spark(3)初识spark程序
初识spark程序
普通模式提交 (指定活着的master地址)
指定的必须是alive状态的Master地址,否则会执行失败。
cd /kkb/install/spark
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://node01:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
examples/jars/spark-examples_2.11-2.3.3.jar \
10
####参数说明
--class:指定包含main方法的主类
--master:指定spark集群master地址
--executor-memory:指定任务在运行的时候需要的每一个executor内存大小
--total-executor-cores: 指定任务在运行的时候需要总的cpu核数
examples/jars/spark-examples_2.11-2.3.3.jar :是spark程序打包成的jar包,spark提供的计算圆周率的测试包
10 :spark程序要用到的参数
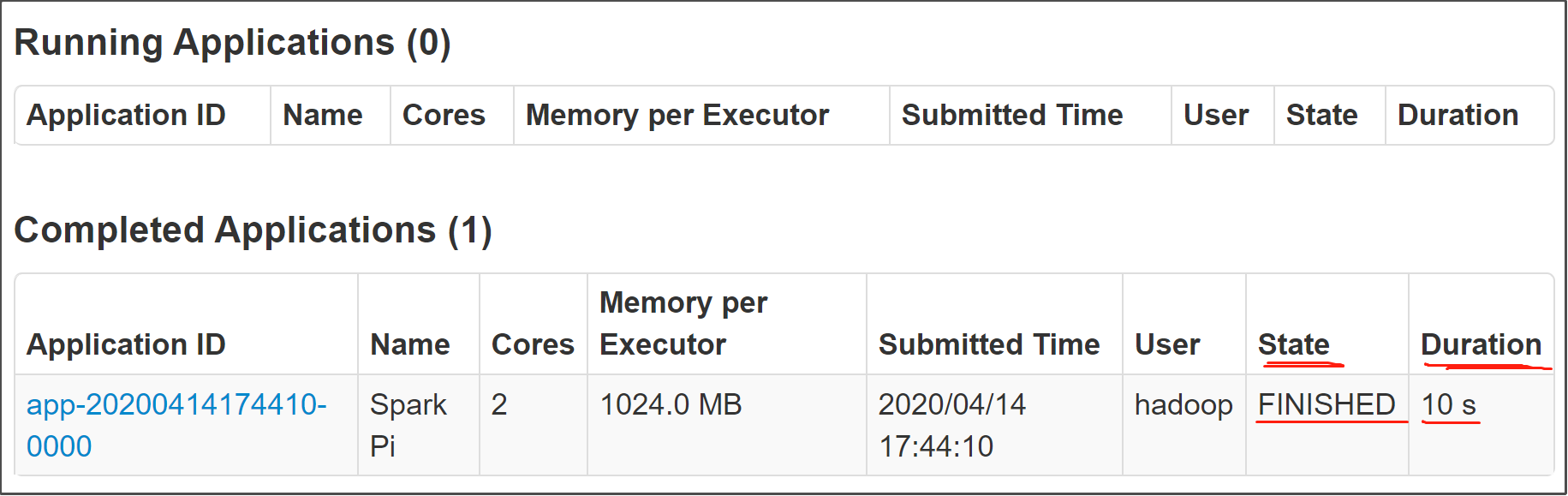
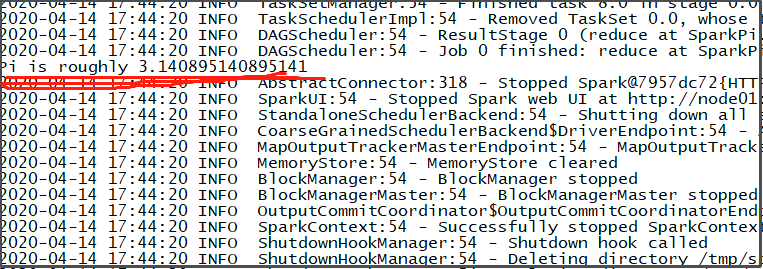
运行结果查看:
高可用模式提交 (集群有很多个master)
当Master有多个的时候,上面的提交方式就显得很麻烦了,因为要找到alive状态的Master很费时间。
企业中,一般都是固定几台机器来启动Master,然后使用高可用模式提交,这个模式会轮询尝试连接Master列表中的Master,连接成功了就将spark程序提交上去。
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://node01:7077,node02:7077,node03:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
examples/jars/spark-examples_2.11-2.3.3.jar \
10
spark集群中有很多个master,并不知道哪一个master是活着的master,即使你知道哪一个master是活着的master,它也有可能下一秒就挂掉,这里就可以把所有master都罗列出来
--master spark://node01:7077,node02:7077,node03:7077
后期程序会轮训整个master列表,最终找到活着的master,然后向它申请计算资源,最后运行程序。
