spark(12)spark任务中资源参数剖析
spark任务中资源参数剖析
通过开发工具开发好spark程序后达成jar包最后提交到集群中运行
提交任务脚本如下
spark-submit \
--master spark://node01:7077,node02:7077 \
--class com.kaikeba.WordCountOnSpark \
--executor-memory 1g \
--total-executor-cores 4 \
original-spark_class03-1.0-SNAPSHOT.jar \
/words.txt /out
--executor-memory
- 表示每一个executor进程需要的内存大小,它决定了后期操作数据的速度
比如说一个rdd的数据量大小为5g,这里给定的executor-memory为2g, 在这种情况下,内存是存储不下,它会把一部分数据保存在内存中,还有一部分数据保存在磁盘,后续需要用到该rdd的结果数据,可以从内存和磁盘中获取得到,这里就涉及到一定的磁盘io操作。
,这里给定的executor-memory为10g,这里数据就可以完全在内存中存储下,后续需要用到该rdd的数据,就可以直接从内存中获取,这样一来,避免了大量的磁盘io操作。性能得到提升。
在实际的工作,这里 --executor-memory 需要设置的大一点。
比如说10G/20G/30G等
--total-executor-cores
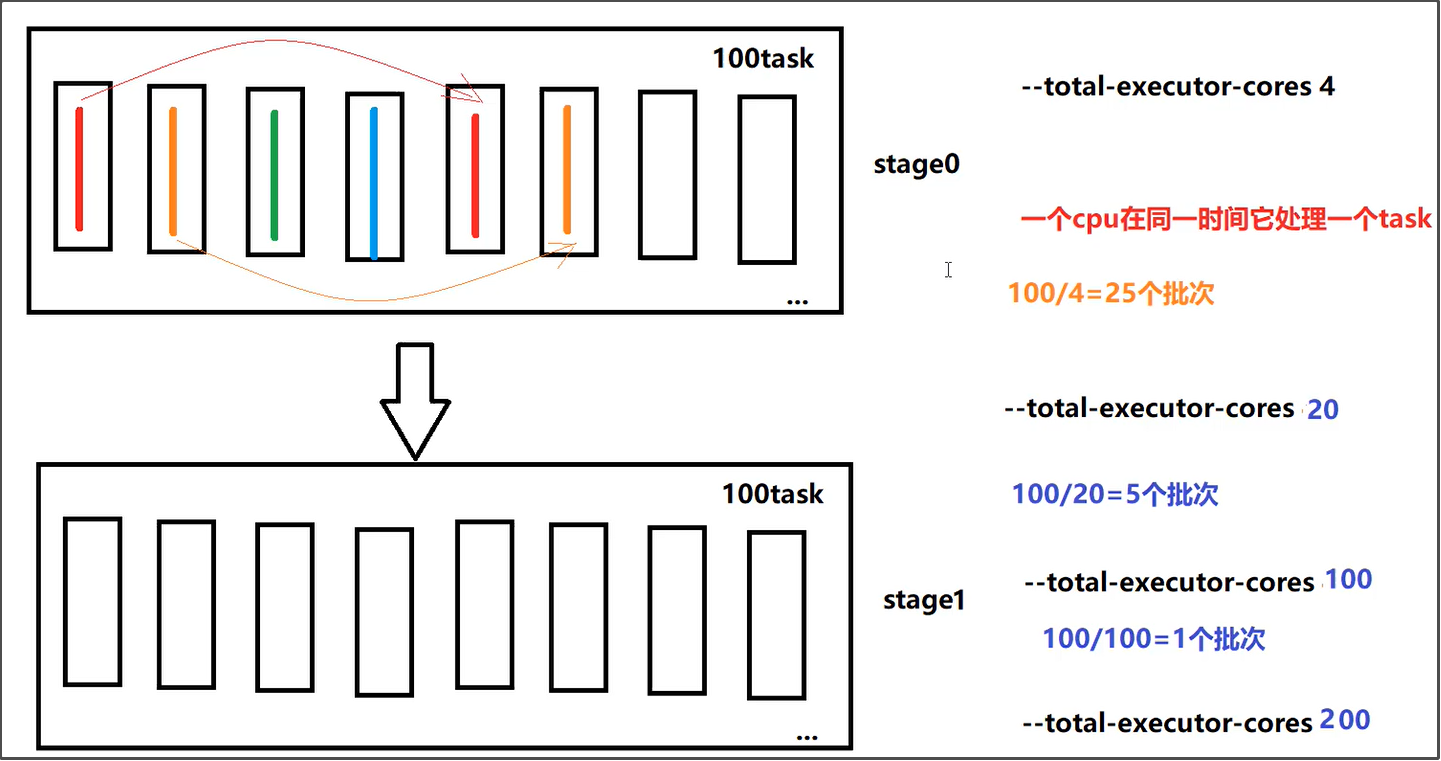
--total-executor-cores表示任务运行需要总的cpu核数,它决定了任务并行运行的粒度
比如说要处理100个task,注意一个cpu在同一时间只能处理一个task线程。
-
如果给定的总的cpu核数是5个,这里就需要100/5=20个批次才可以把这100个task运行完成,如果平均每个task运行1分钟,这里最后一共运行20分钟。
-
如果给定的总的cpu核数是20个,这里就需要100/20=5个批次才可以把这100个task运行完成,如果平均每个task运行1分钟,这里最后一共运行5分钟。
-
如果如果给定的总的cpu核数是100个,这里就需要100/100=1个批次才可以把这100个task运行完成,如果平均每个task运行1分钟,这里最后一共运行1分钟。
在实际的生产环境中,--total-executor-cores 这个参数一般也会设置的大一点,比如说 30个/50个/100个
总结
后期对于spark程序的优化,可以从这2个参数入手,无论你把哪一个参数调大,对程序运行的效率来说都会达到一定程度的提升,加大计算资源它是最直接、最有效果的优化手段。
在计算资源有限的情况下,可以考虑其他方面,比如说代码层面,JVM层面等
