Hadoop (1)虚拟机搭建hadoop集群
hadoop环境搭建
安装虚拟机
下载镜像文件
下载centOS7镜像文件
新建文件夹
新建用于放置虚拟机上不同系统的文件,方便管理。
新建node01节点
在windows某个盘上创建一个文件夹,用于放置node01节点虚拟机文件。命名可以为:大数据开发环境
开启node01节点
分区选择自动分区,设置root用户密码为node01
配置node01网络
用CRT远程登录node01,修改配置文件/etc/sysconfig/network-scripts/ifcfg-ens33
vi /etc/sysconfig/network-scripts/ifcfg-ens33
BOOTPROTO="static"
IPADDR=192.168.52.101 (要跟虚拟机编辑器网段一样)
NETMASK=255.255.255.0
GATEWAY=192.168.52.2 (要跟虚拟机编辑器设置一样)
DNS1=8.8.8.8
国内用户将DNS改成8.8.8.8只会造成有弊无利的结果,原因就在于这个DNS服务器是企业提供的公用DNS服务器,它由谷歌公司于2009年发布,主要为了替代ISPs或其他公司提供的DNS服务。但其机房在国外,国内无节点!只适合国外用户使用!
推荐使用的DNS服务地址:
114.114.114.114
AliDNS: 223.5.5.5
关闭node01防火墙
systemctl stop firewalld //停止防火墙
systemctl disable firewalld //禁止自启动
关闭node01selinux服务
vim /etc/selinux/config
SELINUX=disabled
更改node01主机名
vim /etc/hostname//(此方法需要重启Linux系统才能生效)
hostnamectl set-hostname node01//(此方法不用重启)
更改node01主机名与ip地址映射
vim /etc/hosts
//添加以下内容
192.168.52.101 node01
192.168.52.102 node02
192.168.52.103 node03
克隆虚拟机
根据node01克隆出node02、node03,克隆方式使用完整克隆,需要node01先关机。
修改node02/03的ip地址
vi /sysconfig/network-scripts/ifcfg-ens33
//node02修改ip为102
IPADDR=192.168.52.102
//node03修改ip为103
IPADDR=192.168.52.103
修改node02/03的主机名
vim /etc/hostname
检查node02/03
检查node02、node03是否确实关闭防火墙和selinux服务了
systemctl status firewalld
vim /etc/selinux/config
三步机器同步时间
同步阿里云时间
yum -y install ntpdate #一定要先安装ntpdate!!!
#使用crt,同时给三个节点发送下列命令
crontab -e
#每个节点都添加以下内容,然后保存退出。
*/1 * * * * /usr/sbin/ntpdate time1.aliyun.com(按i进行编辑)
#内容的意思是每隔一分钟执行一次命令/usr/sbin/ntpdate time1.aliyun.com来更新同步linux的系统时间
#定时更新同步linux的系统时间后,在linux每次关机的时候都会将系统时间同步到硬件时间。date命令查看的是硬件时间。将系统时间同步到硬件时间的命令是hwclock --systohc
时间同步的原理:
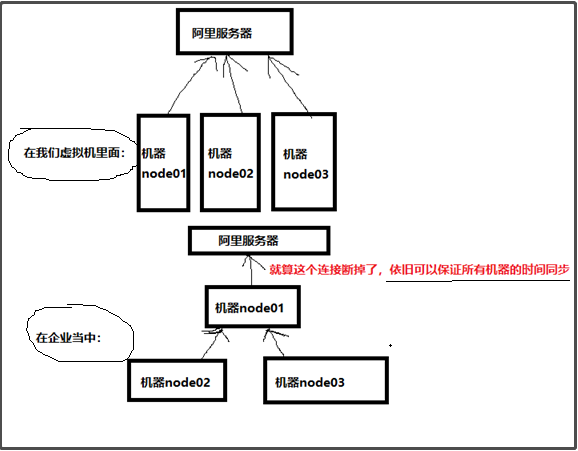
拓展:linux定时任务
linux定时任务的解释:
0 12 * * * mail dmtsai -s "at 12:00" < /home/dmtsai/.bashrc
#分 时 日 月 周 |《==============命令行=======================》|
| 特殊字符 | 代表意义 |
|---|---|
| *(星号) | 代表任何时刻都接受的意思。举例来说,范例一内那个日、月、周都是*,就代表着不论何月、何日的礼拜几的12:00都执行后续命令的意思。 |
| ,(逗号) | 代表分隔时段的意思。举例来说,如果要执行的工作是3:00与6:00时,就会是:0 3,6 * * * command时间还是有五列,不过第二列是 3,6 ,代表3与6都适用 |
| -(减号) | 代表一段时间范围内,举例来说,8点到12点之间的每小时的20分都进行一项工作:20 8-12 * * * command仔细看到第二列变成8-12.代表 8,9,10,11,12 都适用的意思 |
| /n(斜线) | 那个n代表数字,即是每隔n单位间隔的意思,例如每五分钟进行一次,则:/5 * * * * command用与/5来搭配,也可以写成0-59/5,意思相同 |
三台机器添加普通用户
三天机器添加普通用户hadoop,密码设为hadoop,为普通用户添加sudo权限
useradd hadoop
passwd hadoop(密码三台机器都设为hadoop)
为普通用户添加sudo权限:
visudo
root ALL=(ALL) ALL
hadoop ALL=(ALL) ALL
三台机器统一目录
mkdir -p /kkb/soft # 软件压缩包存放目录
mkdir -p /kkb/install # 软件解压后存放目录
chown -R hadoop:hadoop /kkb # 将文件夹权限更改为hadoop用户
hadoop用户免密码登录
A节点免密码远程连接到B节点的原理:
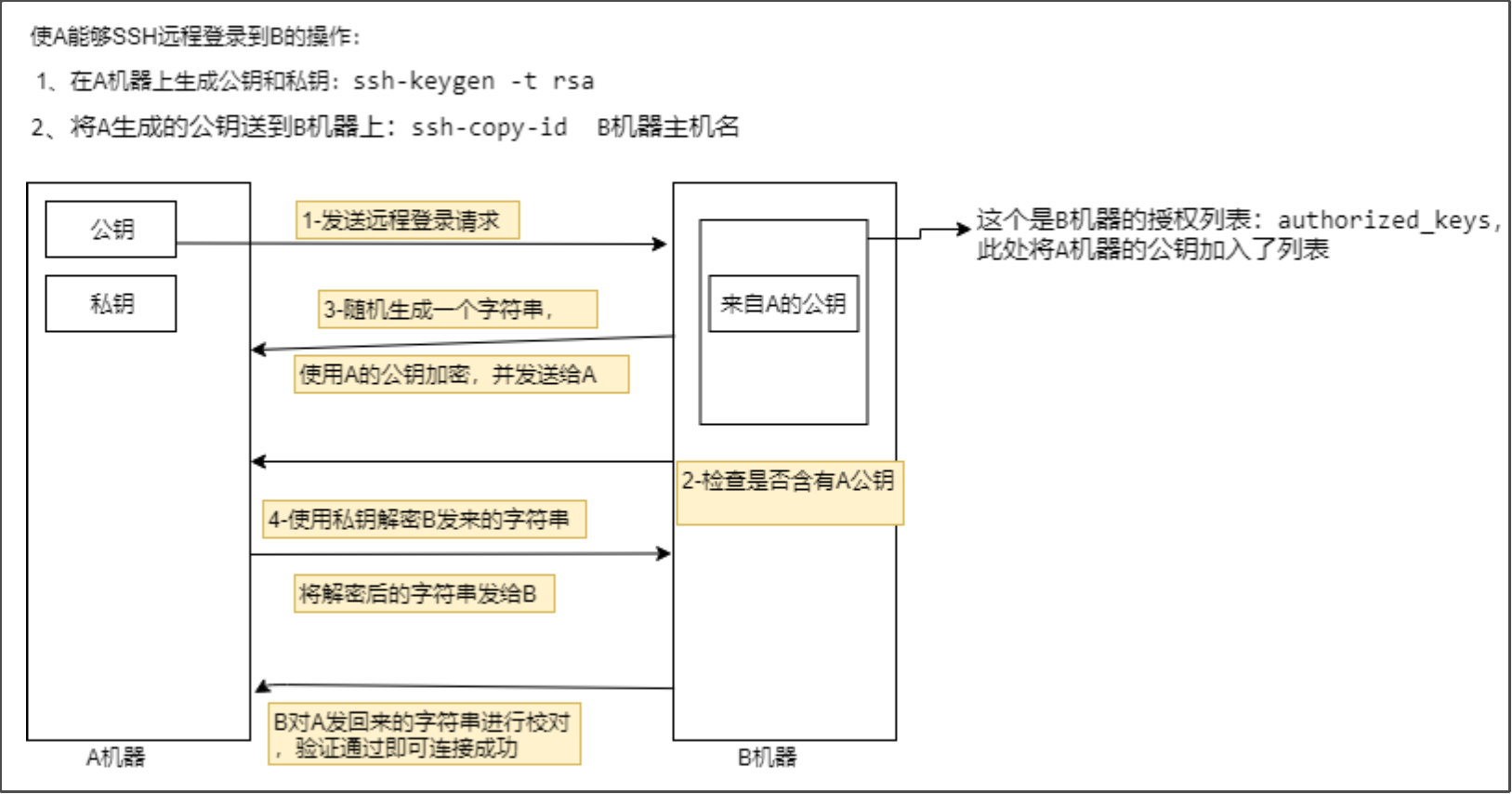
根据上面原理:
每个机器要相互间都能远程免密连接,则都要产生公钥和私钥,并将自身公钥分发到其它所有的机器。
要切换到hadoop用户进行操作 su - hadoop
-
所有机器执行
ssh-keygen -t rsa -
三台机器在
hadoop用户下,执行以下命令将公钥拷贝到node01服务器上面去ssh-copy-id node01 -
node01在hadoop用户下,执行以下命令,将authorized_keys拷贝到node02与node03服务器cd /home/hadoop/.ssh/ scp authorized_keys node02:$PWD scp authorized_keys node03:$PWD
三台机器修改hadoop用户的公钥和私钥的权限

三台机器上传安装包jdk
yum install lrzsz
cd /kkb/soft
rz
tar -zxvf /kkb/soft/jdk-8u141-linux-x64.tar.gz -C /kkb/install/
三台机器配置Java环境变量
vi /home/hadoop/.bash_profile
export JAVA_HOME=/kkb/install/jdk1.8.0_141
export PATH=此处添加 :$JAVA_HOME/bin
source /home/hadoop/.bash_profile
node01上传编译后的安装包hadoop
cd /kkb/soft
rz
tar -zxvf /kkb/soft/ -C /kkb/install/
node01配置Hadoop环境变量
vi /home/hadoop/.bash_profile
export HADOOP_HOME=/kkb/install/
export PATH=此处添加 :$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /home/hadoop/.bash_profile
node01查看hadoop支持的压缩方式以及本地库
cd /kkb/install/hadoop-2.6.0-cdh5.14.2/bin
hadoop checknative
如果出现openssl为false,那么所有机器在线安装openssl即可,执行以下命令,虚拟机联网之后就可 以在线进行安装了: yum -y install openssl-devel
node01配置hadoop配置文件
cd /kkb/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop/
hadoop-env.sh
vi hadoop-env.sh
export JAVA_HOME=/kkb/install/jdk1.8.0_141
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/tempDatas</value>
</property>
<!-- 缓冲区大小,实际工作中根据服务器性能动态调整 -->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!-- 开启hdfs的垃圾桶机制,删除掉的数据可以从垃圾桶中回收,单位分钟 -->
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
<property>
<name>fs.trash.checkpoint.interval</name>
<value>0</value>
</property>
</configuration>
hdfs-site.xml
<!-- NameNode存储元数据信息的路径,实际工作中,一般先确定磁盘的挂载目录,然后多个目录用,进行分割 -->
<!-- 集群动态上下线
<property>
<name>dfs.hosts</name>
<value>/kkb/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop/accept_host</value>
</property>
<property>
<name>dfs.hosts.exclude</name>
<value>/kkb/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop/deny_host</value>
</property>
-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node01:50090</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>node01:50070</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/namenodeDatas</value>
</property>
<!-- 定义dataNode数据存储的节点位置,实际工作中,一般先确定磁盘的挂载目录,然后多个目录用,进行分割 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/datanodeDatas</value>
</property>
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:///kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/nn/edits</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/snn/name</value>
</property>
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:///kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/nn/snn/edits</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node01:19888</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
node01编辑slaves
cd /kkb/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop
vim slaves
node01 //(加入这里不写node01的话,启动集群不会在node01启动datanode,即从节点)
node02
node03
node01创建文件存放目录
mkdir -p /kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/tempDatas
mkdir -p /kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/namenodeDatas
mkdir -p /kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/datanodeDatas
mkdir -p /kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/nn/edits
mkdir -p /kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/snn/name
mkdir -p /kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/nn/snn/edits
分发hadoop安装包
分发node01的hadoop安装包到node02、node03
cd /kkb/install/
scp -r hadoop-2.6.0-cdh5.14.2/ node02:/kkb/isntall/
scp -r hadoop-2.6.0-cdh5.14.2/ node03:/kkb/install/
配置node02/0303的hadoop 环境变量
vi /home/hadoop/.bash_profile
export HADOOP_HOME=/kkb/install/hadoop-2.6.0-cdh5.14.2
export PATH=此处添加 :$HADOOP_HOME/bin:$HADOOP_HOME/sbin
node02/node03安装openssl-devel
sudo yum -y install openssl-devel
格式化hadoop
(只在node01节点格式化,不能重新格式化,只能格式化一次)
要启动 Hadoop 集群,需要启动 HDFS 和 YARN 两个集群。
注意:首次启动HDFS时,必须对其进行格式化操作。本质上是一些清理和准备工作,因为此时的 HDFS 在物理上还是不存在的。
cd /kkb/install/hadoop-2.6.0-cdh5.14.2/bin/
hdfs namenode -format或者hadoop namenode –format
启动集群
单个节点逐一启动
1、在主节点上使用以下命令启动 HDFS NameNode:
hadoop-daemon.sh start namenode
2、在每个从节点上使用以下命令启动 HDFS DataNode:
hadoop-daemon.sh start datanode
3、在主节点上使用以下命令启动 YARN ResourceManager:
yarn-daemon.sh start resourcemanager
4、在每个从节点上使用以下命令启动 YARN nodemanager:
yarn-daemon.sh start nodemanager
脚本一键启动
如果配置了 etc/hadoop/slaves 和 ssh 免密登录,则可以使用程序脚本启动所有Hadoop 两个集群的相关进程,在主节点所设定的机器上执行。
启动集群
node01节点上执行以下命令
cd /kkb/install/hadoop-2.6.0-cdh5.14.2/
sbin/start-dfs.sh
sbin/start-yarn.sh
sbin/mr-jobhistory-daemon.sh start historyserver
停止集群:
sbin/stop-dfs.sh
sbin/stop-yarn.sh
jps查看
主节点需要有:
DataNode
JobHistoryServer
Jps
NodeManager
ResourceManager
SecondaryNameNode
NameNode
从节点需要有:
DataNode
NodeManager
Jps
浏览器查看启动页面
推荐用谷歌访问
hdfs集群访问地址 http://192.168.52.101:50070/dfshealth.html#tab-overview

yarn集群访问地址 http://192.168.52.101:8088/cluster

jobhistory访问地址:http://192.168.52.101:19888/jobhistory
三台机器安装zookeeper集群
注意事项:三台机器一定要保证时钟同步
第一步:下载zookeeeper的压缩包,
下载网址如下
http://archive.cloudera.com/cdh5/cdh/5/
我们在这个网址下载我们使用的zk版本为zookeeper-3.4.5-cdh5.14.2.tar.gz
下载完成之后,上传到我们的node01的/kkb/soft路径下准备进行安装
第二步:解压
node01执行以下命令解压zookeeper的压缩包到node01服务器的/kkb/install路径下去,然后准备进行安装
cd /kkb/soft
tar -zxvf zookeeper-3.4.5-cdh5.14.2.tar.gz -C /kkb/install/
第三步:node01修改配置文件
cd /kkb/install/zookeeper-3.4.5-cdh5.14.2/conf
cp zoo_sample.cfg zoo.cfg
mkdir -p /kkb/install/zookeeper-3.4.5-cdh5.14.2/zkdatas
vim zoo.cfg
dataDir=/kkb/install/zookeeper-3.4.5-cdh5.14.2/zkdatas
autopurge.snapRetainCount=3 #删掉注释
autopurge.purgeInterval=1 #删掉注释
server.1=node01:2888:3888
server.2=node02:2888:3888
server.3=node03:2888:3888
添加myid配置
vi /kkb/install/zookeeper-3.4.5-cdh5.14.2/zkdatas/myid
1
第四步:分发Zookeeper安装包
第一台机器node01上面执行以下两个命令
scp -r /kkb/install/zookeeper-3.4.5-cdh5.14.2/ node02:/kkb/install/
scp -r /kkb/install/zookeeper-3.4.5-cdh5.14.2/ node03:/kkb/instal/
第二台机器上修改myid的值为2
直接在第二台机器任意路径执行以下命令
vi /kkb/install/zookeeper-3.4.5-cdh5.14.2/myid
2
(一定要正确,否则后面会出错)
第三台机器上修改myid的值为3
直接在第三台机器任意路径执行以下命令
vi /kkb/install/zookeeper-3.4.5-cdh5.14.2/myid
3
(一定要正确,否则后面会出错)
拓展:配置zookeeper环境变量
所有节点:
vi /home/hadoop/.bash_profile
export ZOOKEEPER_HOME=/kkb/install/zookeeper-3.4.5-cdh5.14.2
export PATH=....:ZOOKEEPER_HOME/bin
source /home/hadoop/.bash_profile
第五步:三台机器启动zookeeper服务
这个命令三台机器都要执行
/kkb/install/zookeeper-3.4.5-cdh5.14.2/bin/zkServer.sh start
第六步:查看启动状态
/kkb/install/zookeeper-3.4.5-cdh5.14.2/bin/zkServer.sh status
出现类似下列信息时表示正常开启:
JMX enabled by default
Using config: /kkb/install/zookeeper-3.4.5-cdh5.14.2/bin/../conf/zoo.cfg
Mode: leader
搭建完并启动zookeeper集群后,执行jps会出现QuorumPeerMain
运行mapreduce程序(在node01上操作)
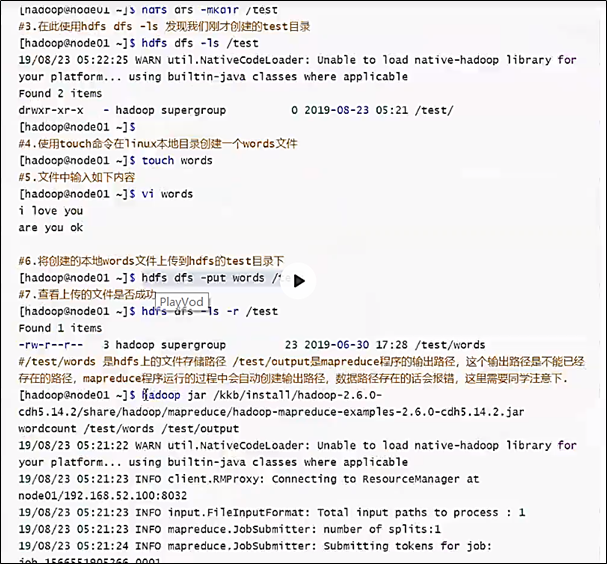
hdfs dfs -mkdir /test
hdfs dfs -ls /test
touch /home/hadoop/words
cd
vi words
cat words
hdfs dfs -put /home/hadoop/words /test
hdfs dfs -ls -r /test
hadoop jar /kkb/install/hadoop-2.6.0-cdh5.14.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.14.2.jar wordcount /test/words /test/output
hdfs dfs -text /test/output/part-r-00000
hdfs dfs -ls /test/output/
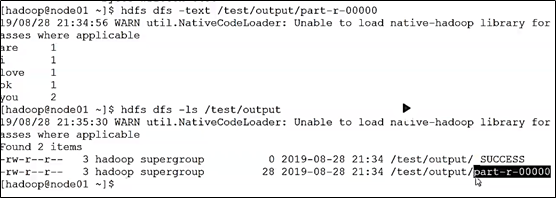
尝试下载part-r-00000
使用浏览器访问192.168.52.101:50070
进到文件系统页面找到文件下载即可(这步有可能下载出错导致下载不成功,这时候就要进行下一步,即配置Windows的hosts配置文件)
配置windows的hosts文件
(管理员身份)修改windows的文件C:/windows/system32/drivers/etc/hosts
添加下列内容:
192.168.52.101 node01
192.168.52.102 node02
192.168.52.103 node03
修改完以后就可以使用node01:50070登录
创建用来方便操作的脚本
node01在/home/hadoop/bin/下创建hadoop.sh xcall xsync三个脚本文件node02和node03只在/home/hadoop/bin创建xcall- 执行以下操作:
chmod 777 /home/hadoop/bin/xcall
chmod 777 /home/hadoop/bihadoop.sh
vi /home/hadoop/.bash_profile
export MY_HOME=/home/hadoop/
PATH=$PATH:$HOME/.local/bin:$HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin:$MY_HOME/bin
查看效果:
[hadoop@node01 bin]$ xcall jps
============= node01 jps =============
27395 DataNode
27270 NameNode
27799 NodeManager
27544 SecondaryNameNode
29195 QuorumPeerMain
28172 JobHistoryServer
27679 ResourceManager
29599 Jps
============= node02 jps =============
17698 NodeManager
19155 Jps
18908 QuorumPeerMain
17598 DataNode
============= node03 jps =============
19376 Jps
17686 DataNode
19128 QuorumPeerMain
17786 NodeManager
