spark(7)RDD的算子说明及操作
🌈RDD的算子
算子可以理解成RDD的一些方法。
RDD的算子可以分为2类:
1、transformation(转换)
- 根据已经存在的rdd转换生成一个新的rdd, 它是延迟加载,它不会立即执行
- 例如: map / flatMap / reduceByKey 等
2、action (动作)
- 它会真正触发任务的运行,将rdd的计算的结果数据返回给Driver端,或者是保存结果数据到外部存储介质中
- 例如:collect / saveAsTextFile 等
RDD常见的算子操作说明(重要)
transformation算子
| 转换 | 含义 |
|---|---|
| map(func) | 返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成 |
| filter(func) | 返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成 |
| flatMap(func) | 类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素) |
| mapPartitions(func) | 类似于map,但独立地在RDD的每一个分片上运行,因此在类型为T的RDD上运行时,func的函数类型必须是Iterator[T] => Iterator[U] |
| mapPartitionsWithIndex(func) | 类似于mapPartitions,但func带有一个整数参数表示分片的索引值,因此在类型为T的RDD上运行时,func的函数类型必须是(Int, Interator[T]) => Iterator[U] |
| union(otherDataset) | 对源RDD和参数RDD求并集后返回一个新的RDD |
| intersection(otherDataset) | 对源RDD和参数RDD求交集后返回一个新的RDD |
| distinct([numTasks])) | 对源RDD进行去重后返回一个新的RDD |
| groupByKey([numTasks]) | 在一个(K,V)的RDD上调用,返回一个(K, Iterator[V])的RDD |
| reduceByKey(func, [numTasks]) | 在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,与groupByKey类似,reduce任务的个数可以通过第二个可选的参数来设置 |
| sortByKey([ascending], [numTasks]) | 在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD |
| sortBy(func,[ascending], [numTasks]) | 与sortByKey类似,但是更灵活 |
| join(otherDataset, [numTasks]) | 在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD |
| cogroup(otherDataset, [numTasks]) | 在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable |
| coalesce(numPartitions) | 减少 RDD 的分区数到指定值。 |
| repartition(numPartitions) | 重新给 RDD 分区 |
| repartitionAndSortWithinPartitions(partitioner) | 重新给 RDD 分区,并且每个分区内以记录的 key 排序 |
action算子
| 动作 | 含义 |
|---|---|
| reduce(func) | reduce将RDD中元素前两个传给输入函数,产生一个新的return值,新产生的return值与RDD中下一个元素(第三个元素)组成两个元素,再被传给输入函数,直到最后只有一个值为止。 |
| collect() | 在驱动程序中,以数组的形式返回数据集的所有元素 |
| count() | 返回RDD的元素个数 |
| first() | 返回RDD的第一个元素(类似于take(1)) |
| take(n) | 返回一个由数据集的前n个元素组成的数组 |
| takeOrdered(n, [ordering]) | 返回自然顺序或者自定义顺序的前 n 个元素 |
| saveAsTextFile(path) | 将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本 |
| saveAsSequenceFile(path) | 将数据集中的元素以Hadoop sequencefile的格式保存到指定的目录下,可以使HDFS或者其他Hadoop支持的文件系统。 |
| saveAsObjectFile(path) | 将数据集的元素,以 Java 序列化的方式保存到指定的目录下 |
| countByKey() | 针对(K,V)类型的RDD,返回一个(K,Int)的map,表示每一个key对应的元素个数。 |
| foreach(func) | 在数据集的每一个元素上,运行函数func |
| foreachPartition(func) | 在数据集的每一个分区上,运行函数func |
map与mapPartitions的区别(面试题)
- map含义:返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成
- mapPartitions含义:类似于map,但独立地在RDD的每一个分片上运行,因此在类型为T的RDD上运行时,func的函数类型必须是Iterator[T] => Iterator[U]
- map是对rdd中的每一个元素进行操作,mapPartitions是对rdd中的每一个分区/task的迭代器进行操作
- 两者最终实现的效果都是一样的,但是实现的过程不一样。
MapPartitions的优点:
如果是普通的map,比如一个partition中有1万条数据,那么你的function要执行和计算1万次。
使用MapPartitions操作之后,一个task仅仅会执行一次function,function一次接收所有的partition数据。只要执行一次就可以了,性能比较高。
如果在map过程中需要频繁创建额外的对象(例如将rdd中的数据通过jdbc写入数据库,map需要为每个元素创建一个链接而mapPartition为每个partition创建一个链接),则mapPartitions效率比map高的多。
SparkSql或DataFrame默认会对程序进行mapPartition的优化。
MapPartitions的缺点:
如果是普通的map操作,一次function的执行就处理一条数据;那么如果内存不够用的情况下, 比如处理了1千条数据了,那么这个时候内存不够了,那么就可以将已经处理完的1千条数据从内存里面垃圾回收掉,或者用其他方法,腾出空间来吧。
所以说普通的map操作通常不会导致内存的OOM(Out Of Memory)异常。
但是MapPartitions操作,对于大量数据来说,比如甚至一个partition,100万数据,一次传入一个function以后,那么可能一下子内存不够,但是又没有办法去腾出内存空间来,可能就OOM,内存溢出。
foreach与foreachPartition的区别(面试题)
与map VS mapPartitions类似
面试题1

RDD常用的算子操作演示
为了方便前期的测试和学习,可以使用spark-shell进行演示
spark-shell --master local[2]
1 map
scala> val rdd1=sc.parallelize(List(1,2,3,4,5,6,7,8))
scala> val rdd2=rdd1.map(x=>x*10)
scala> rdd2.collect
res4: Array[Int] = Array(10, 20, 30, 40, 50, 60, 70, 80)
2 filter
val rdd1 = sc.parallelize(List(5, 6, 4, 7, 3, 8, 2, 9, 1, 10))
//把rdd1中大于5的元素进行过滤
rdd1.filter(x => x >5).collect
3 flatMap
val rdd1 = sc.parallelize(Array( "a b c", "d e f", "h i j"))
//获取rdd1中元素的每一个字母
rdd1.flatMap(_.split(" ")).collect
4 intersection、union
val rdd1 = sc.parallelize(List(5, 6, 4, 3))
val rdd2 = sc.parallelize(List(1, 2, 3, 4))
//求交集
scala> rdd1.intersection(rdd2).collect
res7: Array[Int] = Array(4, 3)
//求并集
scala> val rdd5=rdd1.union(rdd2)
scala> rdd5.collect
res6: Array[Int] = Array(5, 6, 4, 3, 1, 2, 3, 4)
5 distinct
val rdd1 = sc.parallelize(List(1,1,2,3,3,4,5,6,7))
//去重
rdd1.distinct
6 join、groupByKey
val rdd1 = sc.parallelize(List(("tom", 1), ("jerry", 3), ("kitty", 2)))
val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 1), ("shuke", 2)))
//求join
val rdd3 = rdd1.join(rdd2)
rdd3.collect
res8: Array[(String, (Int, Int))] = Array((tom,(1,1)), (jerry,(3,2)))
//求并集
val rdd4 = rdd1 union rdd2
rdd4.groupByKey.collect
res11: Array[(String, Iterable[Int])] = Array((tom,CompactBuffer(1, 1)), (jerry,CompactBuffer(3, 2)), (shuke,CompactBuffer(2)), (kitty,CompactBuffer(2)))
7 cogroup
val rdd1 = sc.parallelize(List(("tom", 1), ("tom", 2), ("jerry", 3), ("kitty", 2)))
val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 1), ("jim", 2)))
//分组
val rdd3 = rdd1.cogroup(rdd2)
rdd3.collect
res12: Array[(String, (Iterable[Int], Iterable[Int]))] = Array((jim,(CompactBuffer(),CompactBuffer(2))), (tom,(CompactBuffer(1, 2),CompactBuffer(1))), (jerry,(CompactBuffer(3),CompactBuffer(2))), (kitty,(CompactBuffer(2),CompactBuffer())))
8 reduce
示例1:
val rdd1 = sc.parallelize(List(1, 2, 3, 4, 5))
//reduce聚合
val rdd2 = rdd1.reduce(_ + _)
示例2:
val rdd3 = sc.parallelize(List("1","2","3","4","5"))
scala> rdd3.reduce(_+_)
res18: String = 12345
scala> rdd3.reduce(_+_)
res21: String = 34512 //从12345变成了34512
从上面示例2的代码块可知,同样的操作,出现了不同的结果。
这是因为元素在不同的分区中,每一个分区都是一个独立的task线程去运行(多个分区并行运算)。这些task运行有先后关系。
查看元素的分区情况:
scala> rdd3.partitions
res19: Array[org.apache.spark.Partition] = Array(org.apache.spark.rdd.ParallelCollectionPartition@c55, org.apache.spark.rdd.ParallelCollectionPartition@c56)
scala> rdd3.partitions.length
res20: Int = 2
9 reduceByKey、sortByKey
val rdd1 = sc.parallelize(List(("tom", 1), ("jerry", 3), ("kitty", 2), ("shuke", 1)))
val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 3), ("shuke", 2), ("kitty", 5)))
val rdd3 = rdd1.union(rdd2)
//按key进行聚合
val rdd4 = rdd3.reduceByKey(_ + _)
rdd4.collect
//按value的降序排序
val rdd5 = rdd4.map(t => (t._2, t._1)).sortByKey(false).map(t => (t._2, t._1))
rdd5.collect
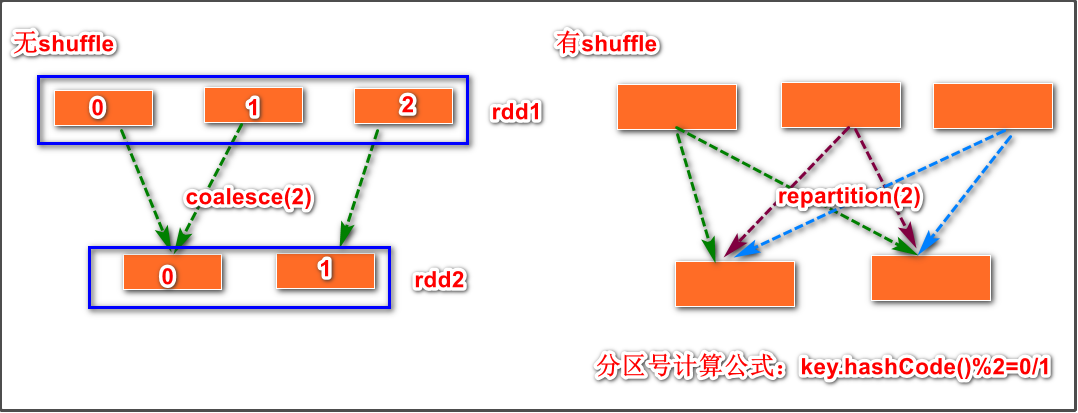
10 repartition、coalesce
两者使用区别
coalesce功能:改变分区数量,只能减少,不能增加
repartition功能:改变分区数量,减少增加都可以
coalesce示例:
scala> val rdd1=sc.parallelize(List(1,2,3,4,5,6,7,8),3)
scala> rdd1.partitions.length
res4: Int = 3
//=============利用coalesce减少分区数量,成功=============================
scala> val rdd2=rdd1.coalesce(2)
rdd2: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[1] at coalesce at <console>:25
scala> rdd2.partitions.length
res5: Int = 2
scala> rdd1.partitions.length
res6: Int = 3
//=============利用coalesce增加分区数量,失败=============================
scala> val rdd3=rdd1.coalesce(5)
rdd3: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[2] at coalesce at <console>:25
scala> rdd3.partitions.length
res7: Int = 3
scala> rdd1.partitions.length
res8: Int = 3
//=============利用repatriation增加分区数量,成功=============================
scala> val rdd4=rdd1.repartition(5)
rdd4: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[6] at repartition at <console>:25
scala> rdd4.partitions.length
res9: Int = 5
scala> rdd1.partitions.length
res10: Int = 3
为什么repartition可以增加分区数量,而coalesce不可以,两者又有什么区别,我们来看一下源码:
repartition方法的源码(源码在RDD.scala搜索即可):
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
coalesce(numPartitions, shuffle = true)
}
从源码可以看出,repartition方法体调用了coalesce方法,该coalesce方法有2个参数,第2个参数是shuffle = true。再来看一下coalesce方法的源码:
def coalesce(numPartitions: Int, shuffle: Boolean = false,
partitionCoalescer: Option[PartitionCoalescer] = Option.empty)
(implicit ord: Ordering[T] = null)
: RDD[T] = withScope {.....}
可看到,coalesce方法的第二个参数是shuffle,但是值却是false,这与repartition方法体里调用的coalesce参数值刚好相反。
因此,可以推断出,repartition能够的增加分区的数量的根本原因是将shuffle参数设为了true。
使用建议:因为shuffle是比较消耗资源的,所以如果要减少分区的数量时,尽量使用coalesce。
改变分区数量的应用场景举例:
要执行的操作:
sc.textFile("/words.txt").flatMap(x=>x.split(" ")).map(x=>(x,1)).reduceByKey((x,y)=>x+y).saveAsTextFile("/out")
假如words.txt文件很大,那么会产生很多个分区,比如1000个分区,每个分区数据量可能有点小。
如果直接保存数据到hdfs上,那么会产生很多个小文件(hdfs不适合处理小文件)。
为了减少在hdfs生成的小文件数量,可以在saveAsTextFile("/out")之前添加一个步骤来减少分区数量,代码如下:
val rdd4=sc.textFile("/words.txt").flatMap(x=>x.split(" ")).map(x=>(x,1)).reduceByKey((x,y)=>x+y)
val rdd5=rdd4.coalesce(5)
rdd5.saveAsTextFile("/out")
有无shuffle的示意图:
可以看到,减少分区数量如果使用repartition会产生shuffle,shuffle阶段要进行计算分区号和交叉传送等操作,明显麻烦比无shuffle时麻烦很多,消耗资源。
11 map、mapPartitions、mapPartitionsWithIndex
val rdd1=sc.parallelize(1 to 10,5)
rdd1.map(x => x*10)).collect
rdd1.mapPartitions(iter => iter.map(x=>x*10)).collect
//map:用于遍历RDD,将函数f应用于每一个元素,返回新的RDD(transformation算子)。
//mapPartitions:用于遍历操作RDD中的每一个分区,返回生成一个新的RDD(transformation算子)。
总结:
如果在映射的过程中需要频繁创建额外的对象,使用mapPartitions要比map高效
比如,将RDD中的所有数据通过JDBC连接写入数据库,如果使用map函数,可能要为每一个元素都创建一个connection,这样开销很大,如果使用mapPartitions,那么只需要针对每一个分区建立一个connection。
mapPartitionsWithIndex的使用:
scala> val rdd1=sc.parallelize(1 to 5,2)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[7] at parallelize at <console>:24
//index表示分区号 可以获取得到每一个元素属于哪一个分区
scala> rdd1.mapPartitionsWithIndex((index,iter)=>iter.map(x=>(index,x))).collect
res11: Array[(Int, Int)] = Array((0,1), (0,2), (1,3), (1,4), (1,5))
12 foreach、foreachPartition
val rdd1 = sc.parallelize(List(5, 6, 4, 7, 3, 8, 2, 9, 1, 10))
//foreach实现对rdd1里的每一个元素乘10然后打印输出
rdd1.foreach(x=>println(x * 10))
//foreachPartition实现对rdd1里的每一个元素乘10然后打印输出
rdd1.foreachPartition(iter => iter.foreach(x=>println(x * 10)))
//foreach:用于遍历RDD,将函数f应用于每一个元素,无返回值(action算子)。
//foreachPartition: 用于遍历操作RDD中的每一个分区。无返回值(action算子)。
总结:一般使用mapPartitions或者foreachPartition算子比map和foreach更加高效,推荐使用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号