spark(23)sparksql 操作hivesql、操作JDBC数据源、保存数据到不同类型文件
sparksql 操作hivesql
添加依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.3.3</version>
</dependency>
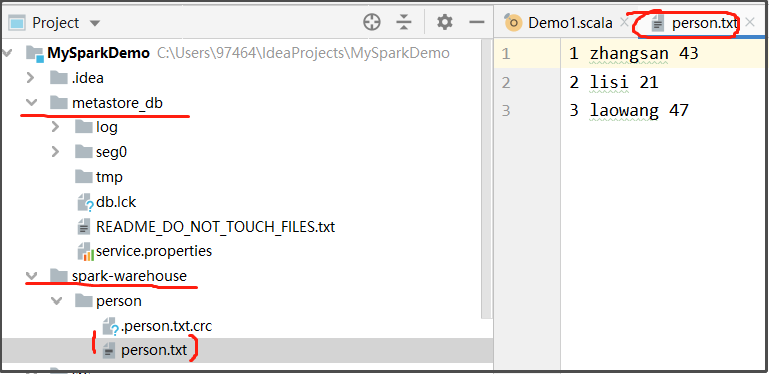
person.txt
1 zhangsan 43
2 lisi 21
3 laowang 47
Demo1.scala
import org.apache.spark.sql.SparkSession
object Demo1 {
def main(args: Array[String]): Unit = {
//注意:要开启对hive的支持:.enableHiveSupport()
val spark=SparkSession.builder().appName("spark sql control hive sql").master("local[2]").enableHiveSupport().getOrCreate()
val sc=spark.sparkContext
sc.setLogLevel("Warn")
spark.sql(
"""
|create table if not exists person(id string,name string,age int)
|row format delimited fields terminated by " "
|""".stripMargin) //stripMargin的作用是将 | 变成空格
spark.sql("load data local inpath 'file:///F:/test/person.txt' into table person")
spark.sql("select * from person").show()
spark.stop()
}
}
运行结果为:
+---+--------+---+
| id| name|age|
+---+--------+---+
| 1|zhangsan| 43|
| 2| lisi| 21|
| 3| laowang| 47|
+---+--------+---+
说明:
- 文件的路径一定要加上file:///,否则会报错
- 运行成功后,会在当前project的根目录下创建两个目录:metastore_db和spark-warehouse
- metastore_db用于存放刚才在本地创建的表的元数据,spark-warehouse用于保存表的数据
spark sql 操作JDBC数据源(★★★★★)
spark sql可以通过 JDBC 从关系型数据库中读取数据的方式创建DataFrame,通过对DataFrame一系列的计算后,还可以将数据再写回关系型数据库中
通过sparksql加载mysql表中的数据
在node03创建表,准备数据
mysql> create database spark;
mysql> use spark;
mysql> create table user(id int,name varchar(15),age int);
mysql> insert into user(id,name,age) values(1,'krystal',21),(2,'jimmy',22);
mysql> select * from user;
+------+---------+------+
| id | name | age |
+------+---------+------+
| 1 | krystal | 21 |
| 2 | jimmy | 22 |
+------+---------+------+
2 rows in set (0.11 sec)
添加mysql连接驱动jar包
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
开发代码:
import java.util.Properties
import org.apache.spark.sql.{DataFrame, SparkSession}
object Demo2 {
def main(args: Array[String]): Unit = {
val spark=SparkSession.builder().appName("demo").master("local[2]").getOrCreate()
val url="jdbc:mysql://node03:3306/spark"
val tableName="user"
val properties=new Properties()
properties.setProperty("user","root")
properties.setProperty("password","123456")
val mysqlDF:DataFrame=spark.read.jdbc(url,tableName,properties)
mysqlDF.printSchema()
mysqlDF.show()
mysqlDF.createTempView("user")
spark.sql("select * from user")
spark.stop()
}
}
运行结果为:
root
|-- id: integer (nullable = true)
|-- name: string (nullable = true)
|-- age: integer (nullable = true)
+---+-------+---+
| id| name|age|
+---+-------+---+
| 1|krystal| 21|
| 2| jimmy| 22|
+---+-------+---+
通过sparksql保存结果数据到mysql表中(本地)
继续往user表插入数据:
mysql> use spark
mysql> insert into user(id,name,age) values(3,'zhangsan',34),(4,'lisi',46);
mysql> select * from user;
+------+----------+------+
| id | name | age |
+------+----------+------+
| 1 | krystal | 21 |
| 2 | jimmy | 22 |
| 3 | zhangsan | 34 |
| 4 | lisi | 46 |
+------+----------+------+
4 rows in set (0.00 sec)
代码开发(本地运行)
import java.util.Properties
import org.apache.spark.sql.{DataFrame, SparkSession}
object Demo2 {
def main(args: Array[String]): Unit = {
val spark=SparkSession.builder().appName("demo").master("local[2]").getOrCreate()
val url="jdbc:mysql://node03:3306/spark"
val tableName="user"
val properties=new Properties()
properties.setProperty("user","root")
properties.setProperty("password","123456")
val mysqlDF:DataFrame=spark.read.jdbc(url,tableName,properties)
mysqlDF.createTempView("user")
val resultDF:DataFrame=spark.sql("select * from user where age > 30")
resultDF.write.mode("append").jdbc(url,"user2",properties)
spark.stop()
}
}
查询user2表:
mysql> select * from user2;
+------+----------+------+
| id | name | age |
+------+----------+------+
| 3 | zhangsan | 34 |
| 4 | lisi | 46 |
+------+----------+------+
说明:
- resultDF.wirte.mode("...")的参数有四种,mode用来指定数据的插入模式。
//overwrite: 表示覆盖,如果表不存在,事先帮我们创建
//append :表示追加, 如果表不存在,事先帮我们创建
//ignore :表示忽略,如果表事先存在,就不进行任何操作
//error :如果表事先存在就报错(默认选项) - 将数据处理后保存到MySQL中,还可以使用rdd方法,详情查看spqrk.md
- 如果要将本地运行改成打jar包到集群运行,只需要修改2个地方:
- 删掉.master()
- 将resultDF.write.mDFode(args(0)).jdbc()的第2个参数设为args(1)
通过sparksql保存结果数据到mysql表中(集群)
import java.util.Properties
import org.apache.spark.sql.{DataFrame, SparkSession}
object Demo2 {
def main(args: Array[String]): Unit = {
val spark=SparkSession.builder().appName("demo").getOrCreate()
val url="jdbc:mysql://node03:3306/spark"
val tableName="user"
val properties=new Properties()
properties.setProperty("user","root")
properties.setProperty("password","123456")
val mysqlDF:DataFrame=spark.read.jdbc(url,tableName,properties)
mysqlDF.createTempView("user")
val resultDF:DataFrame=spark.sql("select * from user where age > 30")
resultDF.write.mode("append").jdbc(url,args(1),properties)
spark.stop()
}
}
提交任务脚本
spark-submit \
--master spark://node01:7077 \
--class com.kaikeba.sql.Data2Mysql \
--executor-memory 1g \
--total-executor-cores 4 \
--driver-class-path /home/hadoop/jars/mysql-connector-java-5.1.38.jar \
--jars /home/hadoop/jars/mysql-connector-java-5.1.38.jar \
original-spark_class05-1.0-SNAPSHOT.jar \
append t_kaikeba
--driver-class-path:指定一个Driver端所需要的额外jar
--jars :指定executor端所需要的额外jar
sparksql 保存数据到不同类型文件
创建F:\test\score.json文件:
{"name":"zhangsan1","classNum":"10","score":90}
{"name":"zhangsan11","classNum":"10","score":90}
{"name":"zhangsan2","classNum":"10","score":80}
{"name":"zhangsan3","classNum":"10","score":95}
{"name":"zhangsan4","classNum":"20","score":90}
{"name":"zhangsan5","classNum":"20","score":91}
{"name":"zhangsan6","classNum":"20","score":86}
{"name":"zhangsan7","classNum":"20","score":78}
{"name":"zhangsan8","classNum":"30","score":60}
{"name":"zhangsan9","classNum":"30","score":88}
{"name":"zhangsan10","classNum":"30","score":95}
代码开发:
import java.util.Properties
import org.apache.spark.sql.{DataFrame, SparkSession}
object Demo3 {
def main(args: Array[String]): Unit = {
val spark=SparkSession.builder().appName("demo").master("local[2]")getOrCreate()
val dataDF:DataFrame=spark.read.json("file:///F:/test/score.json")
//处理数据:
dataDF.createTempView("tableDemo")
val result=spark.sql("select * from tableDemo where score > 80")
//保存数据:
result.write.json("file:///F:/test/out_json")
result.write.parquet("file:///F:/test/out_parquet")
result.write.save("file:///F:/test/out_save")
result.write.csv("file:///F:/test/out_csv")
result.write.saveAsTable("t1")
result.write.partitionBy("classNum").json("file:///F:/test/out_partition_json")
result.write.partitionBy("classNum","name").json("file:///F:/test/out_partition2_json")
spark.stop()
}
}
说明:
- out_xxx等都是目录来的,而且是由程序来创建,不需要事先创建,否则报错
- write.save()默认保存为parquet格式
- 经过partitionBy分区后保存的数据文件如下:

- result.write.saveAsTable("t1")保存表t1在spark-warehouse目录下: