Hadoop(12)Mapreduce核心思想、编程模型、编程指导思想(八大步骤)
mapreduce核心思想
MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。
MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。
MapReduce的核心思想是“分而治之”,适用于大量复杂的任务处理场景(大规模数据处理场景)。即使是发布过论文实现分布式计算的谷歌也只是现了这种思想,而不是自己原创。
-
Map负责“分”,即把复杂的任务分解为若干个“简单的任务”来并行处理。可以进行拆分的前提是这些小任务可以并行计算,彼此间几乎没有依赖关系。
-
Reduce负责“合”,即对
map阶段的结果进行全局汇总。
这两个阶段合起来正是MapReduce思想的体现。
通俗解释:
我们要数图书馆中的所有书。你数1号书架,我数2号书架。这就是“Map”。我们人越多,数书就越快。
现在我们到一起,把所有人的统计数加在一起。这就是“Reduce”。
mapreduce编程模型
分而治之--->使用单台服务器无法计算或较短时间内计算出结果时,可将大任务切分成一个个小的任务,小任务分别在不同的服务器上并行的执行,最终再汇总每个小任务的结果。
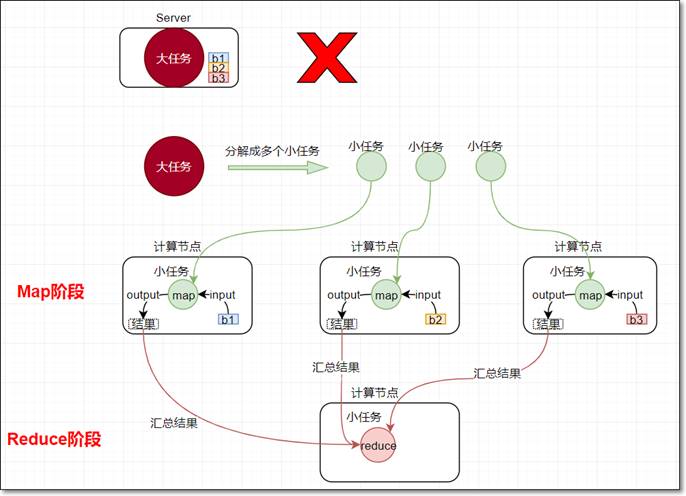
MapReduce由两个阶段组成:
-
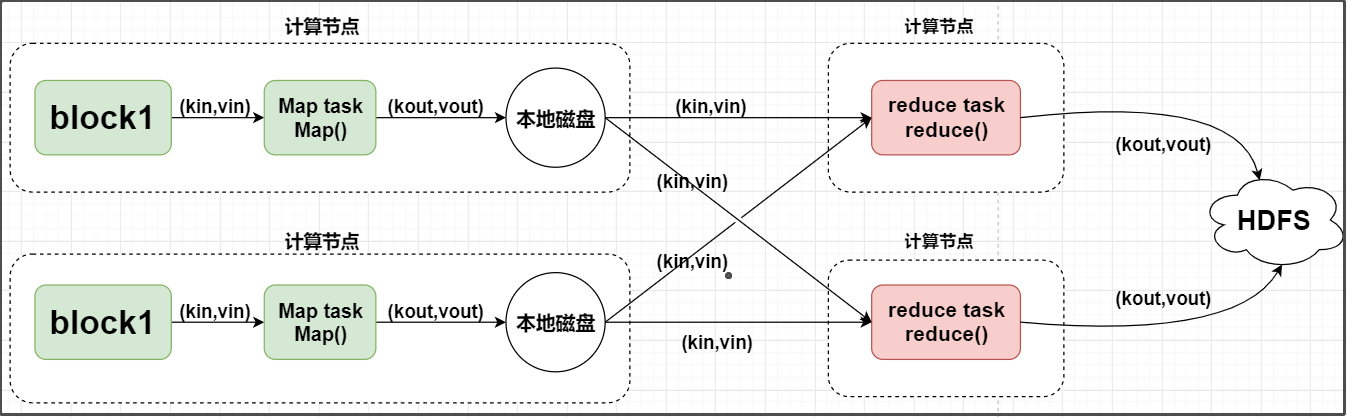
Map阶段(切分成一个个小的任务)map阶段有一个关键的map()方法。- 此方法的输入和输出都是键值对。输出写入本地磁盘。
-
Reduce阶段(汇总小任务的结果)reduce阶段有一个关键的reduce()方法- 此方法的输入也是键值对(即
map的输出(kv对)) - 输出也是一系列键值对,结果最终写入
HDFS
🌈mapreduce编程指导思想(八个步骤背下来)
mapReduce编程模型的总结:
MapReduce的开发一共有八个步骤其中map阶段分为2个步骤,shuffle阶段4个步骤,reduce阶段分为2个步骤
Map阶段2个步骤
第一步:设置inputFormat类,读取我们的数据,将数据切分成key,value对,输入到第二步
第二步:自定义map逻辑,处理我们第一步的输入数据,然后转换成新的key,value对进行输出
shuffle阶段4个步骤
第三步:对输出的key,value对进行分区。相同key的数据发送到同一个reduce task里面去,相同key合并,value形成一个集合
第四步:对不同分区的数据按照相同的key进行排序
第五步:对排序后的数据进行规约(combine操作),降低数据的网络拷贝(可选步骤)
第六步:对排序后的数据进行分组,分组的过程中,将相同key的value放到一个集合当中
reduce阶段2个步骤
第七步:对多个map的任务进行合并,排序,自定义reduce逻辑,对输入的key,value对进行处理,转换成新的key,value对进行输出
第八步:设置outputformat将输出的key,value对数据进行保存到文件中
