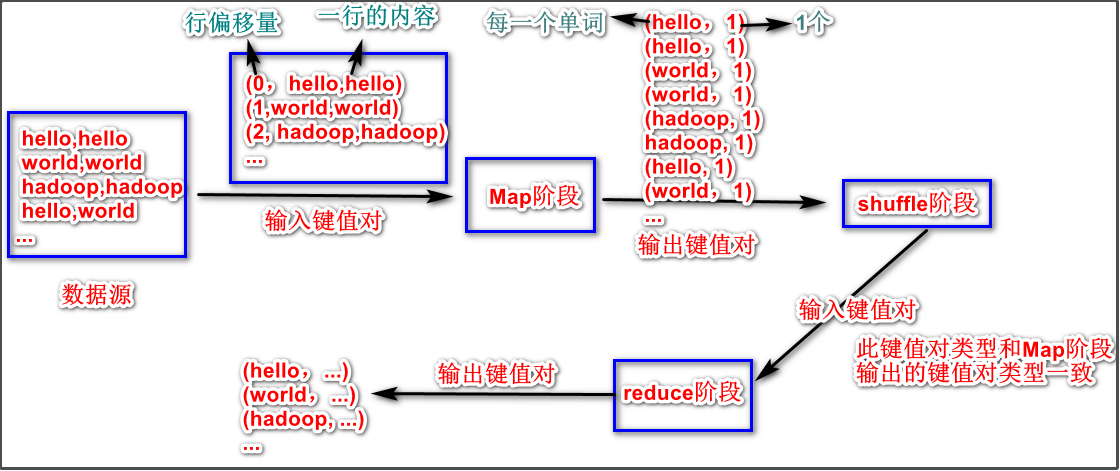
Map阶段的输入和输出的键值对类型,以及确定Reduce阶段的输入和输出键值对类型从下图可以知道,
Map阶段的输入和输出的键值对可序列化类型为:<LongWritable,Text,Text,IntWritable>Reduce阶段的输入和输出键值对类型为:<Text,IntWritable,Text,IntWritable>
步骤1:创建Maven工程
给pom.xml文件添加以下坐标:
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0-mr1-cdh5.14.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0-cdh5.14.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.0-cdh5.14.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.6.0-cdh5.14.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/junit/junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>RELEASE</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
<!-- <verbal>true</verbal>-->
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<minimizeJar>true</minimizeJar>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
步骤2:自定义map逻辑
创建一个继承Mapper类的子类,并重写map()方法。
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
//继承Mapper类,设定输入与输出键值对的泛型
public class MyMap extends Mapper<LongWritable,Text,Text,IntWritable> {
Text text = new Text(); //text为要输出的keyout
IntWritable intW = new IntWritable(1); //inW为要输出的valueout,将每个单词出现都记做1次
//重写map方法,程序每读取一行数据,都会来调用以下map方法
//key: KEYIN
//value: VALUEIN
// context: 上下文对象。承上启下,承接上面步骤发过来的数据,通过context将数据发送到下面的步骤里面去
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//获取我们的一行数据
String line = value.toString(); //Text类重写了toString()方法,作用是将value转换为字符串
String[] split = line.split(","); //分割单词
for (String word : split) {
text.set(word);
//通过context上下文对象将键值对输出到shuffle阶段
context.write(text,intW);
}
}
}
步骤3:自定义reduce逻辑
创建一个继承Ruducer类的子类,并重写reduce()方法。
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MyReduce extends Reducer<Text,IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int result = 0;
for (IntWritable value : values) {
//将我们的结果进行累加
result += value.get();
}
//继续输出我们的数据
IntWritable intWritable = new IntWritable(result);
//将我们的数据输出
context.write(key,intWritable);
}
}
步骤4:编写组装类
创建一个组装类来继承Configured类和实现Tool接口,并重写run()方法,run()方法用于将我们的8大步骤进行组装,每个步骤都是一个类。
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
public class Assem extends Configured implements Tool{
/**
* 实现Tool接口之后,需要实现一个run方法,
* 这个run方法用于组装我们的程序的逻辑,其实就是组装八个步骤
*/
@Override
public int run(String[] args) throws Exception {
//获取Job对象,组装我们的八个步骤
//每一个步骤都是一个class类
Configuration conf = super.getConf();
Job job = Job.getInstance(conf, "mrdemo1");
//实际工作当中,程序运行完成之后一般都是打包到集群上面去运行,打成一个jar包
//如果要打包到集群上面去运行,必须添加以下设置
job.setJarByClass(RunClass.class);
//第一步:读取文件,解析成key,value对,k1:行偏移量 v1:一行文本内容
job.setInputFormatClass(TextInputFormat.class);
//指定我们去哪一个路径读取文件,该路径下的所有文件都会被读取
TextInputFormat.addInputPath(job,new Path("file:///F://test2"));
//如果改成这样:TextInputFormat.addInputPath(job,new Path(args[0]));
//把jar包传到集群运行时就需要传递参数
//第二步:自定义map逻辑,接受k1 v1 转换成为新的k2 v2输出
job.setMapperClass(MyMap.class);
//设置map阶段输出的key,value的类型,其实就是k2 v2的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//第三步到六步:分区,排序,规约,分组都省略(使用默认逻辑)
//第七步:自定义reduce逻辑
job.setReducerClass(MyReduce.class);
//设置key3 value3的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//第八步:输出k3 v3 进行保存
job.setOutputFormatClass(TextOutputFormat.class);
//一定要注意,输出路径是需要不存在的,如果存在就报错
TextOutputFormat.setOutputPath(job,new Path("file:///F://test2//outputResult")); //输出路径可以是本地路径或者hdfs路径
//提交job任务
boolean b = job.waitForCompletion(true);
return b?0:1;
/***
* 第一步:读取文件,解析成key,value对,k1 v1
* 第二步:自定义map逻辑,接受k1 v1 转换成为新的k2 v2输出
* 第三步:分区。相同key的数据发送到同一个reduce里面去,key合并,value形成一个集合
* 第四步:排序 对key2进行排序。字典顺序排序
* 第五步:规约 combiner过程 调优步骤 可选
* 第六步:分组
* 第七步:自定义reduce逻辑接受k2 v2 转换成为新的k3 v3输出
* 第八步:输出k3 v3 进行保存
*/
}
}
步骤5:编写程序入口类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.util.ToolRunner;
public class RunClass {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
//提交run方法之后,得到一个程序的退出状态码
int exitCode = ToolRunner.run(conf, new Assem(), args);
//根据我们 程序的退出状态码,退出整个进程
System.exit(exitCode);
}
}
/*System.exit(int status)用法:
status为0时为正常退出程序,也就是结束当前正在运行中的java虚拟机。
status为非0的其他整数(包括负数,一般是1或者-1),表示非正常退出当前程序
*/
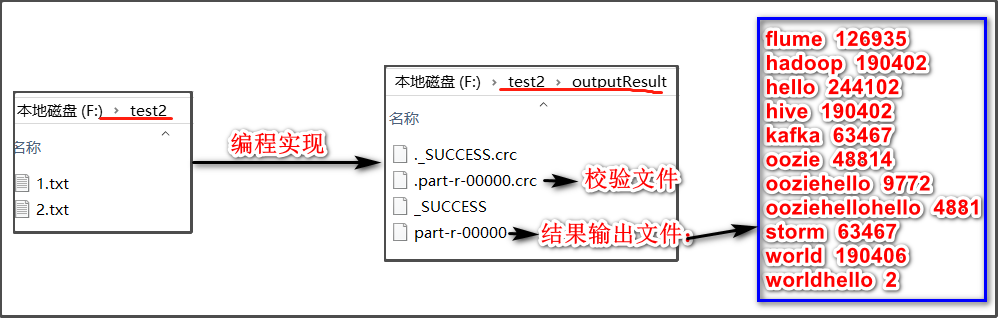
运行效果