神经网络量化流程(第一讲TensorRT)
TensorRT量化工具,支持PTQ和QAT量化
基本流程:读取模型-》转化为IR进行图分析,做一些优化策略
一、TensorRT量化模式
TensorRT有两种量化模式:分别是implicitly以及explicitly量化,前者是隐式量化,在7.0及之前版本用的较多;后者显式量化在8.0版本后才完全支持,就是可以加载带有QDQ信息的模型,然后生成量化版本的Engine;

1、 与隐式量化相关性较繦的训练后量化(PTQ)
不需要训练,只需要提供一些样本图片,然后在已经训练好的模型上进行校准,统计出来每一层的Scale,就可以实现量化

量化流程如下:导出ONNX模型,转换为TensorRT的过程中,使用TRT提供的calibration方法校准,可以使用TRT官方提供的trtexec命令,也可以使用trt提供的python或c++的API接口去量化
训练后量化算法:EntropyCalibrationV2,MinMaxCalibrator,EntropyCalibrator,LegacyCalibrator
量化时,TensorRT会在优化网络时深度Int8精度,采用速度优先方式。
2.训练时量化
直接加载QAT模型,包含QDQ操作的量化模型,QAT过程和TensorRT没有关系,TRT只是个推理框架,实际QAT都是在训练框架中做,如Pytorch。
QAT量化后的ONNX模型如下:
其中有QuantizeLiner和DequantizeLiner,即对应的QDQ模块,包含了该层或激活值的量化Scale和Zero_point。负责将输入的FP32转为Int8,然后进行反量化将Int8转回FP32.实际网络中训练使用的精度还是FP32,只是量化算子在训练中可以学习到量化和反量化的尺度信息,可以在训练中让模型权重和量化参数更好地适应量化过程。

QAT量化中最重要的就是Fake量化算子,它负责将输入该算子的参数,先量化后反量化,同时记录这个scale。

这些FQ算子在ONNX中可以表示为QDQ算子

什么是QDQ?
Q是量化,DQ是反量化,在网络中通常作为模拟量化的op
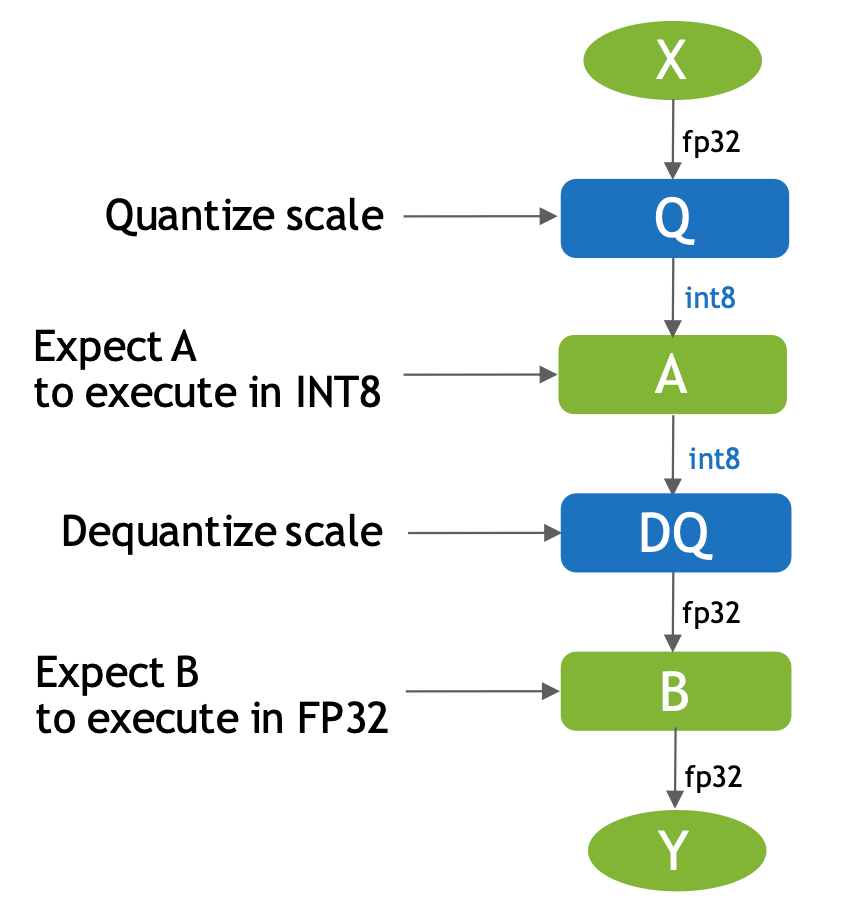
输入X是FP32类型的op,输出是FP32,然后在输入A这个op时会经过Q(即量化)操作,这个时候操作A我们会默认是INT8类型的操作,A操作之后会经过DQ(即反量化)操作将A输出的INT8类型的结果转化为FP32类型的结果并传给下一个FP32类型的op。
QDQ有什么用?
a、存储量化信息,如scale和zero_point,这些信息可以放在Q和DQ操作里;
b、可以当做显式指定哪一层是量化层,可以默认包在QDQ操作中间的op都是Int8类型的可量化的操作

有了QDQ,TensorRT在解析模型时,会根据QDQ位置找到可量化的op,然后和QDQ融合。

QDQ融合策略
融合后该算子就是Int8算子,可以通过调整QDQ位置来设置网络中每个op的精度(某些op必须高精度,因此QDQ位置要放对)
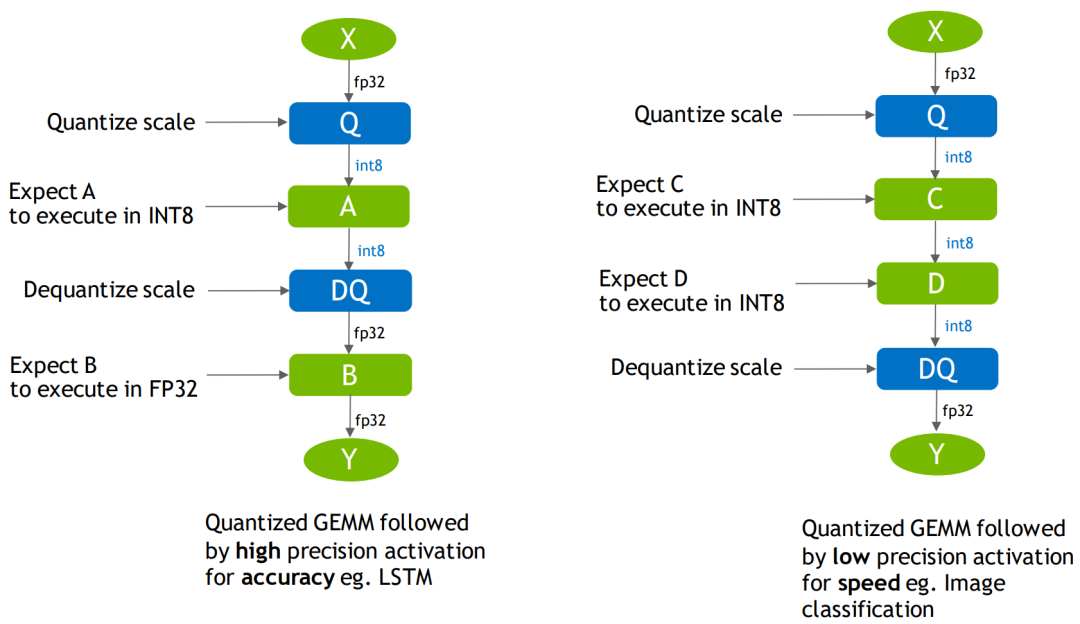
QDQ决定量化细节
显式插入QDQ,告诉TensorRT哪此层Int8,哪些层可以Fuse
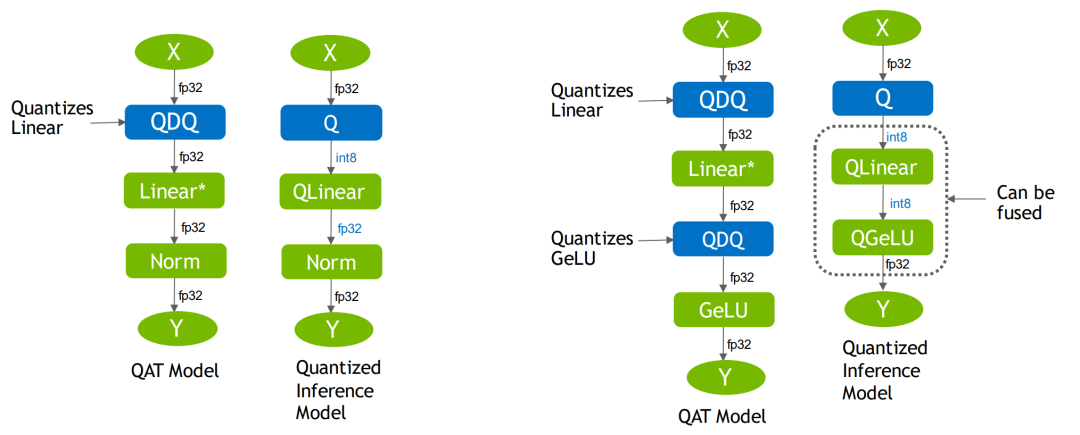
经过融合优化后,最终生成量化版的Engine
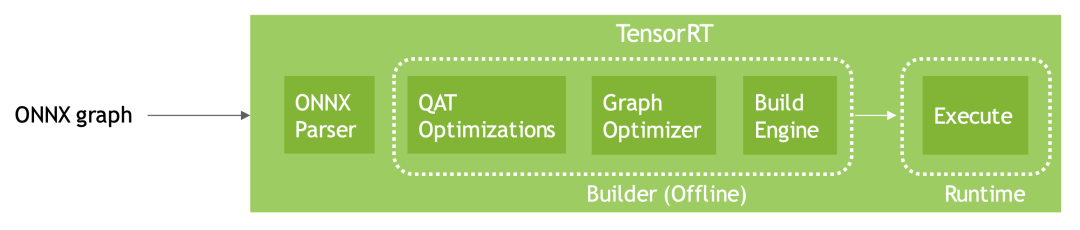
TensorRT加载QAT的ONNX模型并优化的整体流程:
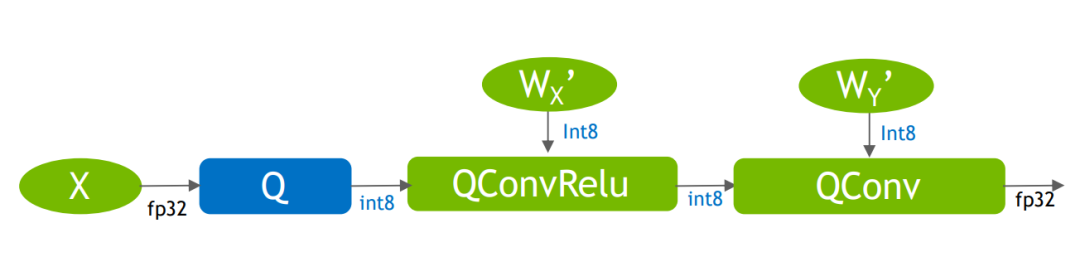
TensorRT显式量化算子:IQuantizeLayer,IDequantizeLayer,即Q和DQ,在构建TensorRT网络时可以通过这两个op来控制网络量化细节
IQuantizeLayer:将浮点型Tensor转换为Int8,通过add_quantize API添加:
output= clamp(round(input/scale)+zero_point) clamp范围[-128,127]
上述两处TensorRT的Layer和ONNX中quantizeLinear和DequantizeLinear对应,使用onnx2trt时,会被解析成对应算子

3、TensorRT对于QDQ模型的优化策略
当TensorRT检测到有QDQ算子时,会触发显式量化
优化准则:Q算子负责FP32-》INT8,DQ负责INT8-》FP32,被 QDQ包围的算子就是量化算子
a、尽可能将DQ算子推迟,推迟反量化操作
b、尽可能将Q算子提前,提前量化操作

QDQ优化策略:
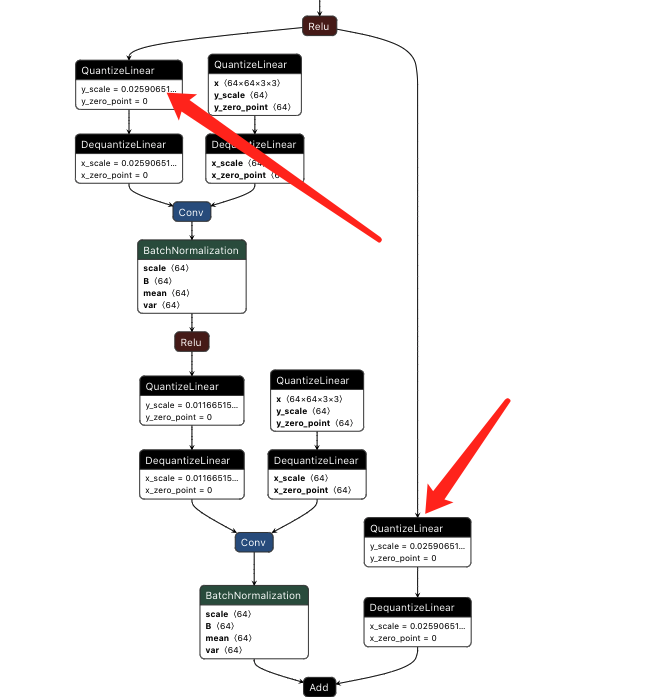
量化所有带权重操作的输入,如卷积,反卷积,GEMM等,如TensorRT会根据QDQ的分布进行不同的优化,比如左边的conv融合后输入INT8但输出为FP32,而右边的输入输出皆为INT8(两者的区别只是因为右面的conv后头跟了一个Q)

默认情况下,不量化带权重操作的输出
激活层,除了RELU,其它激活层比如SILU,不好量化,保持浮点型;比如Sigmoid仅支持FP16;
在训练框架中不要融合BN和RELU
优化网络时会顺手合并CONV+BN+RELU,在导出ONNX模型时无需自己融合;
适当QDQ条件下CONV+BN+ADD融合
象ADD这类操作,最好输入和输出都是INT8,性能才能达到最大化;
一些badcase
大部分情况下,融合QDQ可以带来性能提升,但也有例外:
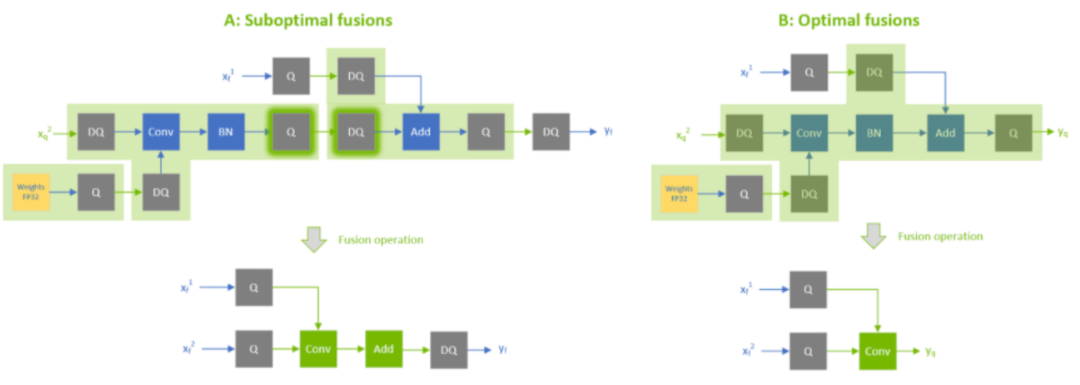
次优融合和最优融合
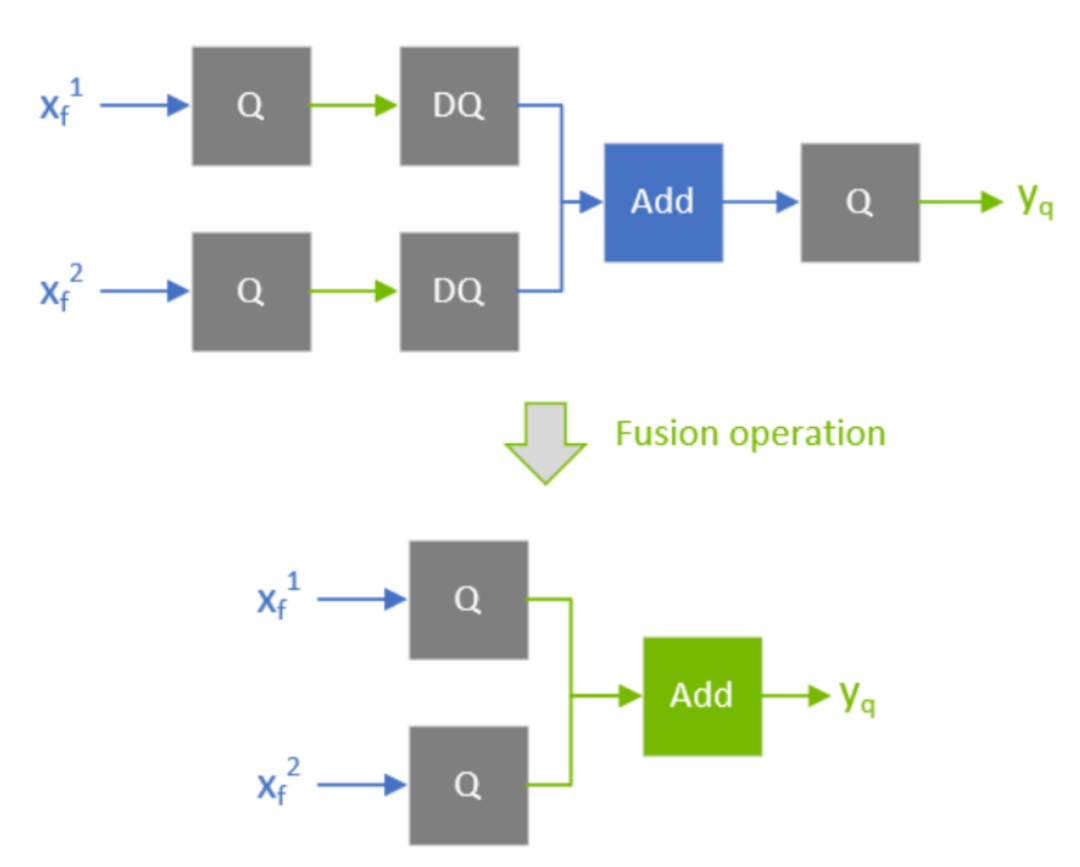
有一些QDQ的优化需要比较其中两个或者多个QDQ算子的scale重新计算scale(比如常见的add或者concat,我们需要对多个输入的scale进行requantize,如果这个trt模型是支持refitted(简单来说就是支持修改模型参数的trt模型),那么我们也是可以修改这些QDQ的scale值的,但修改之后之前重新计算的scale可能就不适用了,这时候该过程就会报错。
比如下图,TensorRT对整个网络进行遍历的时候会比较concat中两个Q的scale是否一致,如果一致的话就可以将concat之后的两个Q放到前面来:
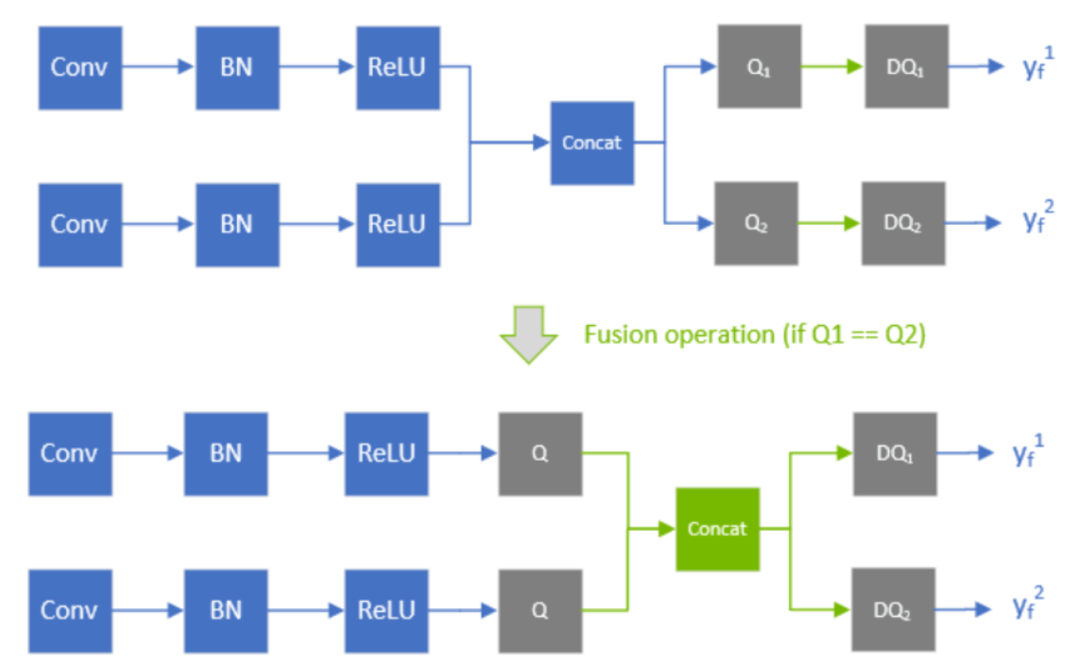
concat融合条件
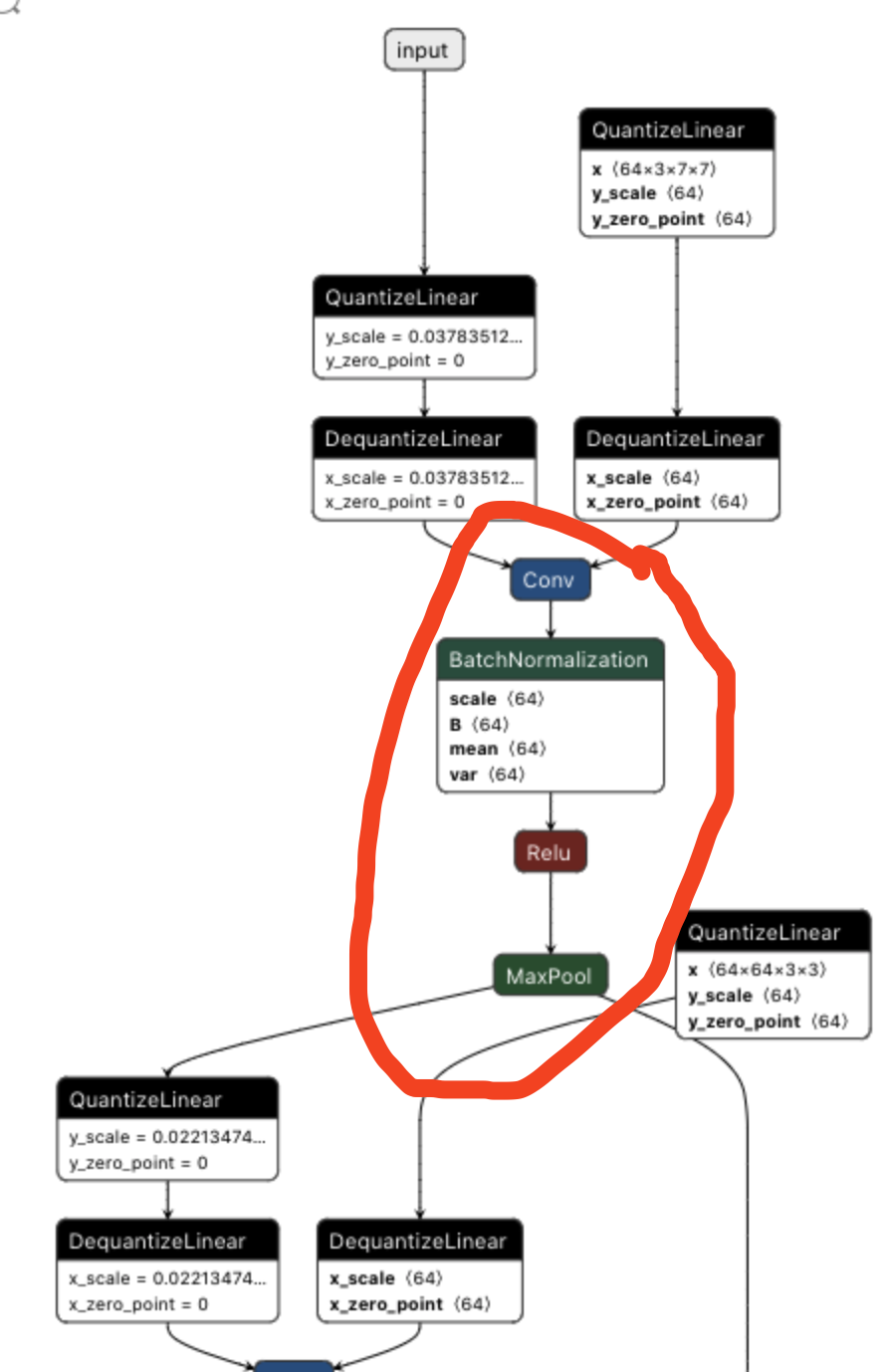
根据以上内容,不难得出,下图红色圈内的OP精度都可以为INT8