BEVFusion: 一个通用且鲁棒的激光雷达和视觉融合框架

文章arxiv:https://arxiv.org/pdf/2205.13790.pdf
代码已开源:https://github.com/ADLab-AutoDrive/BEVFusion
1 背景简介
感知模块(如3D BBox检测,3D语义分割)一直是自动驾驶系统里最重要的环节之一,为了达到足够的安全冗余,车辆上一般会集成多种传感器,如激光雷达,摄像头,毫米波雷达等,这些传感器特性不同,能够起到很好的互补作用。在面向L4的自动驾驶系统里,激光雷达(后面简称雷达)和摄像头(通常也称为视觉)起到的作用会更加重大,所以无论是学术上还是工业上,这二者的融合算法一直都是一个非常热门的研究领域。
通常,雷达和视觉的融合策略分为三种类型:决策层融合(通常我们称为后融合),决策+特征融合(中间层融合),特征融合(前融合),后融合就是将基于雷达的模型输出的最终结果,比如3D BBox, 和视觉检测器输出的结果,如2D BBox, 通过滤波算法进行融合;中间层融合是将某一个模态输出的最终结果,投影到另一种模态的深度学习特征层上,然后再利用一个后续的融合网络进行信息融合;前融合则是直接在两种模态的Raw Data或者深度模型的特征层上进行融合,然后利用神经网络直接输出最终的结果。这里有篇文章做了比较详细的介绍;
这几种融合策略当然各有优劣,但是在工业界普遍使用的是后融合,因为这种方案比较灵活,鲁棒性也更好,不同模态的输出的结果通过人工设计的算法和规则进行整合,不同模态在不同情况下会有不同的使用优先级,因此能够更好的处理单一传感器失效时对系统的影响。但是后融合缺点也很多,一是信息的利用不是很充分,二是把系统链路变得更加复杂,链路越长,越容易出问题,三是当规则越堆叠越多之后维护代价会很高。学术界目前比较推崇的是前融合方案,能够更好的利用神经网络端到端的特性。但是前融合的方案少有能够直接上车的,原因我们认为是目前的前融合方案鲁棒性达不到实际要求, 尤其是当雷达信号出现问题时,目前的前融合方案几乎都无法处理。
接下来我们就先介绍一下当前前融合方案是大体怎么做的,然后介绍下我们BEVFusion的方案,以及我们在公开数据集NuScenes上的验证结果。
2 问题
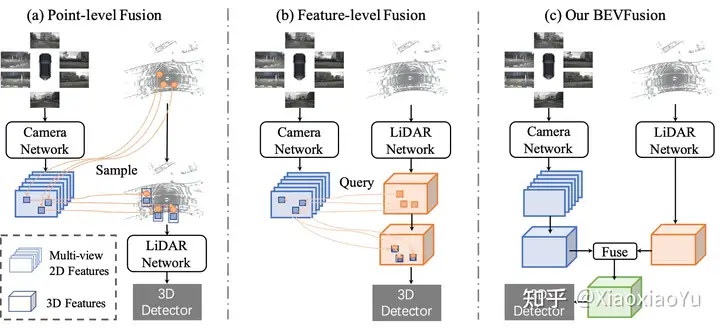
我们将目前SOTA里的前融合方法大致分为两类,一种如图1(a)所示,首先将雷达点,根据外参和相机内参投影到图像或图像提取的2D特征上去采样对应的视觉特征,然后拼接到点云上,后面就可以通过常用的点云3D检测算法进行处理,比如3DSSD[1], PointPillar[2], CenterPoint[3]等,目前PointPainting[4], PointAugment[5]就属于这类工作;第二种如图1(b)所示,先对雷达点云进行特征提取,然后将特征或者初始预测值按照外参和相机内参投影到图像或图像提取的2D特征上去采样对应特征,然后拼接回来,再接上对应的任务头,目前MVXNet[6], TransFusion[9]就属于这种类型的工作。
这两种方案在实际环境下会面临以下几种问题:
1)雷达和相机的外参不准 由于校准问题或车辆运行时颠簸抖动,会造成外参不准,导致点云和图像直接的投影会出现偏差
2)相机噪声 比如镜头脏污遮挡,卡帧,甚至是某个相机损坏等, 导致点云投影到图像上找不到对应的特征或得到错误的特征
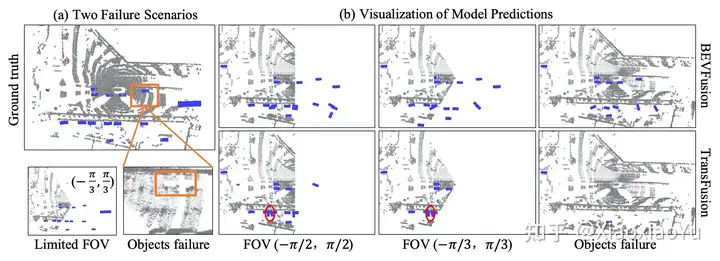
3)雷达噪声 除了脏污遮挡问题;对于一些低反的物体,雷达本身特性导致返回点缺失,我们就在实际场景中发现,在雨天黑色的车辆反射点就极少,如图2所示;另外对于某些车型,比如国内新发售的蔚来ET7,其激光雷达的FOV本来就只会覆盖到一个有限的角度;
对于问题1)和2),一些方法已经提供一些兼容能力,比如DeepFusion[7],但是对于问题3)雷达噪声导致的点云缺失,都是无能为力的。因为这类方法都需要通过点云坐标去Query图像特性,一旦点云缺失,所有的手段都无法进行了。所以我们提出了BEVFusion的框架,和之前的方法不同的是雷达点云的处理和图像的处理是独立进行的,利用神经网络进行编码,投射到统一的BEV空间,然后将二者在BEV空间上进行融合。这种情况下雷达和视觉没有了主次依赖,从而能够实现近似后融合的灵活性:单一模态可以独立进行完成任务,当增加多种模态后,性能会大幅提高,但是当某一模态缺失或者产生噪声,不会对整体产生破坏性结果。

3 方法
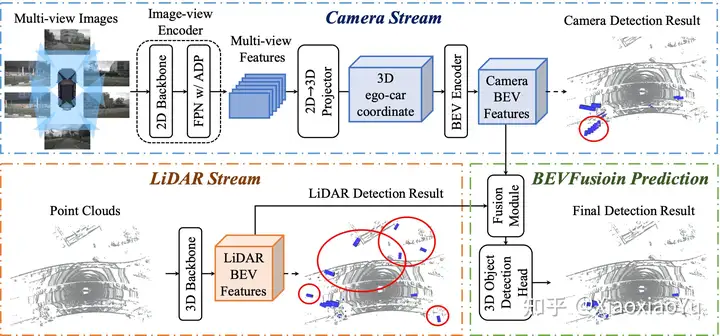
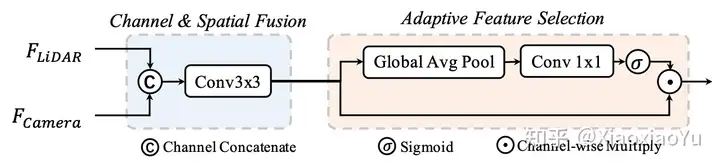
具体实现方法如图3所示,作为一个通用框架,雷达分支和视觉分支都可以采用多种不用的结构,雷达分支我们测试了基于Voxel和基于Pillar的编码方式,Camera分支是我们对Lift-Splat-Shoot[8]进行了改造,使其更加适合完成3D BBox检测任务,任务头我们测试了Anchor-based, Anchor-free, 以及TransFusion[9]里使用的基于Transformer的Header,并且我们对Fusion模块也进行了改进,使其能够更加有效的融合不同模态信息,如图4所示。
4 实验
我们的实验主要是在公开数据集NuScenes上进行,它有一个360度FOV的激光雷达和6个环绕式的相机组成,方便验证和对比我们的方法在不同设定下的性能。
4.1 通用性
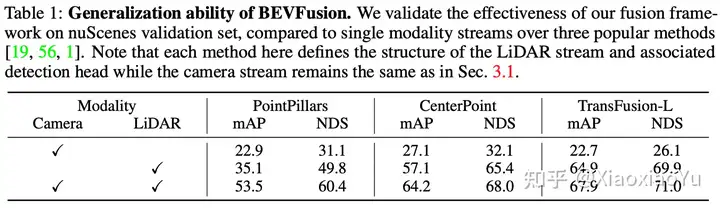
表1里面我们验证了当把雷达分支设置成PointPillar, CenterPoint和TransFusion-L时,BEVFusion带来的提升,可以看到,在PointPillar上,BEVFusion把Lidar-only时的35.1mAP提升到53.5mAP, 提升了17.4 mAP. 对于另外两种Header上,也都有显著提升,证明了BEVFusion具备很高的通用性。值得一提的是,我们在Camera分支上并有使用任何数据增强方法(BEVDet[10]证明这些数据增强方法对提升检测性能很有帮助),因此我们Camera分支自身取得检测性能并不理想(相比BEVDet和BEVFormer[11]低很多),但是即便在这种情况下,对最终融合的性能提升依然十分显著,这也进一步说明了这种融合方法的有效性;而且我们相信如果进一步提升Camera分支的性能,将能够达到更好的效果。
4.2 对比SOTA
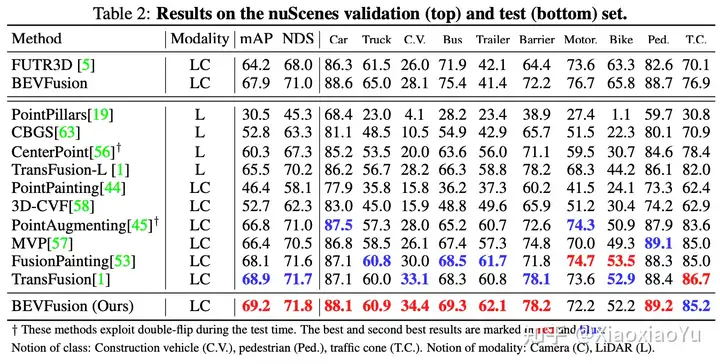
表2里面展示了我们在NuScenes验证集和测试集上的结果,推理时我们没有使用任何测试时增强的方法,比如double-flip,但是仍然超越了目前所有的SOTA方法。
4.3 鲁棒性测试
4.3.1 雷达噪声
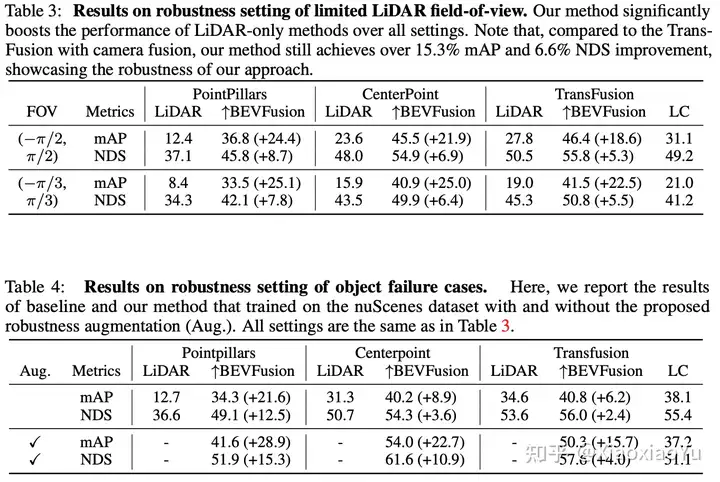
首先我们测试了BEVFusion对雷达的鲁棒性,设置两种不同的情况:1)模拟雷达扫描范围被遮挡,只剩下180度和120度的FOV,即丢弃不在次范围内的点云;2)模拟雷达打在物体表面没有返回点,即按照50%的概率丢弃3D BBox的点。 从图5可以看出,当雷达点云失效后,BEVFusion仍然能够通过视觉给出目标物体,而TransFusion则再无雷达的区域几乎无法给出任何结果。 表3和表4分别给出了定量分析的结果,并显示BEVFusion在训练时加入相应噪声作为数据增强,将取得更大的提升(mAP超越SOTA方法15.7%~28.9%)。
4.3.2 相机噪声
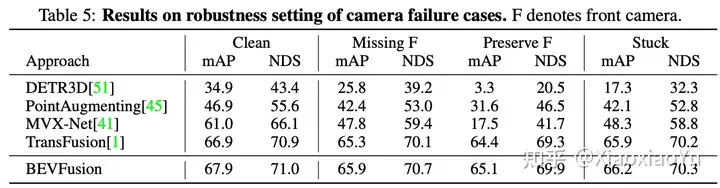
我们测试了加入相机噪声时,BEVFusion的表现;如表5所示,当缺失相机或者卡帧的情况下,BEVFusion的鲁棒性均大幅超越了SOTA方法。
4.4 消融实验
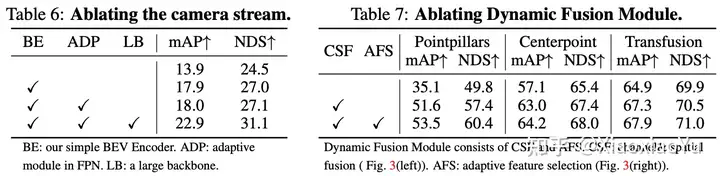
表6里显示了Camera分支中不同的优化手段对检测性能的提升情况;
表7中显示动态融合模块里不同的部分对最终融合性能的影响;
5 总结
我们揭示了目前学术界对前融合研究和工业界实际使用需求的Gap,并提出了BEVFusion,一种通用而且鲁棒的前融合算法,希望能够对大家有所启发,也希望更多的人可以关注实际使用中的鲁棒性问题。
后记:
有趣是这篇工作和MIT韩松团队的另一份工作“撞车”了:BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representation. 不过这两篇文章的立意上区别还是很大的,一个是从工业落地的角度出发,提出解决鲁棒性问题,另一个主要是从模型加速的角度出发,总结来看,BEV层面融合确实是一个比较有前景的方向,期待更多的研究工作可以投入进来,一起推进自动驾驶的落地~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号