spark(10)spark on yarn
spark on yarn
spark程序可以提交到yarn中去运行,此时spark任务所需要的计算资源由yarn中的老大ResourceManager去分配
官网资料地址: http://spark.apache.org/docs/2.3.3/running-on-yarn.html
环境准备
- 安装hadoop集群
- 安装spark环境
注意:
这里不需要安装spark集群,只需要解压spark安装包到任意一台服务器,然后修改文件spark-env.sh:
#指定java的环境变量
export JAVA_HOME=/kkb/install/jdk1.8.0_141
#指定hadoop的配置文件目录
export HADOOP_CONF_DIR=/kkb/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop
因为我们之前安装过了spark集群,包含了spark环境,所以我们不需要做任何操作
sparkOnYarn模式
按照Spark应用程序中的driver分布方式不同,Spark on YARN有两种模式:
- yarn-client模式
- yarn-cluster`模式
yarn-cluster模式
提交spark的测试程序到yarn运行:
spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 1g \
--executor-memory 1g \
--executor-cores 1 \
/kkb/install/spark/examples/jars/spark-examples_2.11-2.3.3.jar \
10
#特别注意
--master 的值是yarn
--deploy-mode 的值是cluster,表示使用cluster模式运行
如果运行出现错误,可能是虚拟内存不足,可以添加参数
vim yarn-site.xml
<!--容器是否会执行物理内存限制,默认为True-->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--容器是否会执行虚拟内存限制,默认为True-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
说明:
1、使用cluster集群模式时,如果在运行中途,在运行窗口界面按ctrl+c是终止不了spark程序的运行的,虽然窗口不再有打印输出,但是程序还是在运行着的。如下:

2、ctrl+c停止打印输出后,我们去查看http://node01:8088/cluster的信息,发现该任务执行成功了:
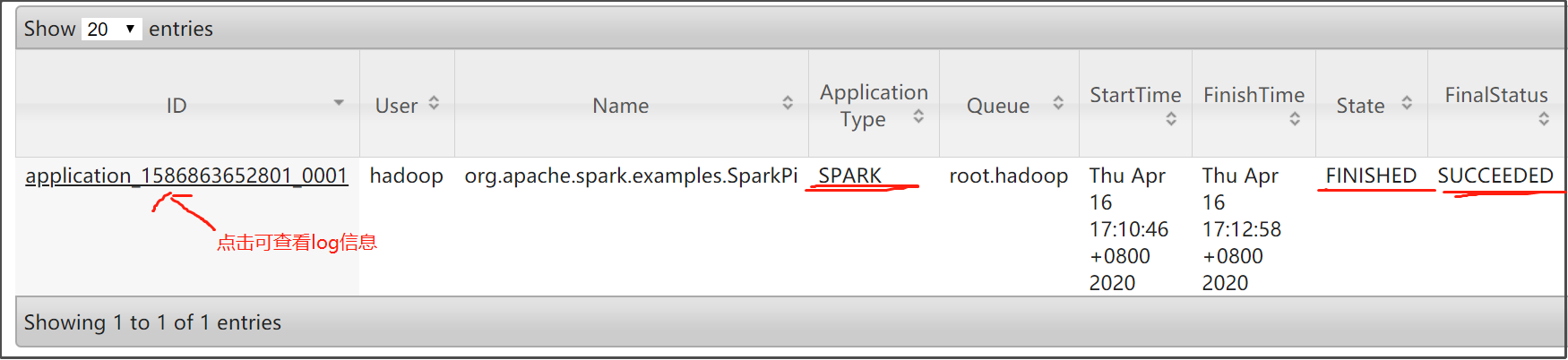
3、点击该Application的ID,查看log,可看到运行结果:
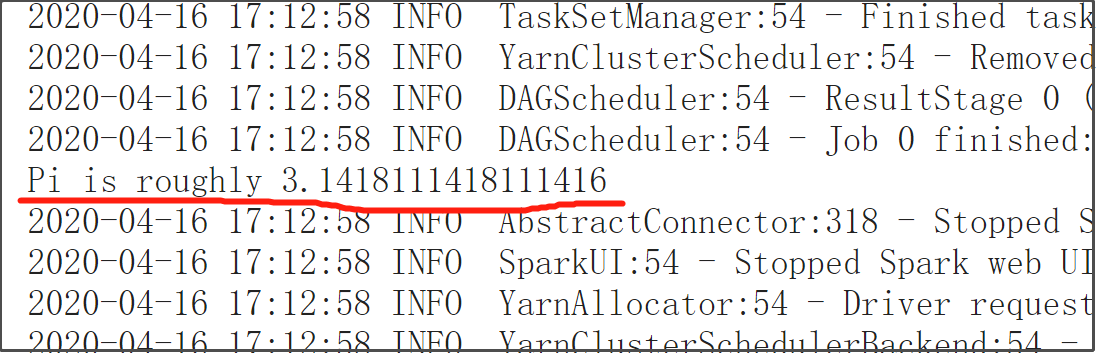
4、即使不使用ctrl+c中断打印信息的输出,程序在运行完成后(state:Finished代表运行完成),在Linux的运行输出窗口依然是看不到Pi的结果输出的。这跟cluster模式运行有关。
yarn-client模式
提交spark的测试程序到yarn运行:
spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
--driver-memory 1g \
--executor-memory 1g \
--executor-cores 1 \
/kkb/install/spark/examples/jars/spark-examples_2.11-2.3.3.jar \
10
说明:
- 在client模式下,如果ctrl+c中断了输出,等同于停止了程序的运行。
- 在client模式下,可以在Linux的运行输出窗口看到Pi结果的输出
client模式和yarn模式的原理
首先来回顾以下MapReduce程序运行在yarn的大致流程:
- 客户端与ResourceManager进行通信,申请Application
- 客户端提交jar包到hdfs
- RM向集群的某个NodeManager申请开启ApplicationMaster,该NM就启动一个Container,在该Container里面启动ApplicationMaster
- ApplicationMaster向RM申请在某些NodeManager启动容器,给task运行,然后NM就会启动一些Container给task运行
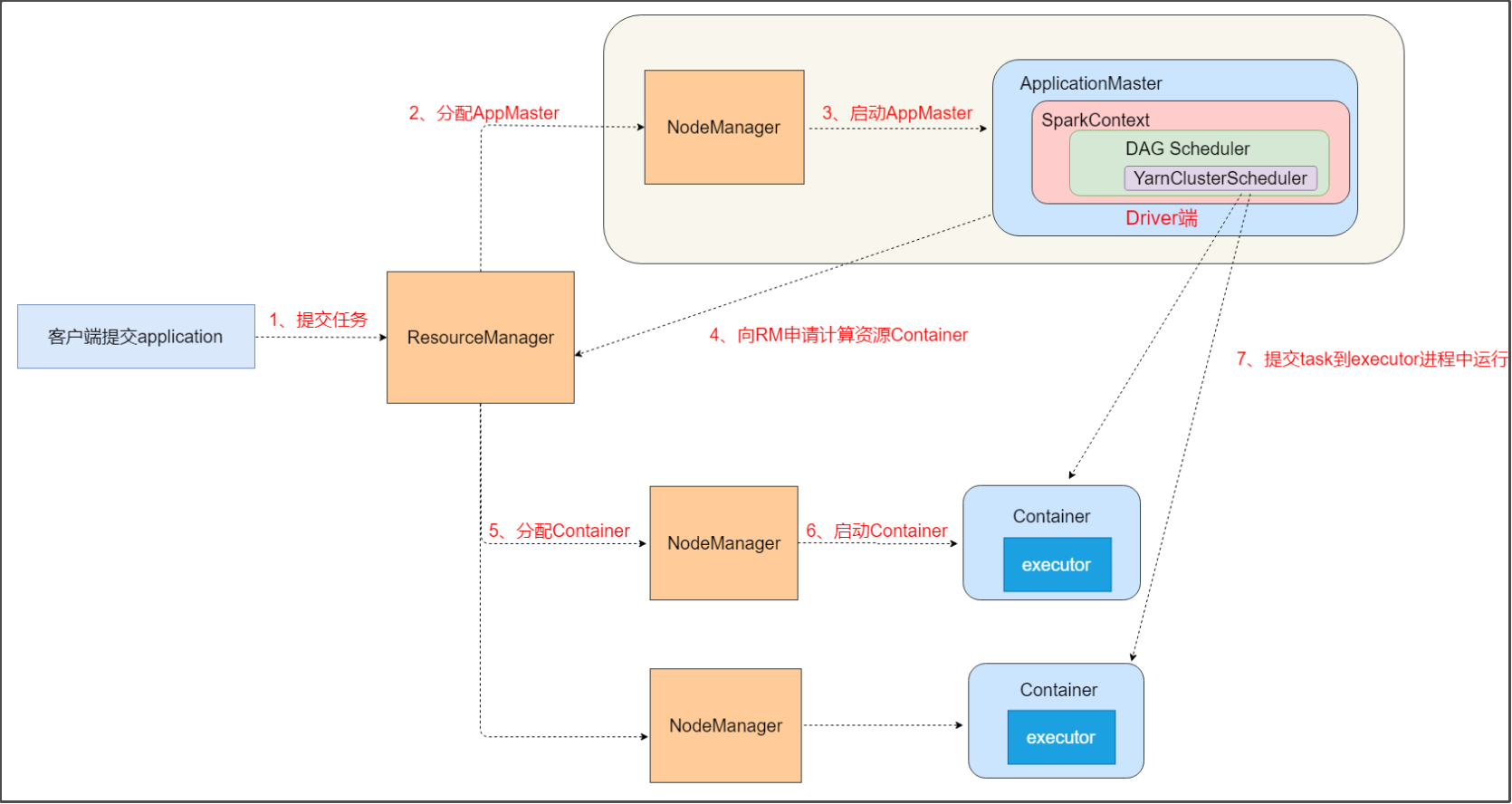
yarn-cluster模式原理:
结合yanr的工作机制,yarn-cluter模式执行spark程序的大致流程如下:
- 客户端提交Application到RM
- RM找到某个节点上NodeManager,申请Container来启动一个ApplicationMaster。
- ApplicationMaster启动后,会在内部构建一个spark context对象。SparkContext的底层调度器由taskScheduler变成了YarnClusterScheduler。
- 在之前了解到,SparkContext对象是在Driver端的,因此,Driver端也是在该ApplicationMaster进程内部的。ApplicationMaster跟driver端捆绑在一起了,ApplicationMaster在哪里,driver端就在哪里。
- 构建好SparkContext对象后,ApplicationMaster会向RM申请计算资源Container。
- 然后在某些NodeManager节点上就会启动Container,在Container上启动executor
- 最后,YarnClusterScheduler就会提交task到executor上运行
了解yarn-cluster模式的机制后,就可以理解:为什么ctrl+c终止客户端终端停止不了spark程序的运行了。
这是因为Driver端跟客户端不在同一个节点,比如客户端在node01,而nodemanager和dirver都在node02。
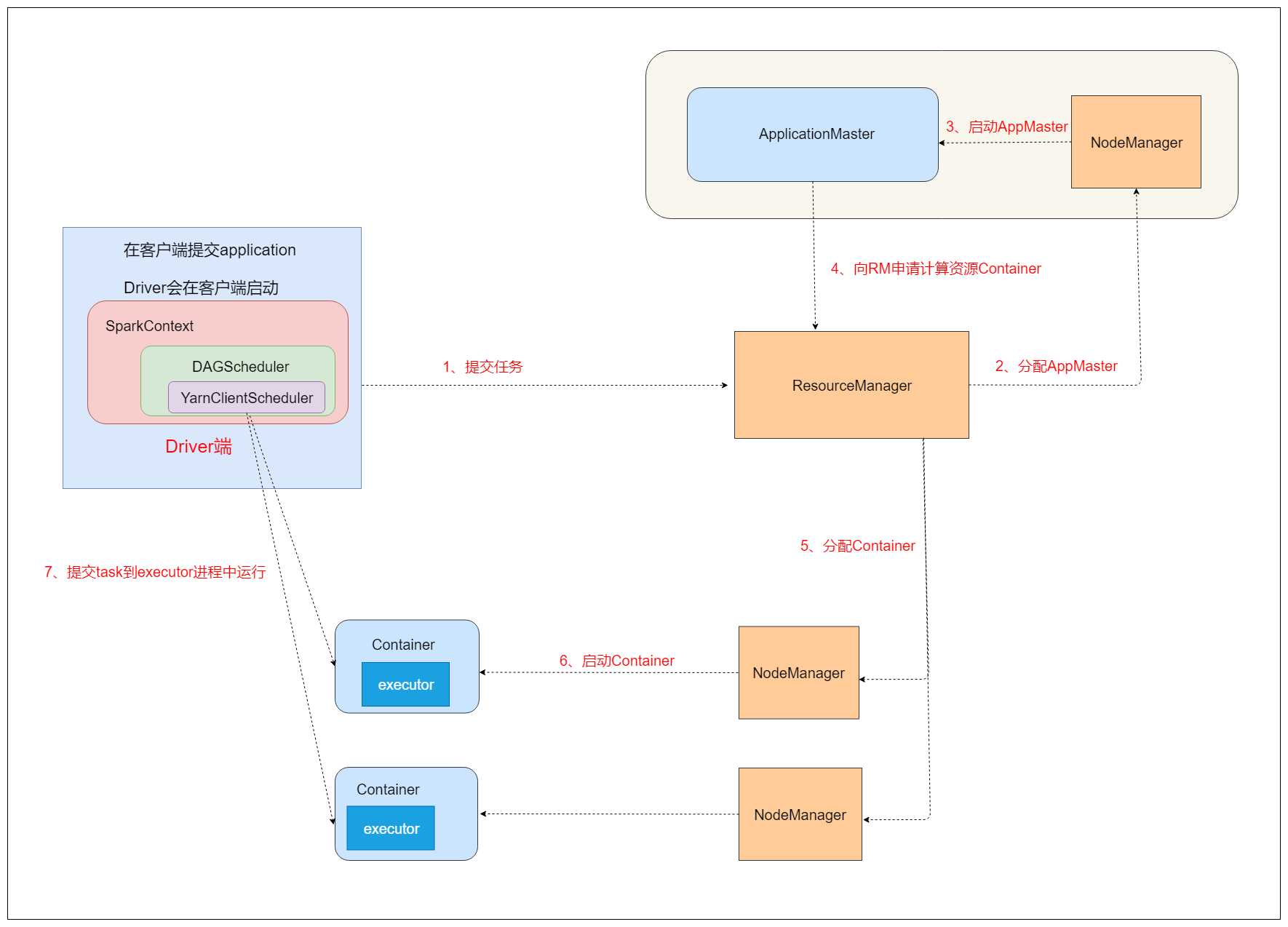
yarn-client模式原理:
client模式与cluster模式的流程很相似,只不过是Driver端的位置发生了变化,Driver端跟客户端捆绑在了一起,YarnClusterScheduler也变成了YarnClientScheduler。
因此,当使用client模式时,如果我们停掉了客户端终端,就相当于停掉了Driver端,导致程序运行失败。这也是我们输出日志显示不停地尝试连接Driver端的原因。
client模式和yarn模式的区别
yarn-cluster模式
- spark程序的Driver程序在YARN中运行,运行结果不能在客户端显示,并且客户端可以在启动应用程序后消失应用的。
- 最好运行那些将结果最终保存在外部存储介质(如HDFS、Redis、Mysql),客户端的终端显示的仅是作为YARN的job的简单运行状况。
yarn-client模式
- spark程序的Driver运行在Client上,应用程序运行结果会在客户端显示,所有适合运行结果有输出的应用程序(如spark-shell)
总结
- 最大的区别就是Driver端的位置不一样。
- yarn-cluster: Driver端运行在yarn集群中,与ApplicationMaster进程在一起。
- yarn-client: Driver端运行在提交任务的客户端,与ApplicationMaster进程没关系,经常用于进行测试
