spark(20)DataFrame概述、常用操作、优缺点、读取文件构建DataFrame
DataFrame概述
spark core--->操控RDD
spark sql--->操控DataFrame
DataFrame发展
DataFrame前身是schemaRDD,这个schemaRDD是直接继承自RDD,它是RDD的一个实现类
在spark1.3.0之后把schemaRDD改名为DataFrame,它不再继承自RDD,而是自己实现RDD上的一些功能
也可以把dataFrame转换成一个rdd,调用rdd方法即可转换成功,例如 val rdd1=dataFrame.rdd
DataFrame是什么
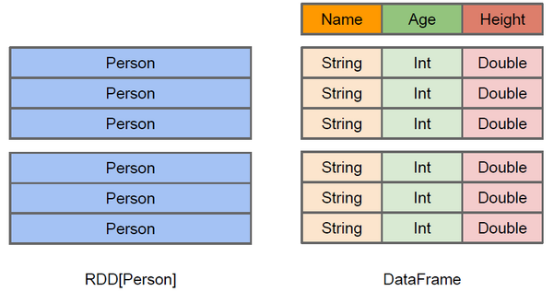
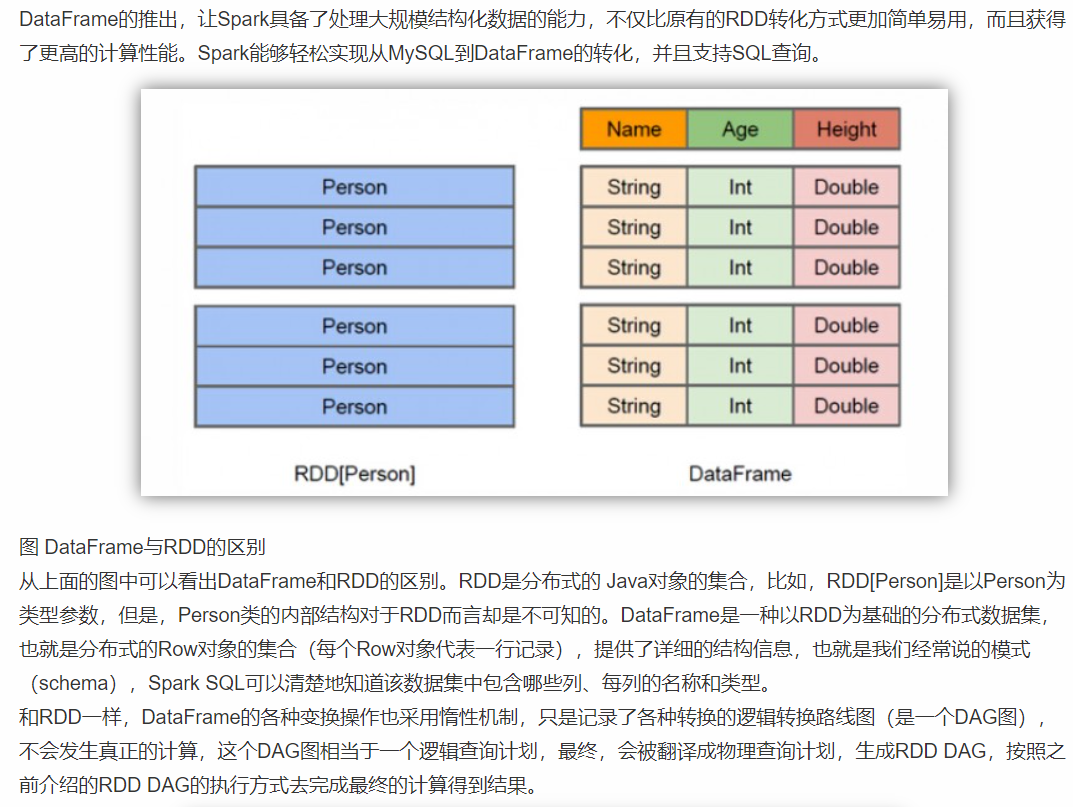
在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库的二维表格
DataFrame带有Schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型,但底层做了更多的优化
DataFrame可以从很多数据源构建,比如:已经存在的RDD、结构化文件、外部数据库、Hive表。
RDD可以把它内部元素看成是一个java对象
DataFrame可以把内部元素看成是一个Row对象,它表示一行一行的数据,每一行是固定的数据类型
可以把DataFrame这样去理解----->RDD+schema元信息, dataFrame相比于rdd来说,多了对数据的描述信息(schema元信息)
DataFrame和RDD的优缺点
RDD优点
1、编译时类型安全,开发会进行类型检查,在编译的时候及时发现错误
2、具有面向对象编程的风格
RDD缺点
1、构建大量的java对象占用了大量heap堆空间,导致频繁的垃圾回收GC。 :RDD[Java对象]
由于数据集RDD它的数据量比较大,后期都需要存储在heap堆中,这里有heap堆中的内存空间有限,出现频繁的垃圾回收(GC),程序在进行垃圾回收的过程中,所有的任务都是暂停。影响程序执行的效率
2、数据的序列化和反序列性能开销很大
在分布式程序中,对象(对象的内容和结构)是先进行序列化,发送到其他服务器,进行大量的网络传输,然后接受到这些序列化的数据之后,再进行反序列化来恢复该对象
DataFrame优点
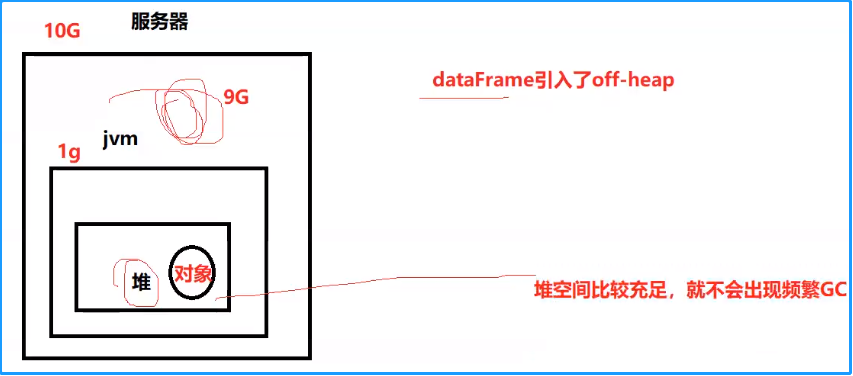
DataFrame引入了schema元信息和off-heap(堆外)
1、DataFrame引入off-heap,大量的对象构建直接使用操作系统层面上的内存,不再使用heap堆中的内存,这样一来heap堆中的内存空间就比较充足,不会导致频繁GC,程序的运行效率比较高,它是解决了RDD构建大量的java对象占用了大量heap堆空间,导致频繁的GC这个缺点。
2、DataFrame引入了schema元信息---就是数据结构的描述信息,后期spark程序中的大量对象在进行网络传输的时候,只需要把数据的内容本身进行序列化就可以,数据结构信息可以省略掉。这样一来数据网络传输的数据量是有所减少,数据的序列化和反序列性能开销就不是很大了。它是解决了RDD数据的序列化和反序列性能开销很大这个缺点
DataFrame缺点
DataFrame引入了schema元信息和off-heap(堆外)它是分别解决了RDD的缺点,同时它也丢失了RDD的优点
1、编译时类型不安全
- 编译时不会进行类型的检查,这里也就意味着前期是无法在编译的时候发现错误,只有在运行的时候才会发现
2、不再具有面向对象编程的风格
读取文件构建DataFrame
Spark context与Spark session的关系
在spark2.0之前,要操控rdd就要构建spark context对象,要使用sparksql就要构建sqlcontext对象,要使用hive表就要构建hivecontext对象。
在spark2.0之后,人们觉得这样太麻烦,就出现了spark session,spark session封装了上面的3个对象。
那么,spark2.0之后,就可通过spark session来构建spark context、sql context...
scala> sc
res0: org.apache.spark.SparkContext = org.apache.spark.SparkContext@5fdb7394
scala> spark
res1: org.apache.spark.sql.SparkSession = org.apache.spark.sql.SparkSession@52285a5f
scala> spark. //下面是spark封装的东西
baseRelationToDataFrame close createDataFrame emptyDataFrame experimental listenerManager range readStream sharedState sql stop table udf catalog conf createDataset emptyDataset implicits newSession read sessionState sparkContext sqlContext streams time version
scala> spark.sparkContext
res2: org.apache.spark.SparkContext = org.apache.spark.SparkContext@5fdb7394
scala> spark.sparkContext.parallelize(List(1,2,3)) //使用spark封装的sparkContext
res3: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24
读取文本文件创建DataFrame
创建文本文件:
vi /tmp/person.txt
1 zhangsan 20
2 lisi 32
3 laowang 46
hdfs dfs -put /tmp/person.txt /
第一种方式,从结果可以看到DataFrame默认使用一个string类型的value列
scala> val personDF=spark.read.text("/person.txt")
personDF: org.apache.spark.sql.DataFrame = [value: string]
//打印schema信息
scala> personDF.printSchema
root
|-- value: string (nullable = true)
//展示数据
scala> personDF.show
+-------------+
| value|
+-------------+
|1 zhangsan 20|
| 2 lisi 32|
| 3 laowang 46|
+-------------+
第二种方式
//加载数据
val rdd1=sc.textFile("/person.txt").map(x=>x.split(" "))
//定义一个样例类
case class Person(id:String,name:String,age:Int)
//把rdd与样例类进行关联
val personRDD=rdd1.map(x=>Person(x(0),x(1),x(2).toInt))
//把rdd转换成DataFrame
val personDF=personRDD.toDF
//打印schema信息
personDF.printSchema
//展示数据
personDF.show
读取json文件创建DataFrame
hdfs dfs -put /kkb/install/spark/examples/src/main/resources/people.json /
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}
scala> val peopleDF=spark.read.json("/people.json")
peopleDF: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
scala> peopleDF.printSchema
root
|-- age: long (nullable = true)
|-- name: string (nullable = true)
scala> peopleDF.show
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
读取parquet文件创建DataFrame
hdfs dfs -put /kkb/install/spark/examples/src/main/resources/users.parquet /
scala> val parquetDF=spark.read.parquet("/users.parquet")
parquetDF: org.apache.spark.sql.DataFrame = [name: string, favorite_color: string ... 1 more field]
scala> parquetDF.printSchema
root
|-- name: string (nullable = true)
|-- favorite_color: string (nullable = true)
|-- favorite_numbers: array (nullable = true) //数组类型
| |-- element: integer (containsNull = true) //数组元素的类型
scala> parquetDF.show
+------+--------------+----------------+
| name|favorite_color|favorite_numbers|
+------+--------------+----------------+
|Alyssa| null| [3, 9, 15, 20]|
| Ben| red| []|
+------+--------------+----------------+
DataFrame常用操作
DSL风格语法
就是sparksql中的DataFrame自身提供了一套自己的Api,可以去使用这套api来做相应的处理。
创建DataFrame
scala> val rdd1=sc.textFile("/person.txt").map(x=>x.split(" "))
rdd1: org.apache.spark.rdd.RDD[Array[String]] = MapPartitionsRDD[20] at map at <console>:24 //每一行切分而成的多个元素被封装成一个Array,作为RDD的类型
scala> case class Person(id:String,name:String,age:Int)
defined class Person //创建一个样例类
scala> val PersonRDD=rdd1.map(x=>Person(x(0),x(1),x(2).toInt))
PersonRDD: org.apache.spark.rdd.RDD[Person] = MapPartitionsRDD[21] at map at <console>:27 //将rdd1的每一个Array类型转为一个Person对象
scala> val PersonDF=PersonRDD.toDF //将RDD转为DataFrame
PersonDF: org.apache.spark.sql.DataFrame = [id: string, name: string ... 1 more field]
scala> PersonDF.printSchema
root
|-- id: string (nullable = true)
|-- name: string (nullable = true)
|-- age: integer (nullable = false)
scala> PersonDF.show
+---+--------+---+
| id| name|age|
+---+--------+---+
| 1|zhangsan| 20|
| 2| lisi| 32|
| 3| laowang| 46|
+---+--------+---+
DataFrame.select()操作,select操作返回的还是一个DataFrame类型
scala> PersonDF.select("name")
res12: org.apache.spark.sql.DataFrame = [name: string]
scala> PersonDF.select("name").show
+--------+
| name|
+--------+
|zhangsan|
| lisi|
| laowang|
+--------+
scala> PersonDF.select($"name").show
+--------+
| name|
+--------+
|zhangsan|
| lisi|
| laowang|
+--------+
scala> PersonDF.select(col("name")).show
+--------+
| name|
+--------+
|zhangsan|
| lisi|
| laowang|
+--------+
scala> PersonDF.select("name","age").show
+--------+---+
| name|age|
+--------+---+
|zhangsan| 20|
| lisi| 32|
| laowang| 46|
+--------+---+
scala> PersonDF.select($"name",$"age",$"age"+1).show //age+1
+--------+---+---------+
| name|age|(age + 1)|
+--------+---+---------+
|zhangsan| 20| 21|
| lisi| 32| 33|
| laowang| 46| 47|
+--------+---+---------+
DataFrame.filter()操作:
scala> PersonDF.filter($"age">30).show
+---+-------+---+
| id| name|age|
+---+-------+---+
| 2| lisi| 32|
| 3|laowang| 46|
+---+-------+---+
SQL风格语法(推荐)
可以把DataFrame注册成一张表,然后通过sparkSession.sql(sql语句)操作
//DataFrame注册成表
personDF.createTempView("Person")
//使用SparkSession调用sql方法统计查询
scala> spark.sql("select * from Person").show
+---+--------+---+
| id| name|age|
+---+--------+---+
| 1|zhangsan| 20|
| 2| lisi| 32|
| 3| laowang| 46|
+---+--------+---+
spark.sql("select name from person").show
spark.sql("select name,age from person").show
spark.sql("select * from person where age >30").show
spark.sql("select count(*) from person where age >30").show
spark.sql("select age,count(*) from person group by age").show
spark.sql("select age,count(*) as count from person group by age").show
spark.sql("select * from person order by age desc").show

