spark(22)把RDD转换为DataFrame(IDEA)
通过IDEA开发程序实现把RDD转换DataFrame
官网学习如何创建spark sql Scala程序
添加依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.3.3</version>
</dependency>
方法1:利用反射机制
定义一个样例类,后期直接映射成DataFrame的schema信息。
case class Person(id:String,name:String,age:Int)
适用场景:在开发代码之前,可以先确定好DataFrame的schema元信息
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{Column, SparkSession}
case class Person(id:String,name:String,age:Int)
object SparkSqlDemo {
def main(args: Array[String]): Unit = {
//1、创建SparkSession
val spark=SparkSession.builder().appName("SparkSqlDemo1").master("local[2]").getOrCreate()
val sc=spark.sparkContext
val data:RDD[Array[String]]=sc.textFile("F:\\test\\person.txt").map(x=>x.split(" "))
//将样例类与RDD关联,即RDD[Array[String]]---->RDD[Person]
val personRDD:RDD[Person]=data.map(x=>Person(x(0),x(1),x(2).toInt))
//将RDD转为DataFrame
//RDD本身是没有toDF方法的,要导入隐式转换(详细参考scala.md)
import spark.implicits._
val personDF=personRDD.toDF()
personDF.printSchema()
personDF.show()
val firstRow=personDF.first() //获取第一行数据
println("firstRow: "+firstRow)
val top2=personDF.head(2) //获取前2位数据
top2.foreach(println)
//获取name字段
personDF.select("name").show()
personDF.select($"name").show()
personDF.select(new Column("name")).show()
personDF.select("name","age").show()
personDF.select($"name",$"age",$"age"+1).show()
//按照age过滤
personDF.filter($"age" >30).show()
val count: Long = personDF.filter($"age" >30).count()
println("count:"+count)
//分组
personDF.groupBy("age").count().show()
personDF.show()
personDF.foreach(row => println(row))
//使用foreach获取每一个row对象中的name字段
personDF.foreach(row =>println(row.getAs[String]("name")))
personDF.foreach(row =>println(row.get(1)))
personDF.foreach(row =>println(row.getString(1)))
personDF.foreach(row =>println(row.getAs[String](1)))
//todo:----------------- DSL风格语法--------------------end
//todo:----------------- SQL风格语法-----------------start
personDF.createTempView("person")
//使用SparkSession调用sql方法统计查询
spark.sql("select * from person").show
spark.sql("select name from person").show
spark.sql("select name,age from person").show
spark.sql("select * from person where age >30").show
spark.sql("select count(*) from person where age >30").show
spark.sql("select age,count(*) from person group by age").show
spark.sql("select age,count(*) as count from person group by age").show
spark.sql("select * from person order by age desc").show
//todo:----------------- SQL风格语法----------------------end
//关闭sparkSession对象
spark.stop()
}
}
方法2:通过StructType动态指定Schema
该方法的应用场景:在开发代码之前,无法确定需要的DataFrame对应的schema元信息,需要在开发代码的过程中动态指定。
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SparkSession}
object StructTypeDemo {
def main(args: Array[String]): Unit = {
val spark=SparkSession.builder().appName("Demo").master("local[2]").getOrCreate()
val sc=spark.sparkContext
sc.setLogLevel("warn")
val data:RDD[Array[String]]=sc.textFile("F:\\test\\person.txt").map(x=>x.split(" "))
//使用Row包装一行数据,Row可以封装任意类型任意数目的数据
val rowRDD:RDD[Row]=data.map(x=>Row(x(0),x(1),x(2).toInt))
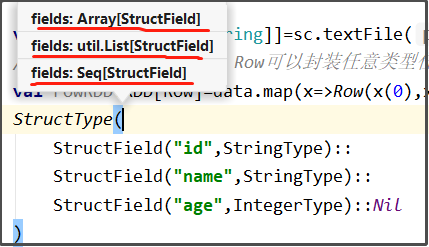
val schema=StructType(
StructField("id",StringType)::
StructField("name",StringType)::
StructField("age",IntegerType)::Nil
)
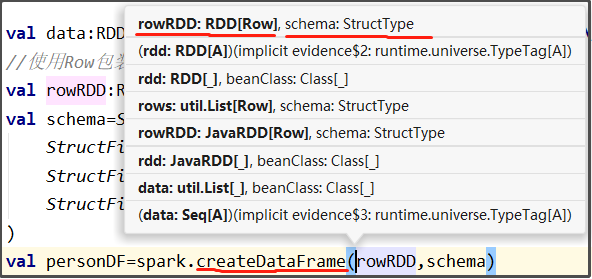
val personDF=spark.createDataFrame(rowRDD,schema)
personDF.printSchema()
personDF.show()
personDF.createTempView("user")
spark.sql("select * from user").show()
spark.stop()
}
}
说明:
- 因为后面要使用spark.createDataFrame(rowRDD:RDD[Row],schema:StructType)来创建DataFrame,所以要想创建RDD[Row]和StructType类型的变量
-
Row类有伴生对象object Row,伴生对象里有apply方法,该apply方法的参数是Any*,所以创建Row对象时不需要new,参数也可以多种类型和多个,Row(x(0),x(1),x(2).toInt)
-
StructType的参数类型是:
-
StructField是一个样例类,源代码大致如下:
case class StructField(
name: String, //名称
dataType: DataType, //数据类型
nullable: Boolean = true, //表示是否允许该值为空
metadata: Metadata = Metadata.empty) {...}
