Hadoop(2)hadoop发展起源、版本、运行模式和架构模块
Hadoop发展起源
-
Hadoop最早起源于Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。 -
2003年、2004年谷歌发表的两篇论文为该问题提供了可行的解决方案。
——分布式文件系统(
GFS),可用于处理海量网页的存储——分布式计算框架
MAPREDUCE,可用于处理海量网页的索引计算问题。 -
Nutch的开发人员利用Java完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目(同年,cloudera公司成立),迎来了它的快速发展期。 -
Hadoop作者Doug Cutting

-
Apache Lucene是一个文本搜索系统库
-
Apache Nutch作为前者的一部分,主要包括web爬虫、全文检索;2003年“谷歌分布式文件系统GFS”论文,2004年开源版本HDFS
-
2004年“谷歌MapReduce”论文,2005年Nutch开源版MapReduce
狭义上来说,hadoop就是单独指代hadoop这个软件
广义上来说,hadoop指代大数据的一个生态圈,包括很多其他的软件
老师话语:
当时doug cutting花了2年的业余时间,写了几十万行的代码,做一个叫做lucene nutch的项目,主要做网络爬虫,从网上爬取海量的网页,存储起来,做一些索引,然后过程中他的团队遇到了两个问题:
- 第一问题:数据量太大,存储面临困难
- 第二个问题:数据量太大,做索引,肯定要计算,面临挑战
然后呢,2003 和2004年,google分别发布了两篇论文:
GFS 论文 ——> 给了他团队灵感,利用Java实现了这篇分布式文件系统的论文 NFS
一开始叫做NFS,是因为是给Nutch这个项目用的。
MapReduce论文 -> MapReduce
NFS + MapReduce 后来将俩者从项目中抽离了出来,=》 形成了现在的hadoop框架
Hadoop版本
hadoop的发展版本
0.x系列版本:hadoop当中最早的一个开源版本,在此基础上演变而来的1.x以及2.x的版本1.x版本系列:hadoop版本当中的第二代开源版本,主要修复0.x版本的一些bug等2.x版本系列:架构产生重大变化,引入了yarn平台等许多新特性,也是现在生产环境当中使用最多的版本。前使用的比较多的还是2.x ,比如2.6 2.7 2.8,很多公司都避免过于激进。3.x版本系列:在2.x版本的基础上,引入了一些hdfs的新特性等,且已经发布了稳定版本,未来公司的使用趋势
hadoop生产环境版本选择
Hadoop三大发行版本:Apache、Cloudera、Hortonworks。
Apache版本最原始(最基础)的版本,对于入门学习最好。
Cloudera在大型互联网企业中用的较多。
Hortonworks文档较好。
Apache Hadoop
Cloudera Hadoop
- 官网地址:https://www.cloudera.com/downloads/cdh/5-10-0.html
- 下载地址:http://archive-primary.cloudera.com/cdh5/cdh/5/
(1)2008年成立的Cloudera是最早将Hadoop商用的公司,为合作伙伴提供Hadoop的商用解决方案,主要是包括支持、咨询服务、培训。
(2)2009年Hadoop的创始人Doug Cutting也加盟Cloudera公司。Cloudera产品主要为CDH,Cloudera Manager,Cloudera Support
(3)CDH是Cloudera的Hadoop发行版,完全开源,比Apache Hadoop在兼容性,安全性,稳定性上有所增强。
(4)Cloudera Manager是集群的软件分发及管理监控平台,可以在几个小时内部署好一个Hadoop集群,并对集群的节点及服务进行实时监控。Cloudera Support即是对Hadoop的技术支持。
(5)Cloudera的标价为每年每个节点4000美元。Cloudera开发并贡献了可实时处理大数据的Impala项目。
Hortonworks Hadoop
- 官网地址:https://hortonworks.com/products/data-center/hdp/
- 下载地址:https://hortonworks.com/downloads/#data-platform
(1)2011年成立的Hortonworks是雅虎与硅谷风投公司Benchmark Capital合资组建。
(2)公司成立之初就吸纳了大约25名至30名专门研究Hadoop的雅虎工程师,上述工程师均在2005年开始协助雅虎开发Hadoop,贡献了Hadoop80%的代码。
(3)雅虎工程副总裁、雅虎Hadoop开发团队负责人Eric Baldeschwieler出任Hortonworks的首席执行官。
(4)Hortonworks的主打产品是Hortonworks Data Platform(HDP),也同样是100%开源的产品,HDP除常见的项目外还包括了Ambari,一款开源的安装和管理系统。
(5)HCatalog,一个元数据管理系统,HCatalog现已集成到Facebook开源的Hive中。Hortonworks的Stinger开创性的极大的优化了Hive项目。Hortonworks为入门提供了一个非常好的,易于使用的沙盒。
(6)Hortonworks开发了很多增强特性并提交至核心主干,这使得Apache Hadoop能够在包括Window Server和Windows Azure在内的Microsoft Windows平台上本地运行。定价以集群为基础,每10个节点每年为12500美元。
注意:Hortonworks已经与Cloudera公司合并
使用情况:
- 中小企业:大部分用
cloudera版本 - 大型公司:有使用
cloudera,也有使用apache hadoop(进行源代码开发)
hadoop的运行模式
Hadoop运行模式包括:本地模式、伪分布式模式以及完全分布式模式。
Hadoop官方网站:http://hadoop.apache.org/
1、 本地运行模式
无需任何守护进程,所有的程序都运行在同一个JVM上执行。在独立模式下调试MR程序非常高效方便。所以一般该模式主要是在学习或者开发阶段调试使用
2、 伪分布式运行模式
Hadoop守护进程运行在本地机器上,模拟一个小规模的集群,换句话说,可以配置一台机器的Hadoop集群,伪分布式是完全分布式的一个特例。
3、完全分布式运行模式(开发重点)
Hadoop守护进程运行在一个集群上,需要使用多台机器来实现完全分布式服务的安装
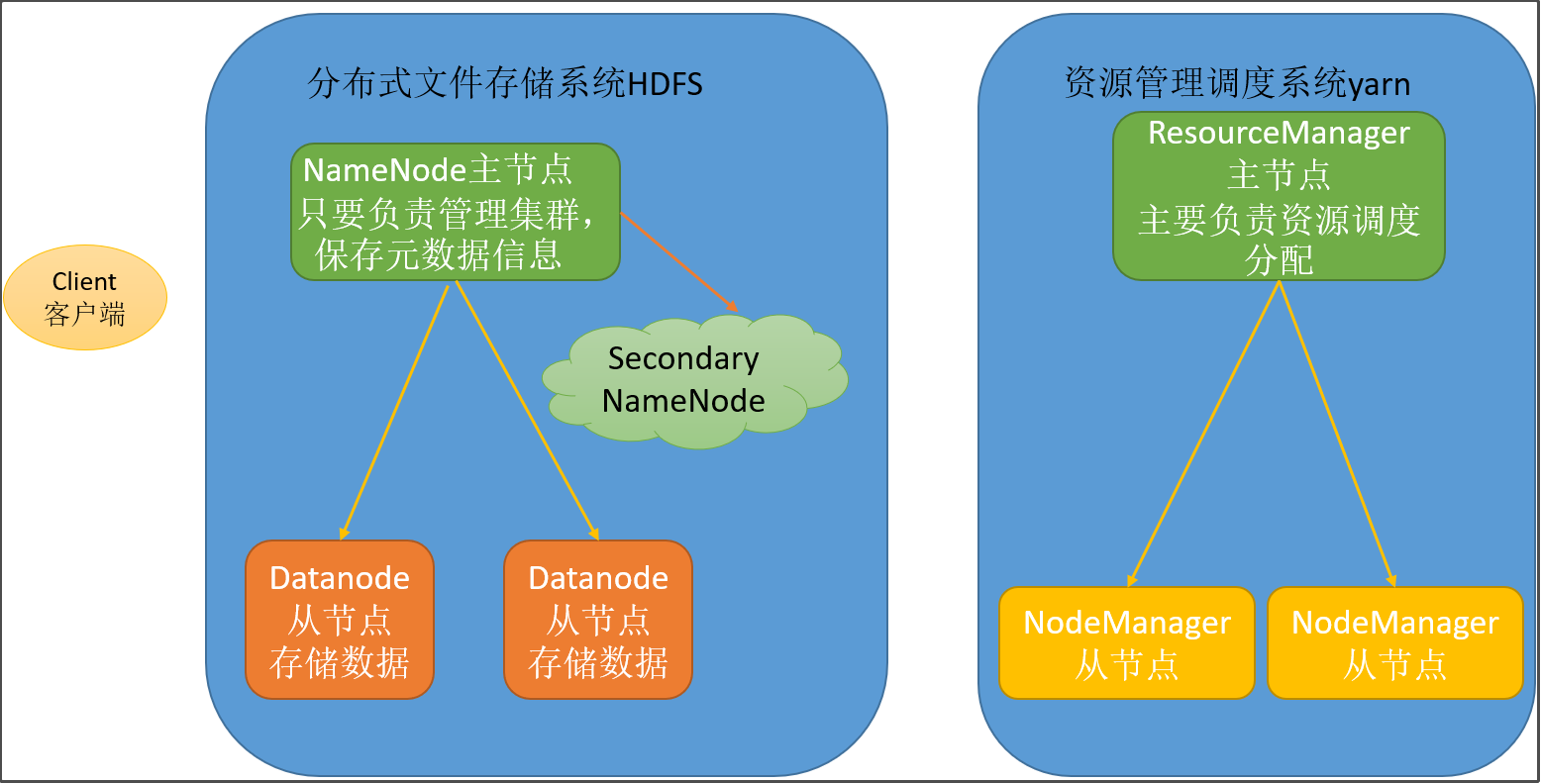
Hadoop架构模块