spark(1) spark是什么、spark四大特性、spark集群架构
spark是什么
"Apache Spark" is a unified analytics engine for large-scale data processing.
spark是针对于大规模数据处理的统一分析引擎
spark是在Hadoop基础上的改进,是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于map reduce算法实现的分布式计算,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出和结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。
spark是基于内存计算框架,计算速度非常之快,但是它仅仅只是涉及到计算,并没有涉及到数据的存储,后期需要使用spark对接外部的数据源,比如hdfs。
注意:spark只做计算不做存储
spark的四大特性
查看官网可以了解spark的四大特性,spark官网地址:http://spark.apache.org/
速度快
spark运行速度相对于hadoop提高100倍,见下图:
Apache Spark使用最先进的DAG调度程序,查询优化程序和物理执行引擎,实现批量和流式数据的高性能。

spark比MR快的2个主要原因(面试题)
1、基于内存
mapreduce任务后期再计算的时候,每一个job的输出结果会落地到磁盘,后续有其他的job需要依赖于前面job的输出结果,这个时候就需要进行大量的磁盘io操作。性能就比较低。
spark任务后期再计算的时候,job的输出结果可以保存在内存中,后续有其他的job需要依赖于前面job的输出结果,这个时候就直接从内存中获取得到,避免了磁盘io操作,性能比较高
对于spark程序和mapreduce程序都会产生shuffle阶段,在shuffle阶段中它们产生的数据都会落地到磁盘。
2、进程与线程
mapreduce任务以进程的方式运行在yarn集群中,比如程序中有100个MapTask,一个task就需要一个进程,这些task要运行就需要开启100个进程。
spark任务以线程的方式运行在进程中,比如程序中有100个MapTask,后期一个task就对应一个线程,这里就不再是进程,这些task需要运行,这里可以极端一点:只需要开启1个进程,在这个进程中启动100个线程就可以了。
进程中可以启动很多个线程,而开启一个进程与开启一个线程需要的时间和调度代价是不一样。 开启一个进程需要的时间远远大于开启一个线程。
易用性
可以通过 java/scala/python/R/SQL等不同语言快速去编写spark程序

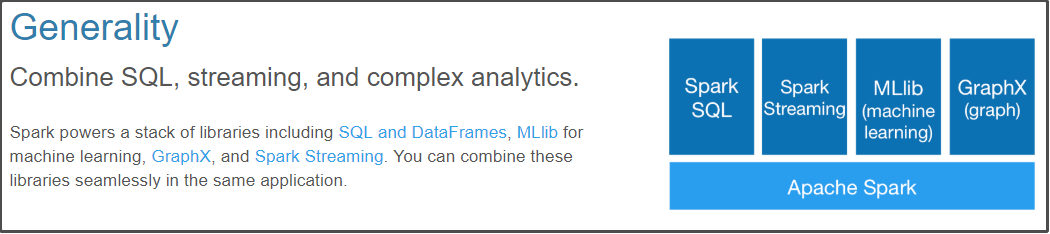
通用性
spark框架不在是一个简单的框架,可以把spark理解成一个spark生态系统,它内部是包含了很多模块,基于不同的应用场景可以选择对应的模块去使用,见下图:
- sparksql:通过sql去开发spark程序做一些离线分析
- sparkStreaming:主要是用来解决公司有实时计算的这种场景
- Mlib:它封装了一些机器学习的算法库
- Graphx:图计算
兼容性
spark程序就是一个计算逻辑程序,这个任务要运行就需要计算资源(内存、cpu、磁盘),哪里可以给当前这个任务提供计算资源,就可以把spark程序提交到哪里去运行。
目前主要的运行方式是下面的standAlone和yarn。
standAlone:它是spark自带的独立运行模式,整个任务的资源分配由spark集群的老大Master负责
yarn:可以把spark程序提交到yarn中运行,整个任务的资源分配由yarn中的老大ResourceManager负责
mesos:它也是apache开源的一个类似于yarn的资源调度平台

spark集群架构(重要)
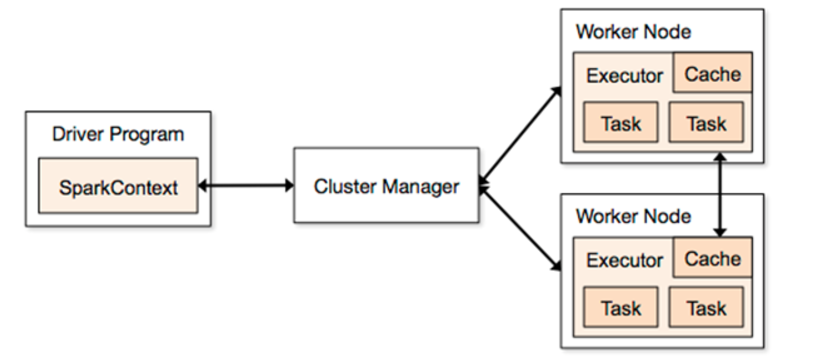
- Driver:执行客户端写好的main方法,它会构建一个名叫SparkContext对象,该对象是所有spark程序的执行入口
- Application:就是一个spark的应用程序,它是包含了客户端的代码和任务运行的资源信息
- ClusterManager:给程序提供计算资源的外部服务,在不同的运行平台,ClusterManager也不同,主要有以下3种:
- standAlone:它是spark自带的集群模式,整个任务的资源分配由spark集群的老大Master负责
- yarn:可以把spark程序提交到yarn中运行,整个任务的资源分配由yarn中的老大ResourceManager负责
- mesos:它也是apache开源的一个类似于yarn的资源调度平台。
- Master:它是整个spark集群的主节点,负责任务资源的分配
- Worker:它是整个spark集群的从节点,负责任务计算的节点
- Executor:它是一个进程,它会在worker节点启动该进程(计算资源),一个worker节点可以有多个Executor进程
- Task:spark任务是以task线程的方式运行在worker节点对应的executor进程中

 浙公网安备 33010602011771号
浙公网安备 33010602011771号