
BEVDet的进阶BEVPoolv2:A Cutting-edge Implementation of BEVDet Toward Deployment
论文地址:
代码地址:
整体思想:
作者从工程优化的角度考虑优化BEVDet,提出了BEVPoolv2,优化视图转换过程,使其在计算和存储方面降低消耗。它通过省略视锥体特征的计算和预处理来实现这一点。处理640 * 1600的分辨率仅需要0.82ms,比之前的方法快了15.1倍. 此外,与以前的实现相比,它的缓存消耗也更少,这自然是因为它不再需要存储大型视锥体特性,这也使部署到其他平台变得更方便。作者还提供了一个部署到tensorrt的例子,并展示了运行速度。除了BEVPoolv2,作者还选择并集成了过去一年中提出的一些实质性进展。作为示例配置,BEVDet4D-R50-Depth-CBGS在NuScenes验证集上的得分为52.3 NDS,使用PyTorch可以以16.4FPS的速度进行处理。
背景
在自动驾驶中多camera的3D目标检测是一个基础任务,当前已有大量的方法在研究3D目标检测。作者提出了一个叫做bevDet2.0的3D目标检测方法,这是一个面向部署的,在速度和精度方面都做的很好的一个方法。
动机
LSS的方法的缺点是它必须进行计算、存储、预处理大尺度的视锥体特征,这个视锥体的尺度为(N,D,H,W,C),N是相机数量,D是深度,H和W分别是特征的高和宽,C是特征的通道数。如图1左图所示。
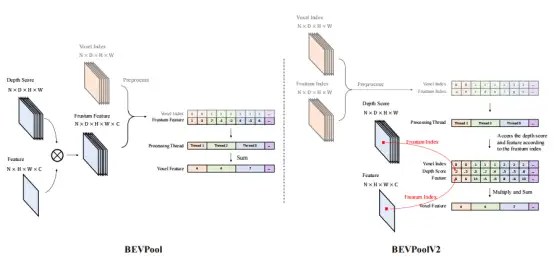
很多基于LSS的方法,都无法避免这种大量的计算,比如BEVFusion,虽然使用多线程进行加速了,但是本质上计算量没有减少,BEVDepth和BEVStereo也是采用了LSS的视图转化方法。如图2和图3所示
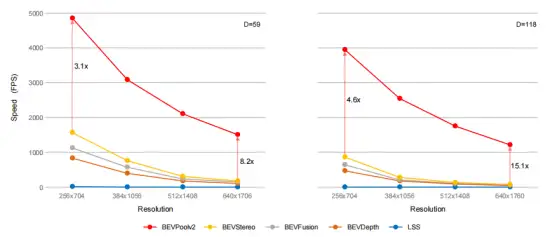
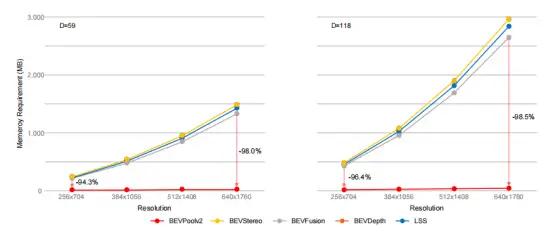
由图可以看出作者的方法可以很大程度上避免内存消耗,优化速度,这也是为工程部署所做的贡献。
作者方法
作者方法的idea很简单,如图1右图所示,作者只使用视锥体点的索引作为它们的轨迹,并使用它们的体素索引单独进行预处理。然后根据视锥体索引访问处理线程中视锥体点特征的值。通过这种方式,不会再有视锥体特征的计算、存储和预处理。因此,可以节省内存和计算,并且可以进一步加快推理速度。体素索引和视锥体索引都可以离线预计算和预处理。在推断过程中,它们只是充当固定参数。也就是说体素索引和视锥体索引都是一一对应的,且是固定的,可以提前计算出来。从图中可以看出,这个方法超快,已经远远优于其他的方法,这使得视图转换不再是BEV的瓶颈。作者的方法取得了52.3的NDS
Tensorrt的部署
作者方法支持Tensorrt的部署,下表为推理速度,硬件平台就是3090 使用resnet50进行推理,下表是推理显示地应该是一个sample需要的时间

