Redis构建处理海量数据的大型购物网站
本系列教程内容提要
Java工程师之Redis实战系列教程教程是一个学习教程,是关于Java工程师的Redis知识的实战系列教程,本系列教程均以解决特定问题为目标,使用Redis快速解决在实际生产中的相关问题,为了更方便的与大家一起探讨与学习,每个章节均提供尽可能详细的示例源码及注释,所有示例源码均可在javacourse-redis-in-action找到相关帮助!
什么是大型网站?
从技术上的角度来看,大型网站的实现是能够应对各种突发事件,能够处理海量数据等因素.... 这里我们抓住“处理海量数据”这一点来进行探讨学习。
何提高网站处理海量数据?
- 减少用户请求体大小
- 响应数据进行缓存

我们应该怎么做?
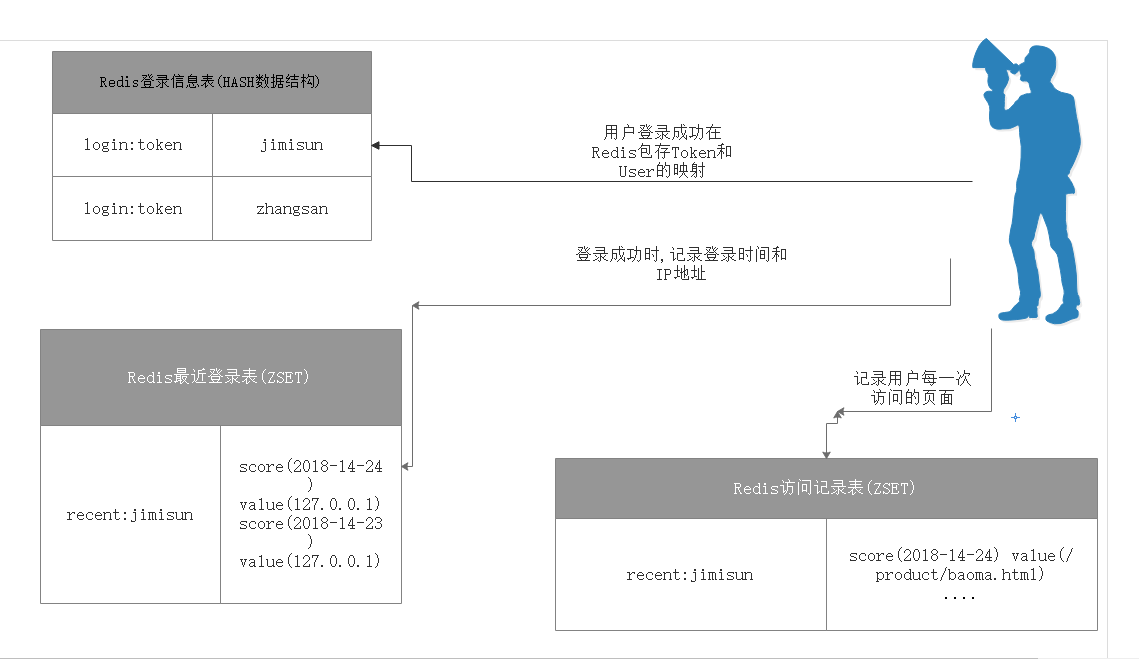
第一步:拒绝cookie,使用token令牌登录 github示例源码下载
Cookie是常见的记录用户会话的解决方案,但在某些场景下其并不适用,如前后端分离,如Cookie体积大时影响请求速率。
- 用户发起操作请求
- Redis校验是否拥有TOKEN令牌
- 没有令牌跳转登录
- 登录成功生成TOKEN保存至Redis
- ......
Redis数据结构
核心源码
@RequestMapping("/register")
public String register(User user, Model model) {
userFactory.put(user.getUsername(), user);
model.addAttribute("result", "注册成功!");
return "RegAndLog";
}
@RequestMapping("/login")
public String login(User user, Model model, @RequestParam(required = false) String token, HttpServletRequest request) {
Boolean exists = jedis.exists("login:" + token);
String clientIp = getClientIp(request);
String url = getURL(request);
if (!exists) {
User result = userFactory.get(user.getUsername());
if (result != null && user.getUsername().equals(result.getUsername()) && user.getPassword().equals(result.getPassword())) {
/*将用户登录缓存到Redis*/
String tokenUUID = UUID.randomUUID().toString();
updateToken(jedis, tokenUUID, result, clientIp, url);
/*获取用户的登录记录*/
Set<String> IPList = jedis.zrange("recent:" + user.getUsername(), 0, -1);
/*获取用户最新访问的页面*/
Set<String> URLList = jedis.zrange("viewed:" + user.getUsername(), 0, -1);
model.addAttribute("record", IPList);
model.addAttribute("URLList", URLList);
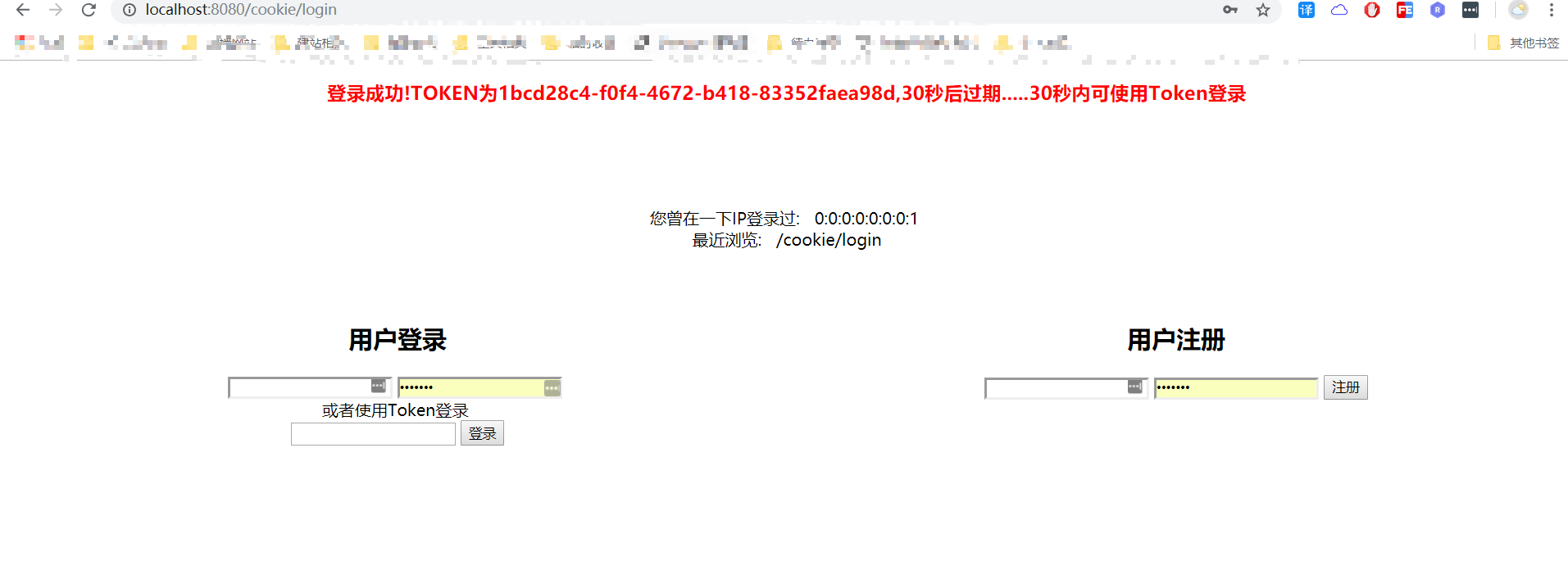
model.addAttribute("result", "登录成功!TOKEN为" + tokenUUID + ",30秒后过期.....30秒内可使用Token登录");
return "RegAndLog";
}
model.addAttribute("result", "登录失败!");
return "RegAndLog";
}
model.addAttribute("result", "使用Token登录成功!");
return "RegAndLog";
}
各位友友运行本小结源码:访问 http://localhost:8080/cookie/LogOrReg
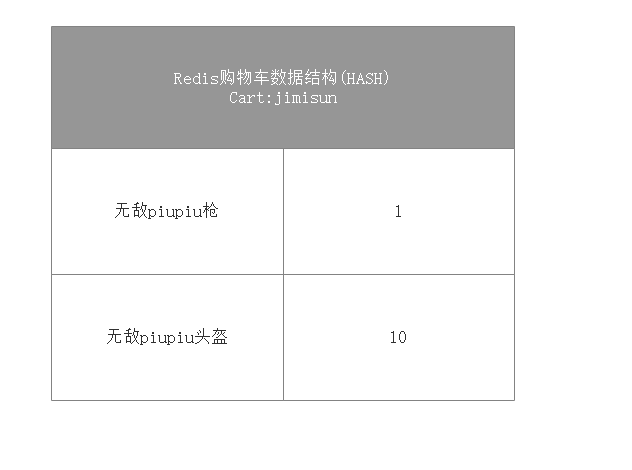
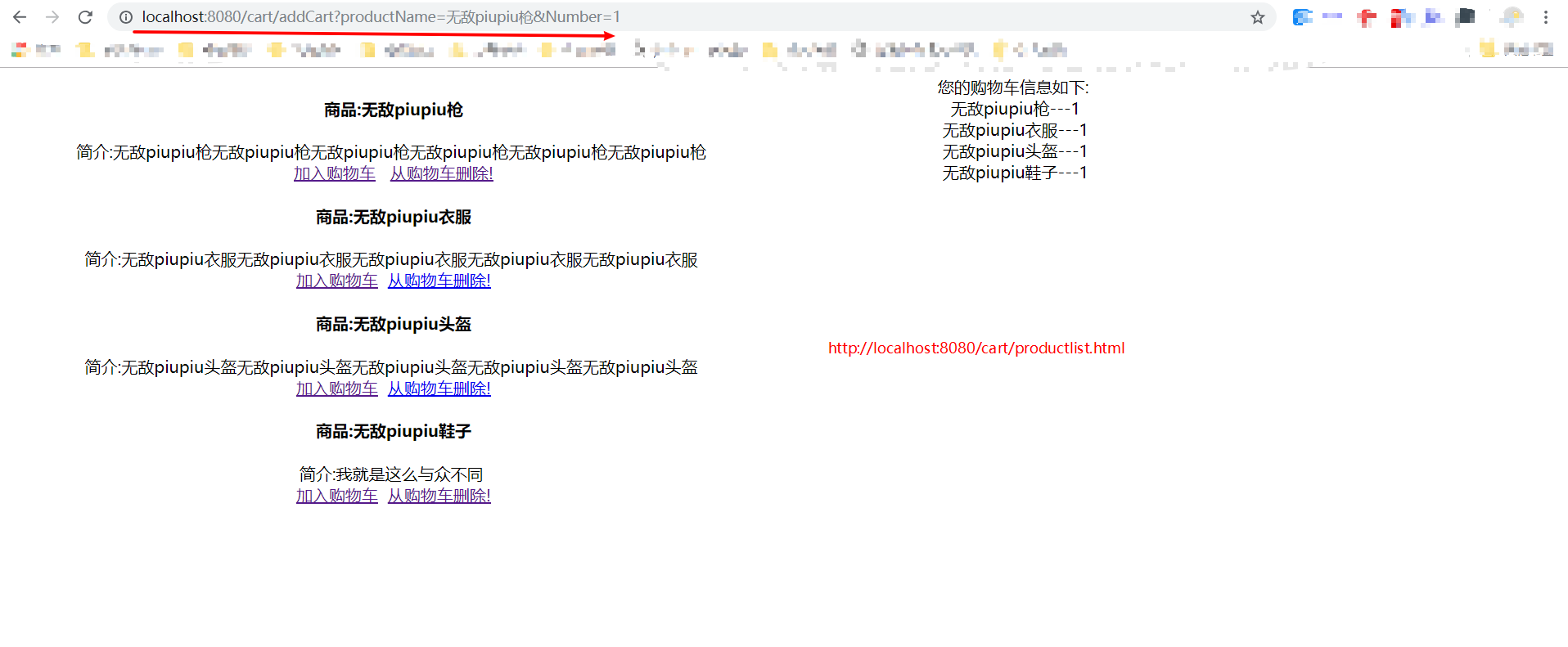
第二步:拒绝cookie,使用Redis构造购物车 github示例源码下载
对于一个购物网站来说,购物车就是一个必不可少的功能,从长远来看对用户购物车的数据的统计与分析有利于进行大数据的分析,提高网站的营业额。但在服务端每次解析,校验,设置Cookie,会增加程序的响应时间。同样;随着Cookie体积的增大,也会增加用户请求时间,所以我们在Redis上进行包存购物车。
Redis数据接结构
核心源码
@GetMapping("/addCart")
public String addCart(Item item, Model model) {
User user = getUser();
addTOCart(jedis, user, item);
Map<String, String> cart = getCart(jedis, user);
model.addAttribute("result", "添加购物车成功!");
model.addAttribute("cartList", cart);
return "ProductList";
}
各位友友运行本小结源码:访问 http://localhost:8080/cart/productlist.html
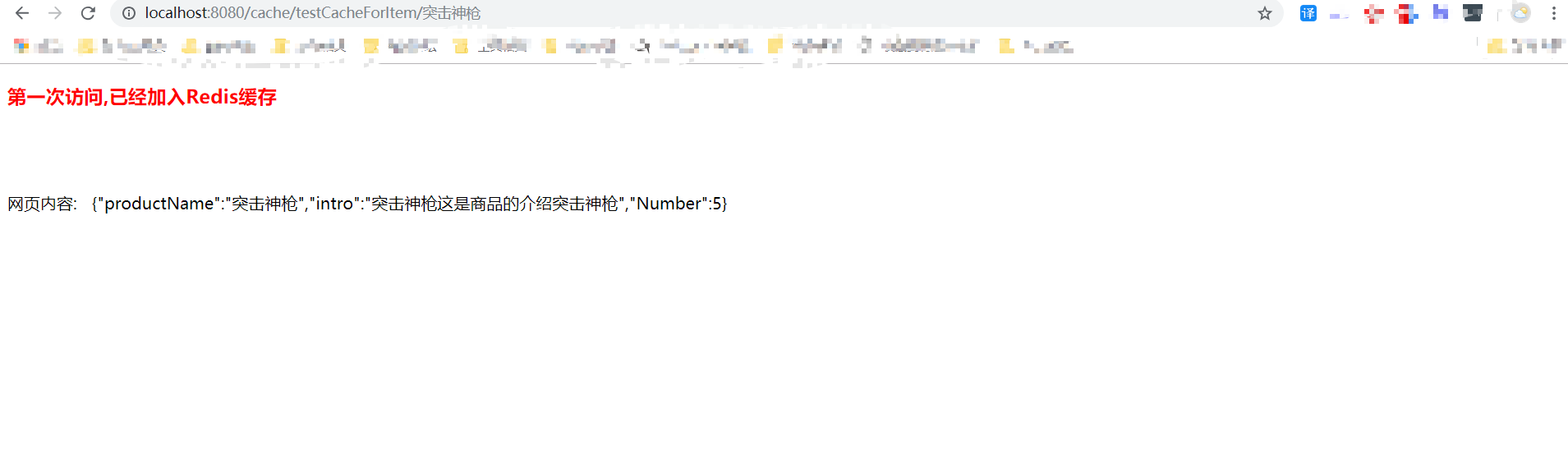
第三步:缓存网页数据,提高网页响应 github示例源码下载
对于我们网站的大多数网页,一般都很少改动,例如商品页面,商品的标题和商品的介绍基本上不会改动,但是商品的剩余数量你又不得不去数据库实时查询,这将会导致“用户每打开或刷新一次网页,你不得不去数据库查询一次数据”,对于一般的关系数据库数据库每秒处理200~2000上限,就成为了你网站的瓶颈所在。
Reids数据结构图

核心源码
@RequestMapping("/testCacheForItem/{itemname}")
public String testCacheForItem(Model model, @PathVariable(required = true, name = "itemname") String itemname) {
/*模拟数据*/
Item item = new Item(itemname, itemname + "这是商品的介绍" + itemname, new Random().nextInt(10));
/*判断是否被缓存*/
Boolean hexists = jedis.exists("cache:" + itemname);
if (!hexists) {
Gson gson = new Gson();
String s = gson.toJson(item);
jedis.set("cache:" + itemname, s);
model.addAttribute("s", s);
model.addAttribute("result", "第一次访问,已经加入Redis缓存");
return "CacheItem";
}
String s = jedis.get("cache:" + itemname);
model.addAttribute("s", s);
model.addAttribute("result", "重复访问,从Redis中读取数据");
return "CacheItem";
}
各位友友运行本小结源码:访问 http://localhost:8080/cache/testCacheForItem/吃鸡神枪

本章小结
对于真正实现一个能处理海量数据的购物网站来说,我们做的实在是太简单了...是使用各种语言和工具的相互配置,程序逻辑的优化,才能构建出一个真正的能处理海量数据的网站。当然我们做的也不差....hhhh

 浙公网安备 33010602011771号
浙公网安备 33010602011771号