
机器学习-线性回归
~~~不积跬步,无以至千里~~~
为了更好的学习线性回归,首先复习一次函数的特性:
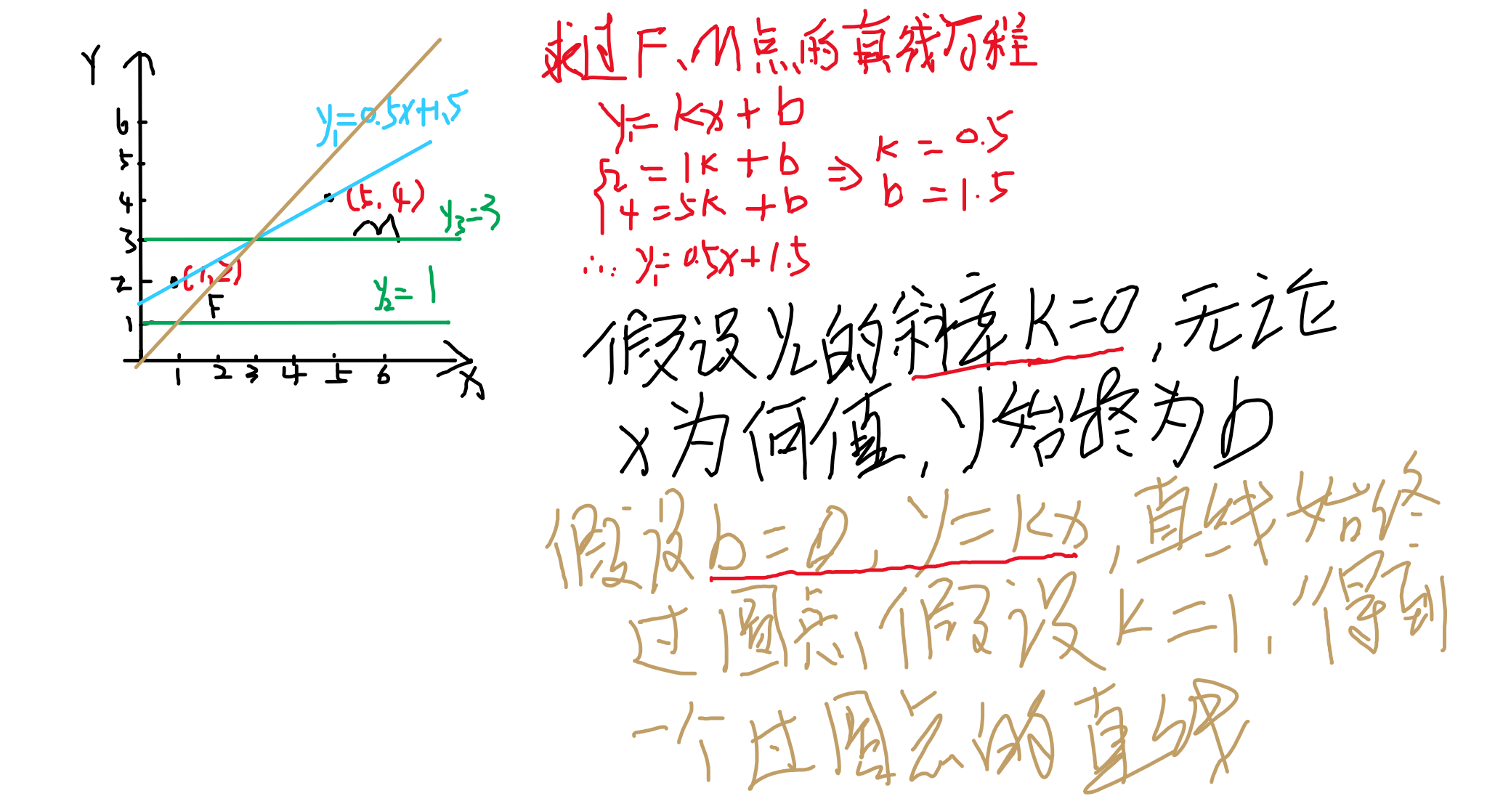
什么是线性回归?
假设现在有一些数据点,我们利用一条直线对这些点进行拟合(该线称为最佳拟合直线),这个拟合过程就称作为回归,如下图所示:

回归问题分为模型的学习和预测两个过程。基于给定的训练数据集构建一个模型,根据新的输入数据预测相应的输出。
回归问题按照输入变量的个数可以分为一元回归和多元回归;按照输入变量和输出变量之间关系的类型,可以分为线性回归和非线性回归。
一元线性回归
在回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线表示,这种回归分析称为一元线性回归分析,可以用y=ax+b表示。假设有一个房屋销售的数据如下(例子来源于网络):
面积(m^2) 销售价钱(万元)
123 250
150 320
87 160
102 220
… …
根据面积和总价作图,x轴是房屋的面积,y轴是房屋的售价:

利用曲线对数据集进行拟合,如果这个曲线是一条直线,那就被称为一元线性回归。
假设要销售一个新的面积,没有对应的价格,这个时候可以用一条曲线去尽量准的拟合原始数据,然后根据新的面积,在将曲线上这个点对应的值返回。如果用一条直线去拟合,可能是下面的样子:

绿色的点就是我们想要预测的点。
机器学习过程:首先给出一个输入数据,我们的算法会通过一系列的过程得到一个估计的函数,这个函数有能力对没有见过的新数据给出一个新的估计,也被称为构建一个模型。就如同上面的线性回归函数。

多元线性回归
假设我去银行申请贷款,银行会根据我们的工资、年龄等条件给我们计算贷款额度。假设额度只与年龄和工资有关,下面有5个申请人的基本信息(样本)。那么,如何根据这些数据构建一个模型,来预测其他人的贷款额度呢?(表格数据来源于网络)
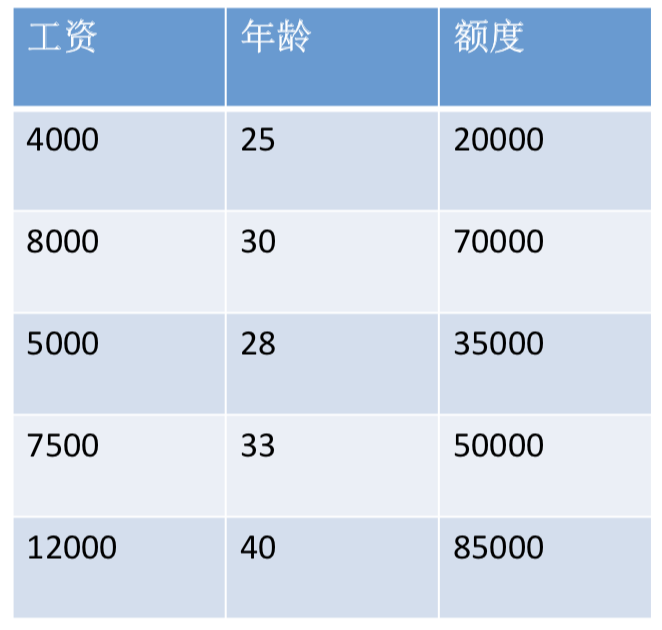
对于一个线性关系,我们使用y=ax+b表示,但在这种关系中y只受一个x的影响,二者的关系可用一条直线近似表示,这种关系叫一元线性回归。
而在本例中,额度(Y)工资(X1)和年龄(X2)的影响,可以近似的看成下图:
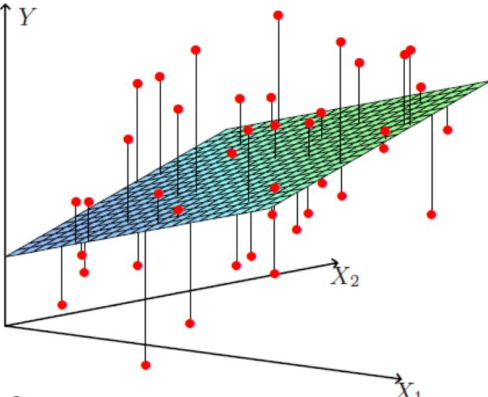
图中红点为样本数据,现在,我们的目标是根据给定的数据集拟合一个平面,使得各个样本数据到达平面的误差最小。由此得到线性回归的模型函数:![]() 。额度受到多个变量的影响,称之为多元线性回归。
。额度受到多个变量的影响,称之为多元线性回归。
- 参数θ1 、θ2为权重项,对结果影响较大;
- 参数θ0为偏置项,因为偏置项不与数据组合,在数据预处理时,需要数据前加入值为1一列,才能保证偏置项值不变。偏置项也可以看成是回归函数的截距,如果没有偏置项,则导致所有的拟合平面都要经过圆点(0,0),所以在处理数据时不要忘记加入偏置项。偏置项的理解请点击此处
将上式中的θ和x分别表示成两个一维矩阵[θ0 θ1 θ2]和[x0 x1 x2],则可将上式化为![]() (x0为我们加入的一列,每个值为1)。
(x0为我们加入的一列,每个值为1)。
然而,实际结果不可能完全符合我们的预期,样本和拟合平面必定存在误差,假设对于每一个样本,都存在:![]() (实际值=预测值+误差),其中
(实际值=预测值+误差),其中![]() 为真实误差。
为真实误差。
误差 独立并且具有相同的分布(通常认为是均值为0的高斯分布)。
独立并且具有相同的分布(通常认为是均值为0的高斯分布)。
- 独立:每个红点到拟合平面的距离都不相同
- 相同的分布:可以理解成在同一家银行申请信用卡(因为每个银行的额度评估标准不同)
因此,把误差值![]() 带入高斯分布函数:
带入高斯分布函数: ,得到概率密度函数:
,得到概率密度函数:
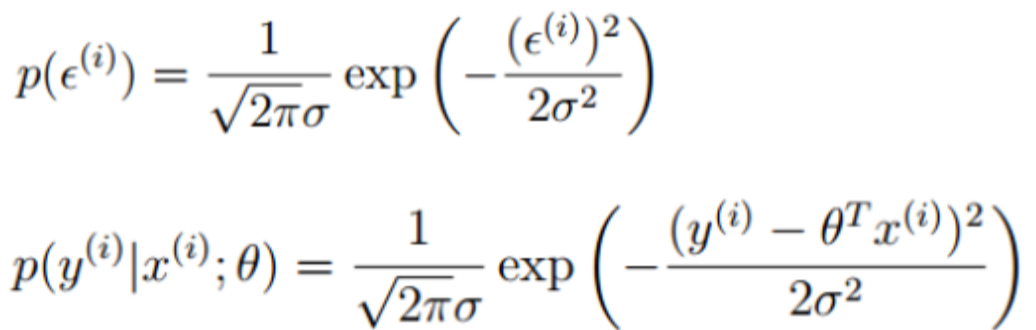
{ p(y|x;θ)表示在给定了参数θ的情况下,给定一个x就能求出对应的y }
因此,如果存在大量的样本,我们就可以通过![]() 和
和![]() 做关于θ的参数估计。
做关于θ的参数估计。
这里思考一个问题:当误差![]() 趋于0时,预测的值越接近真实值。上面的概率密度函数是不是可以理解为:参数θ和x样本数据组合后的预测值接近y的概率越大越好呢?x是已知的样本数据,要想误差
趋于0时,预测的值越接近真实值。上面的概率密度函数是不是可以理解为:参数θ和x样本数据组合后的预测值接近y的概率越大越好呢?x是已知的样本数据,要想误差![]() 趋于0时,那么预测值要越大越好(越接近真实值),也就是参数θ越大越好。那么怎样才能让参数θ越大越好呢?
趋于0时,那么预测值要越大越好(越接近真实值),也就是参数θ越大越好。那么怎样才能让参数θ越大越好呢?
引入似然函数:
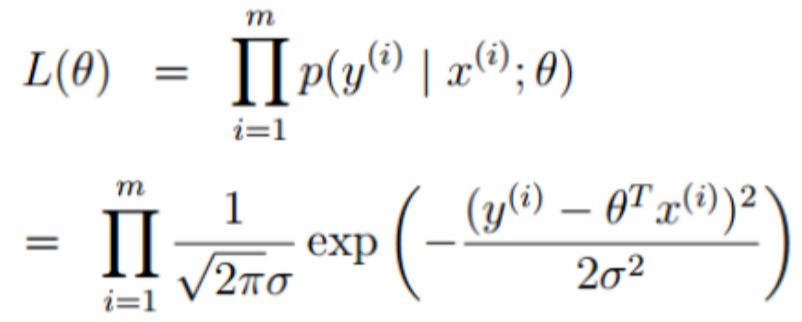
极大似然估计定义:
对于因变量Y,最大似然估计就是去找到Y的参数值θ ,使其发生概率最大,利用已知的样本结果,反推最有可能(最大概率)导致这样结果的参数值θ 。
由极大似然估计的定义,我们需要L(θ )最大,需要两边取对数对这个表达式进行化简如下:
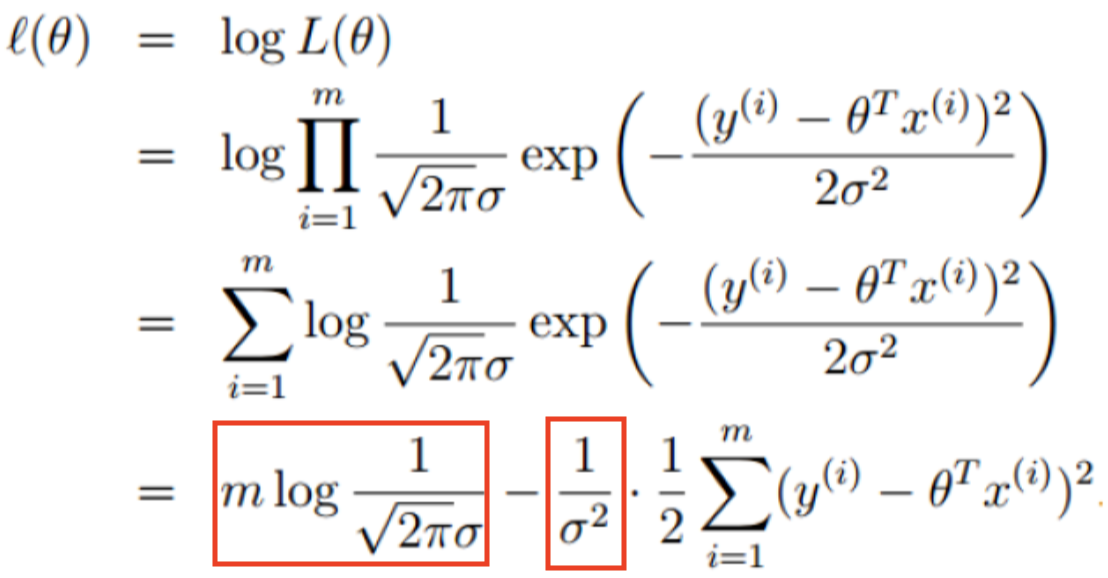
红色方框被标记的两个部分均为常数,不会影响最终结果。因此,减法后面的式子应当越小越好:
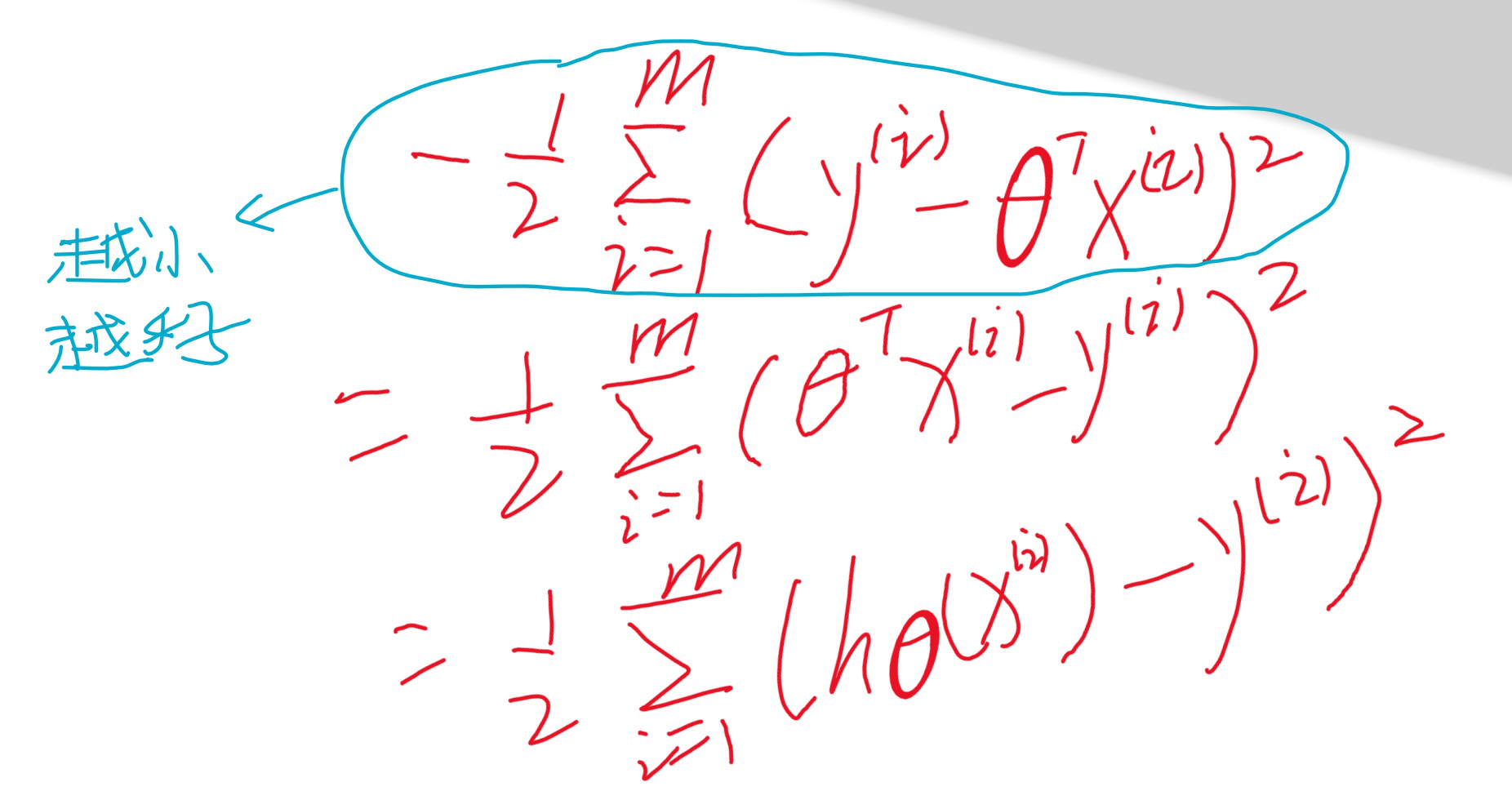
化简后得到目标函数:
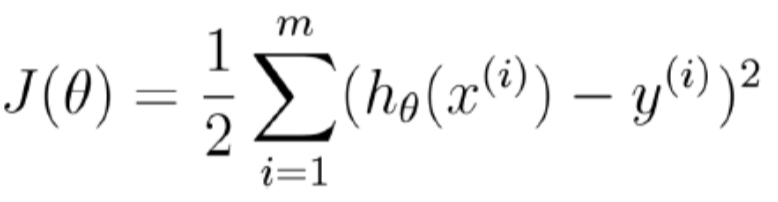 (最小二乘法)
(最小二乘法)
最小二乘法定义:最小二乘法又称最小平方法,它通过最小化误差的平方和寻找数据的最佳函数匹配。利用最小二乘法可以简便地求得未知的数据,并使得这些求得的数据与实际数据之间误差的平方和为最小。
接下来最小化目标函数,θ 取何值的时,目标函数取得最小值,而目标函数连续,那么 θ 一定为目标函数的极值点,因此对目标函数求偏导就可以找到极值点。将上式化简,并对θ求偏导(矩阵求导知识):
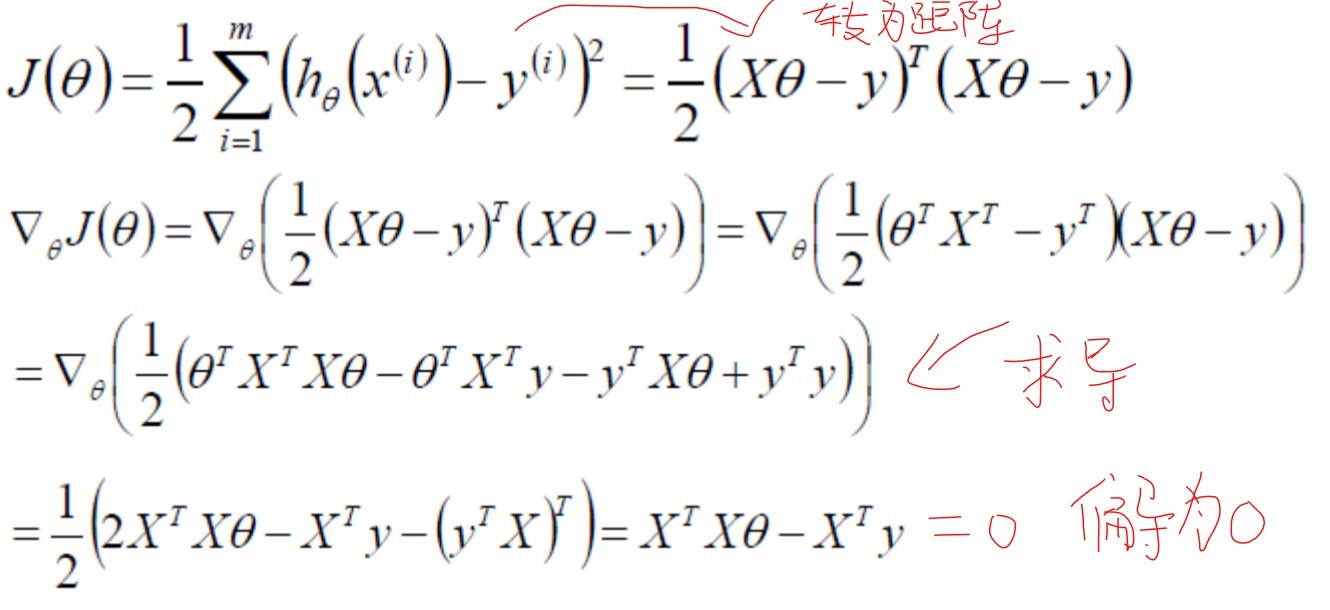
化简过程:

最终结果:
![]()
代码的实现:
首先导入三大件:
import numpy as np import pandas as pd import matplotlib.pyplot as plt
数据集分布情况:
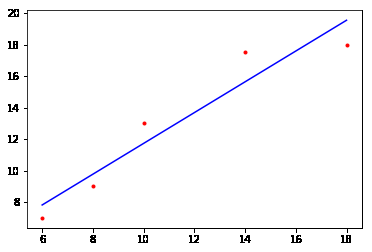
#数据分布情况展示 x_train = [[6], [8], [10], [14], [18]] y_train = [[7], [9], [13], [17.5], [18]] x_train = np.array(x_train) #把数据转换为ndarray结构方便矩阵计算 y_train = np.array(y_train) #把数据转换为ndarray结构方便矩阵计算 plt.plot(x_train,y_train,'r.') plt.show()

计算损失值:
# 计算损失值得函数 def cost(x,y,k,b): cost = 0 for i in range(len(x)): cost += (y[i] - (x[i] * k + b)) ** 2 return cost / (2 * len(x))
定义基本变量:
k = 0 # 定义参数 b = 0 # 定义截距 lr = 0.001 # 步长 apochs = 5000 # 迭代次数
梯度下降函数:
# 梯度下降函数 def gradient_descent(x,y,k,b,lr,apochs): m = len(x) for i in range(apochs): k_grad = 0 b_grad = 0 for j in range(len(x)): b_grad += (-1/m) * (y[j] - (k * x[j] + b)) #对b求导 k_grad += (-1/m) * (y[j] - (k * x[j] + b)) * x[j] #对k求导 k = k - lr * k_grad #参数更新 b = b - lr * b_grad #参数更新 return k,b
最后结果:
print("staring: k= {} b={} cost={}".format(k,b,cost(x_train,y_train,k,b))) #进行梯度下降前的值 k,b = gradient_descent(x_train,y_train,k,b,lr,apochs) print("runing......") print("ending: k= {} b={} cost={}".format(k,b,cost(x_train,y_train,k,b))) # 梯度下降后损失值由原来的93降到了0.9 plt.plot(x_train,y_train,'r.') plt.plot(x_train,k * x_train + b,'b') plt.show()
使用sklearn模块实现:
from sklearn.linear_model import LinearRegression model = LinearRegression() #创建线性回归模型 model.fit(x_train, y_train) #把数据放入模型 xx = np.linspace(0, 26, 100)#生成了0-26之间(包含0和26)的1行100列的一个矩阵 #print(xx) xx = xx.reshape(-1, 1)#将1行100列的矩阵转化成100行1列的矩阵形式 #print(xx) yy = model.predict(xx) #根据假设的xx值,进行预测 plt.scatter(x_train, y_train) plt1, = plt.plot(xx, yy, label="Degree=1") plt.axis([0, 25, 0, 25]) plt.xlabel('pizza size') plt.ylabel('Pizza price') plt.legend() plt.show() print('model score:', model.score(x_train, y_train)) # 模型评分

end~

