Hadoop(7)NameNode和SecondaryNameNode的工作机制
🌈NameNode和SecondaryNameNode的工作机制
如何快速检索元数据?
NameNode主要负责集群当中的元数据信息管理,而且元数据信息需要经常随机访问,因为元数据信息必须高效的检索,那么如何保证namenode快速检索呢??元数据信息保存在哪里能够快速检索呢??如何保证元数据的持久安全呢??
为了保证元数据信息的快速检索,那么我们就必须将元数据存放在内存当中,因为在内存当中元数据信息能够最快速的检索,那么随着元数据信息的增多(每个block块大概占用150字节的元数据信息),内存的消耗也会越来越多。
如何保证元数据持久性?
如果所有的元数据信息都存放内存,服务器断电,内存当中所有数据都消失,为了保证元数据的安全持久,Hadoop集群一开始格式化后就生成了一个edits.log文件和FSImage文件。FSImage是namenode内存中的元数据的镜像文件(备份文件),edits.log文件是记录用户操作信息的日志文件,edits.log文件和FSImage文件都是存放在磁盘里的。

客户端访问hdfs时,操作信息会存到edits.log一份,同时操作产生的元数据也会更新到namenode内存中,fsimage会不定期读取内存中的元数据来更新自己(fsimage每次更新都会生成新的edites.log文件,以后的操作信息将存放到新的edites.log文件)。
若namenode挂掉了,内存中的元数据就会丢失,客户端不能够访问hdfs了。namenode重启时就会从FSImage文件中读取元数据,并回放edits.log日志文件中的用户操作,从而恢复namenode内存中的元数据。用户就可以再次访问hdfs(实际上这段恢复元数据的时间是不可取的,这段时间客户不能访问hdfs)
FSImage随着时间推移,会不断更新文件里的元数据,必然越来越膨胀,FSImage的操作变得越来越难,edits信息也会越来越大,为了解决edits文件膨胀的问题,hadoop当中引入了secondaryNamenode来专门做fsimage与edits文件的合并
SecondaryNameNode出场了(重点)
NN与SNN合作的简略过程
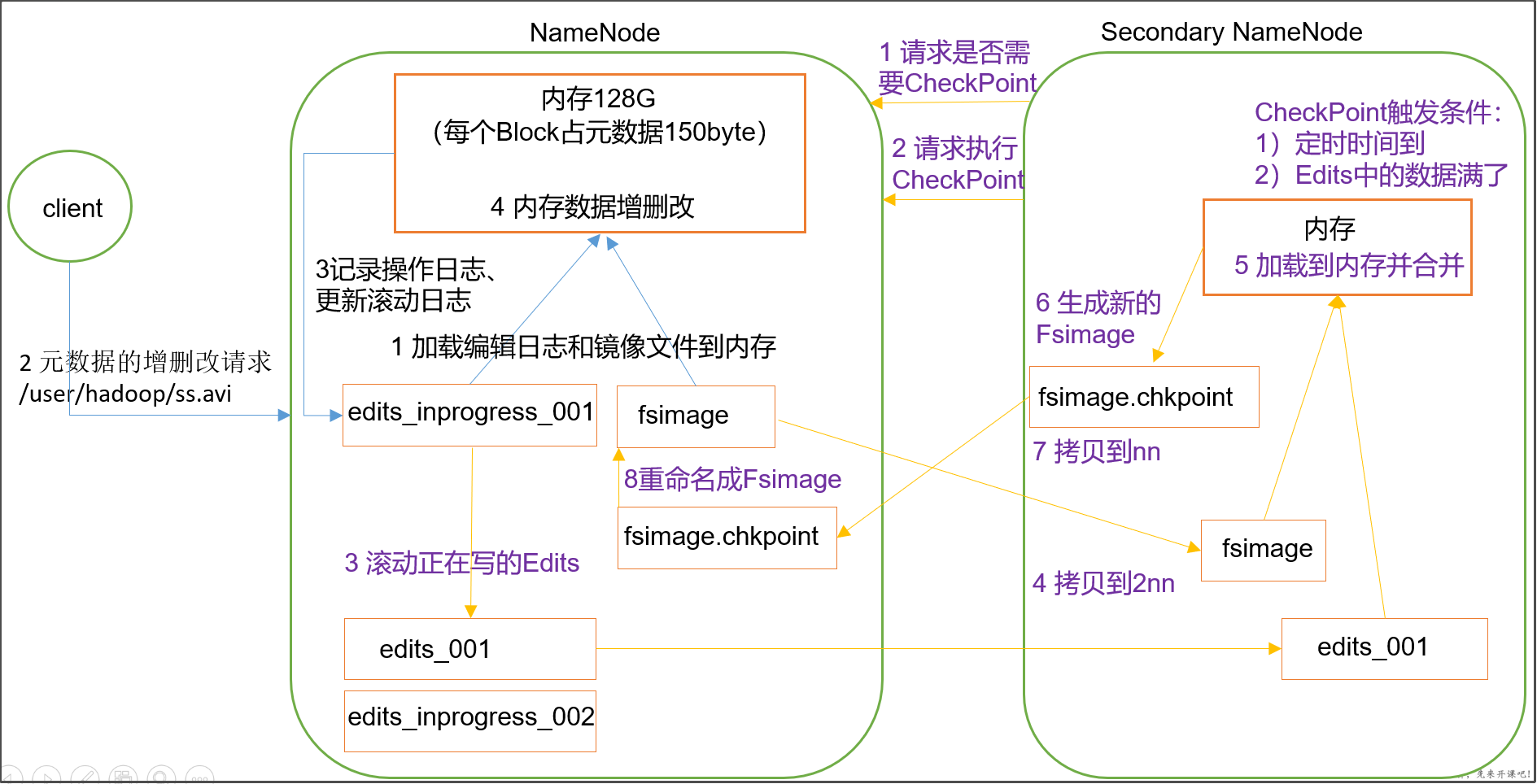
1、namenode工作机制
- 第一次启动namenode格式化后,创建fsimage和edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
- 客户端对元数据进行增删改的请求
- namenode记录操作日志,更新滚动日志。
- namenode在内存中对数据进行增删改查
2、Secondary NameNode工作
- Secondary NameNode询问namenode是否需要checkpoint。直接带回namenode是否检查结果。
- Secondary NameNode请求执行checkpoint。
- namenode滚动正在写的edits日志
- 将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode
- Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
- 生成新的镜像文件fsimage.chkpoint
- 拷贝fsimage.chkpoint到namenode
- namenode将fsimage.chkpoint重新命名成fsimage
NN与SNN合作的详细过程
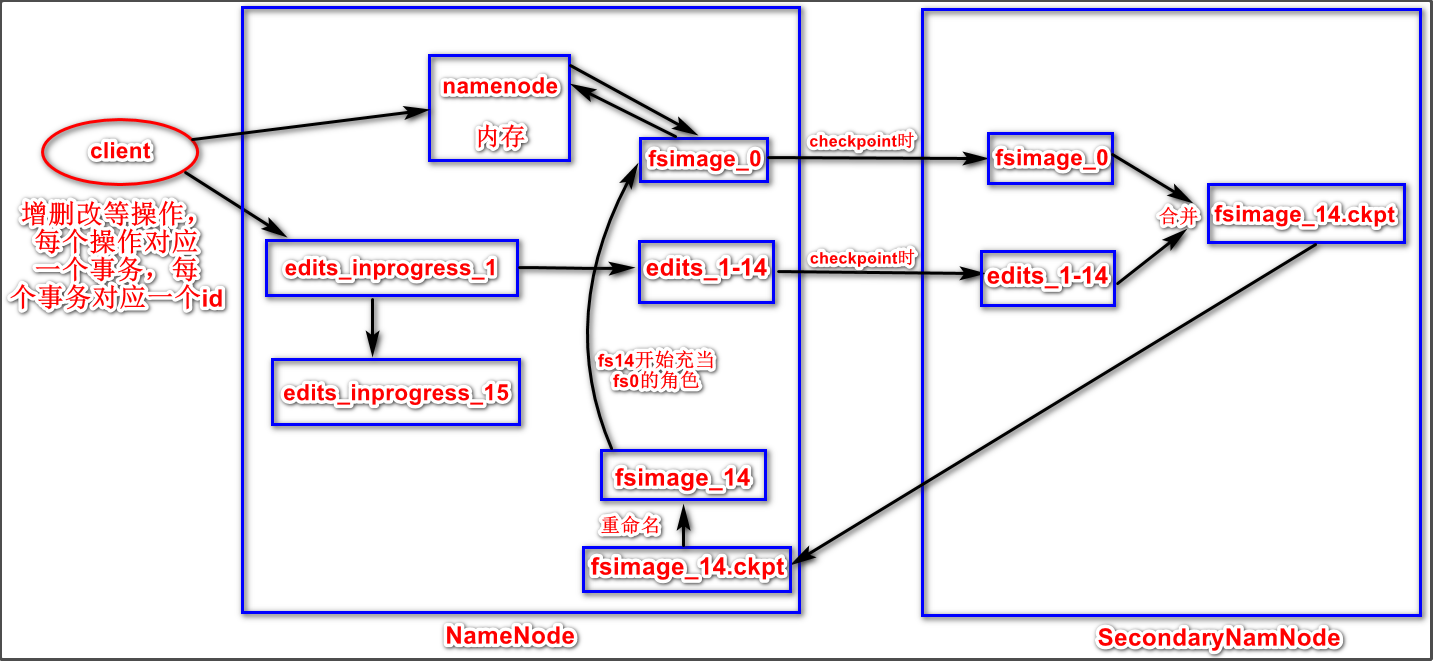
- 客户端对hdfs进行的增删改等操作都对应一个事务,每个事务对应一个id,id是递增的。client操作hdfs时,操作完成会把元数据写入namenode的内存中,也会把新增的操作写入磁盘的edits_inprogress_1日志文件中,_1代表所有新增的操作对应的第一个事务的id号。
- 当checkpoint的时候,namenode会将edits_inprogress_1打包成edits_1-14文件,1-14代表这个文件包含id号为1到14的所有事务。同时还会将根据edits_inprogress_1日志生成新的空的edits_inprogress_15日志文件。15代表新的操作的事务id号将从15开始递增。
- edits_inprogress_15将会充当起edits_inprogress_1的角色,即新增的操作会写入15这个日志文件中。
- SecondaryNameNode会将fsimage_0和edits_1-14拉过去(通过http get方式),对edits_1-14中的操作进行回放,把fsimage_0和edits_1-14合并成新的fsimage_14.ckpt文件。
- 合并完成后,SecondaryNameNode会将fsimage_14.ckpt传回给NameNode,然后再把fsimage_14.ckpt重命名为fsimage_14。fsimage_14不会替换fsimage_0文件,但是会替换它的角色。
- 再次checkpoint的时候,又会重复上述步骤。
补充:
怎么判断要不要checkpoint?checkpoint的条件是什么?
SecondaryNameNode大约每隔一分钟就会查看是否要进行checkpoint,checkpoint的条件是是否距离上次合并过了1小时或者事务条数是否达到100万条。
可以在集群中设置下列三个参数的值来修改checkpoint时机:
- dfs.namenode.checkpoint.period 3600 ---》距离上次合并过了1小时会进行checkpoint
- dfs.namenode.checkpoint.txns 1000000 ----》hdfs操作达到100万次会进行合并
- dfs.namenode.checkpoint.check.period 60 --》每隔一分钟检查hdfs的edits的事务数
加入SecondaryNameNode有什么作用?
- 这样可以保证edits日志文件的记录数始终很少,不会膨胀。
- 大大提高了NameNode的恢复速度
加入SecondaryNameNode后,还有什么问题没有解决?
加入SNN后,并不能解决NameNode一挂掉就停止对外服务的问题,要解决这个问题可以使用ha高可用方案和Zookeeper
对hdfs的操作都放在edits中,为什么不放在fsimage中呢?
因为fsimage是namenode的完整的镜像,内容很大,如果每次都加载到内存的话生成树状拓扑结构,这是非常耗内存和CPU。
fsimage内容包含了namenode管理下的所有datanode中文件及文件block及block所在的datanode的元数据信息。随着edits内容增大,就需要在一定时间点和fsimage合并。
FSImage与edits详解
所有的元数据信息都保存在了FsImage与Eidts文件当中,这两个文件就记录了所有的数据的元数据信息,元数据信息的保存目录配置在了hdfs-site.xml当中
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/namenodeDatas</value>
</property>
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:///kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/nn/edits</value>
</property>
查看FSimage文件当中的文件信息
-
使用命令
hdfs oiv
cd /kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/namenodeDatas/current
hdfs oiv -i fsimage_0000000000000000864 -o hello.xml -p XML
-i fsimage_0000000000000000864 #代表inputFile输入文件
-o hello.xml #代表outputFile,根据fsimage文件生成hello.xml
-p XML #代表文件的打开格式为xml格式
查看edits当中的文件信息
-
查看命令
hdfs oev
cd /kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/nn/edits/current
hdfs oev -i edits_0000000000000000865-0000000000000000866 -o myedit.xml -p XML
vi myedit.xml
NameNode元数据信息多目录配置
为了保证元数据的安全性,我们一般都是先确定好我们的磁盘挂载目录,将元数据的磁盘做RAID1(备份磁盘的中的元数据文件所在的目录,即namenode本地目录)
RAID1的意思是通过磁盘数据镜像实现数据冗余,在成对的独立磁盘上产生互为备份的数据。当原始数据繁忙时,可直接从镜像拷贝中读取数据,因此RAID 1可以提高读取性能。
RAID1是硬盘中单位成本最高的,但提供了很高的数据安全性和可用性,当一个硬盘失效时,系统可以自动切换到镜像硬盘上读/写,并且不需要重组失效的数据。
namenode的本地目录可以配置成多个,且每个目录存放内容相同,增加了可靠性。可通过 hdfs-site.xml配置文件设置:
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///kkb/install/.../hadoopDatas/namenodeDatas,file:///....</value>
</property>
<!--用逗号隔开多个目录-->
NameNode故障恢复(了解就行)
在我们的secondaryNamenode对namenode当中的fsimage和edits进行合并的时候,每次都会先将namenode的fsimage与edits文件拷贝一份过来,所以fsimage与edits文件在secondarNamendoe当中也会保存有一份,如果namenode的fsimage与edits文件损坏,那么我们可以将secondaryNamenode当中的fsimage与edits拷贝过去给namenode继续使用,只不过有可能会丢失一部分数据。这里涉及到几个配置选项
- namenode保存fsimage的配置路径
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/namenodeDatas</value>
</property>
- namenode保存edits文件的配置路径
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:///kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/nn/edits</value>
</property>
- secondaryNamenode保存fsimage文件的配置路径
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/snn/name</value>
</property>
- secondaryNamenode保存edits文件的配置路径
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:///kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/nn/snn/edits</value>
</property>
如果namenode当中的fsimage文件损坏或者丢失,我们可以从secondaryNamenode当中拷贝过去放到对应的路径下即可。具体的步骤如下:
第一步:杀死namenode进程
使用jps查看namenode进程号,然后直接使用kill -9 进程号杀死namenode进程
[hadoop@node01 servers]# jps
127156 QuorumPeerMain
127785 ResourceManager
17688 NameNode
127544 SecondaryNameNode
127418 DataNode
128365 JobHistoryServer
19036 Jps
127886 NodeManager
[hadoop@node01 servers]# kill -9 17688
第二步:删除namenode的fsimage与edits文件
namenode所在机器执行以下命令,删除fsimage与edits文件
删除fsimage与edits文件
rm -rf /kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/namenodeDatas/*
rm -rf /kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/nn/edits/*
第三步:拷贝fsimage与edits文件
将secondaryNameNode所在机器的fsimage与edits文件拷贝到namenode所在的fsimage与edits文件夹下面去,由于我的secondaryNameNode与namenode安装在同一台机器,都在node01上面,node01执行以下命令进行拷贝
cp -r /kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/snn/name/* /kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/namenodeDatas/
cp -r /kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/nn/snn/edits/* /kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/nn/edits
第四步:启动namenode
node01服务器执行以下命令启动namenode
cd hadoop-2.6.0-cdh5.14.2/
sbin/hadoop-daemon.sh start namenode
第五步:浏览器页面正常访问
使用50070端口查看是否正常,http://node01:50070/explorer.html#/
