spark(15) RDD的依赖关系、lineage血统
RDD的依赖关系
依赖类型
RDD根据依赖关系,可以分为父RDD和子RDD,父RDD就是被子RDD依赖的RDD。
而父RDD与子RDD的依赖关系,可以分为两种类型:
- 窄依赖(narrow dependency)
- 宽依赖(wide dependency)
窄依赖
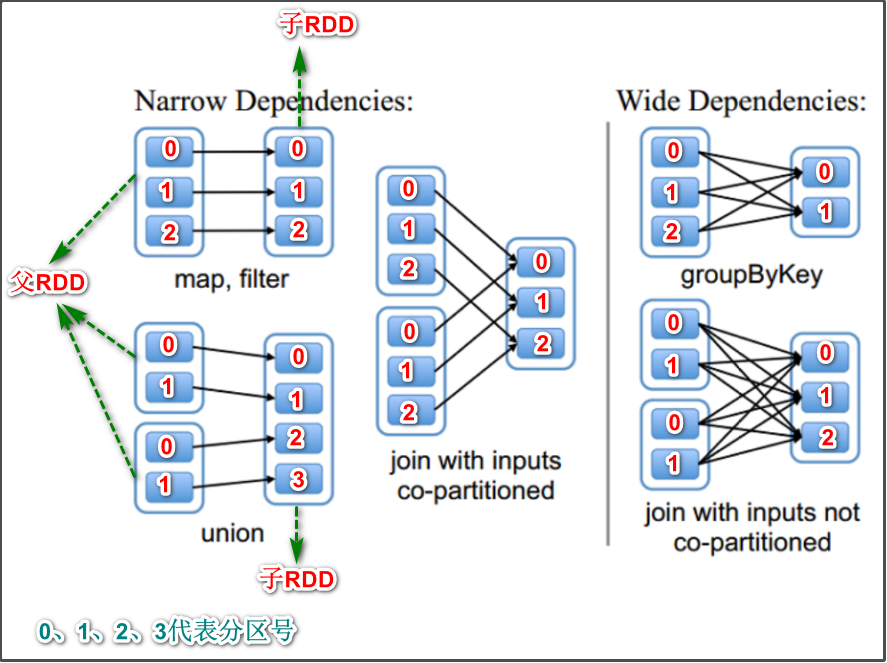
窄依赖:指的是每一个父RDD的Partition最多被子RDD的一个Partition使用,可比喻为独生子女。
map/flatMap/filter/union等算子操作都是窄依赖,所有的窄依赖不会产生shuffle
宽依赖
宽依赖:指的是多个子RDD的Partition会依赖同一个父RDD的Partition,可比喻为超生。
reduceByKey/sortByKey/groupBy/groupByKey/join等算子操作都是宽依赖,所有的宽依赖会产生shuffle
示意图
补充说明
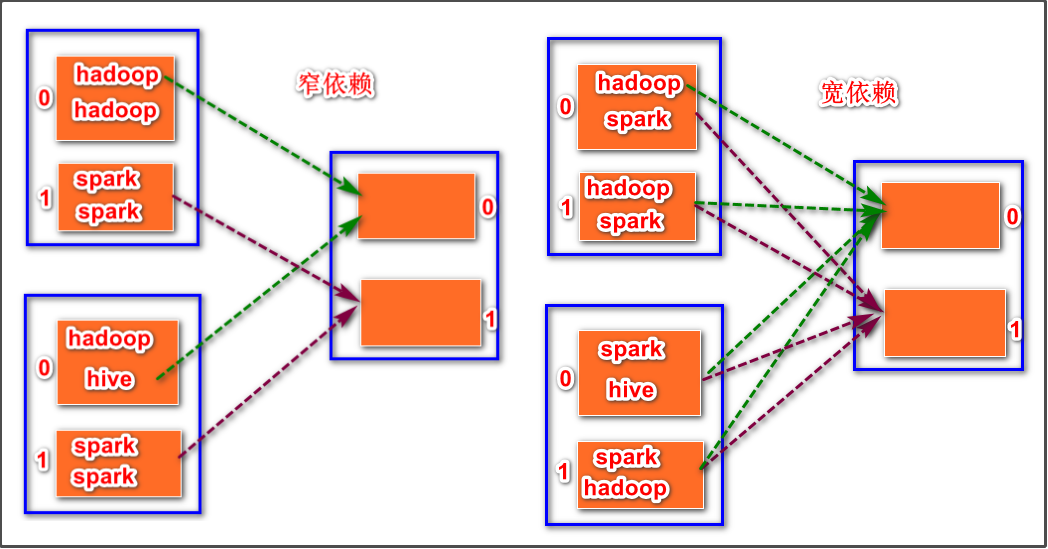
由上图可知,join分为宽依赖和窄依赖,如果RDD有相同的partitioner(本质是看分区函数或者分区逻辑是否相同),那么将不会引起shuffle,这种join是窄依赖,反之就是宽依赖。详情看下图:
lineage(血统)理解即可
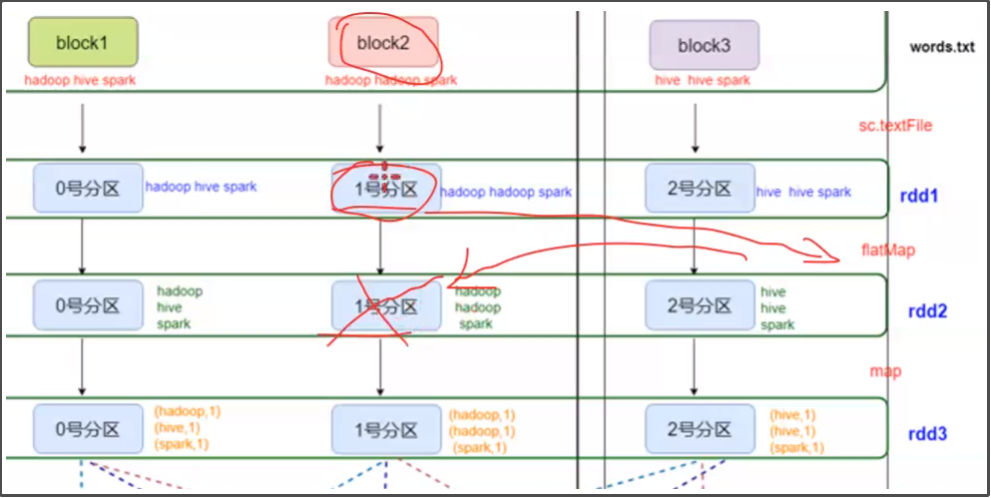
RDD只支持粗粒度转换:即只记录单个块上执行的单个操作。
那么,就需要创建RDD的一系列Lineage(即血统)记录下来,以便恢复丢失的分区。
RDD的Lineage会记录RDD的元数据信息和转换行为,lineage保存了RDD的依赖关系,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
比如,下图中的rdd2的1号分区的数据丢失了,那么就可以根据血统lineage保存的RDD的依赖关系和转换行为等,将rdd1中的数据进行flatMap操作恢复丢失的数据。