

深度学习知识结构梳理(一)
一、基础篇
1. NMS及其变种

NMS:Non-Maximum Suppression(NMS)非极大值抑制,抑制那些非极大值的元素,保留极大值元素,
缺点:1. 需要手动设置阈值,阈值的设置会直接影响重叠目标的检测,太大造成误检,太小达不到理想情况。
2. 低于阈值的直接设置score为0,做法太hard。
3. 只能在CPU上运行,成为影响速度的重要因素。
代码链接参考:https://www.cnblogs.com/jimchen1218/p/17915887.html
改进思路:
1. 根据手动设置阈值的缺陷,通过自适应的方法在目标系数时使用小阈值,目标稠密时使用大阈值。例如Adaptive NMS
2. 将低于阈值的直接置为0的做法太hard,通过将其根据IoU大小来进行惩罚衰减,则变得更加soft。例如Soft NMS,Softer NMS。
3. 只能在CPU上运行,速度太慢的改进思路有三个,一个是设计在GPU上的NMS,如CUDA NMS,一个是设计更快的NMS,如Fast NMS,最后一个是掀桌子,设计一个神经网络来实现NMS,如ConvNMS。
4. IoU的做法存在一定缺陷,改进思路是将目标尺度、距离引进IoU的考虑中。如DIoU。
多类别NMS:某一类的boxes不应该因为它与另一类最大得分boxes的iou值超过阈值而被筛掉;
Adaptive NMS:在目标分布稀疏时使用小阈值,保证尽可能多地去除冗余框,在目标分布密集时采用大阈值,避免漏检; https://zhuanlan.zhihu.com/p/511151467
Soft-NMS:当阈值过小时,如下图所示,绿色框容易被抑制;当过大时,容易造成误检,即抑制效果不明显。
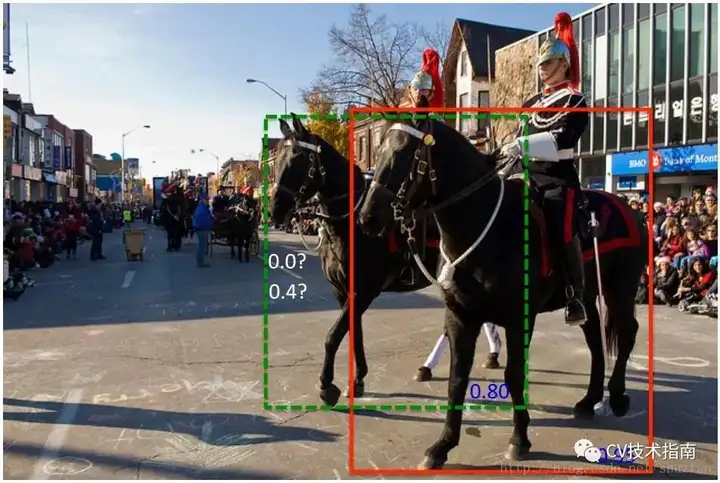
![]() https://arxiv.org/abs/1809.08545
https://arxiv.org/abs/1809.08545
Weight NMS:对坐标进行加权平均 https://link.zhihu.com/?target=https%3A//ieeexplore.ieee.org/document/8026312/

DIOU-NMS:

当IoU相同时,如上图所示,当相邻框的中心点越靠近当前最大得分框的中心点,则可认为其更有可能是冗余框。第一种相比于第三种更不太可能是冗余框。因此,研究者使用所提出的DIoU替代IoU作为NMS的评判准则,公式如下:
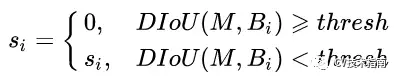
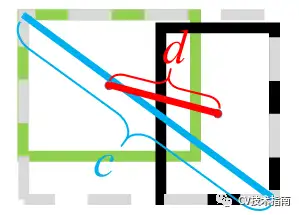
DIoU定义为DIoU=IoU-d²/c²,其中c和d的定义如下图所示
在DIoU实际应用中还引入了参数β,用于控制对距离的惩罚程度。
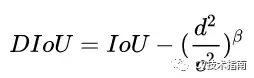
当 β趋向于无穷大时,DIoU退化为IoU,此时的DIoU-NMS与标准NMS效果相当。
当 β趋向于0时,此时几乎所有中心点与得分最大的框的中心点不重合的框都被保留了。
注:除了DIoU外,还有GIoU,CIoU,但这两个都没有用于NMS,而是用于坐标回归函数,DIoU虽然本身也是用于坐标回归,但有用于NMS的。
GIOU NMS
主要思想是引入将两个框的距离。寻找能完全包围两个框的最小框(计算它的面积Ac)。

计算公式如下:
![]()
当两个框完全不相交时,没有抑制的必要。
当两个框存在一个大框完全包围一个小框时或大框与小框有些重合时,GIoU的大小在(-1,1)之间,不太好用来作为NMS的阈值。
其它NMS变种可参考该链接:https://zhuanlan.zhihu.com/p/511151467
2. 损失函数Loss及其变种
损失函数(loss function)是用来估量模型的预测值f(x)与真实值Y的不一致程度,损失函数越小,一般就代表模型的鲁棒性越好
1.分类损失
CTC Loss
BCE Loss:交叉熵loss就是我们熟知的softmax with cross-entropy loss,简称softmax loss,所以说softmax loss只是交叉熵的一个特例。特点就是优化类间的距离非常棒,但是优化类内距离时比较弱。
weighted softmax loss:
两类的样本数目差距非常之大。比如图像任务中的边缘检测问题,它可以看作是一个逐像素的分类问题。此时两类的样本数目差距非常之大,明显边缘像素的重要性是比非边缘像素大的,此时可以针对性的对样本进行加权。

wk就是这个权重,像刚才所说,k=0代表边缘像素,k=1代表非边缘像素,则我们可以令w0=1,w1=0.001,即加大边缘像素的权重。
Focal Loss:减少易分类样本权重,加权log loss的一个变种,
对正负样本进行了分开的表达,f(x)就是属于标签1的概率。
focal loss是针对类别不均衡问题提出的,它可以通过减少易分类样本的权重,使得模型在训练时更专注于难分类的样本,其中就是通过调制系数Y来实现。
对于类别1的样本,当f(x)越大,则调制项因为此时基于该样本是一个容易样本的假设,所以给予其更小的loss贡献权重。通过的Y设置,可以获得自适应地对难易样本进行学习的能力。

2.回归损失
IOU Loss:
L1 Loss:Mean absolute loss(MAE)也被称为L1 Loss,是以绝对误差作为距离:由于L1 loss具有稀疏性,为了惩罚较大的值,常常将其作为正则项添加到其他loss中作为约束。L1 loss的最大问题是梯度在零点不平滑,导致会跳过极小值
L2 Loss:Mean Squared Loss/ Quadratic Loss(MSE loss)也被称为L2 loss,或欧氏距离,它以误差的平方和作为距离:L2 loss也常常作为正则项。当预测值与目标值相差很大时, 梯度容易爆炸,因为梯度里包含了xt。
Smooth Loss:结合了L1和L2 Loss,在x比较小时,上式等价于L2 loss,保持平滑。在x比较大时,上式等价于L1 loss,可以限制数值的大小。
![]()
Huber Loss:对于离群点非常的有效,它同时结合了L1与L2的优点,不过多出来了一个delta参数需要进行训练。
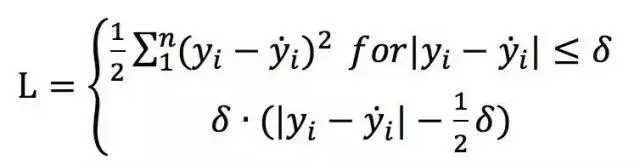
其它损失函数可参考:https://zhuanlan.zhihu.com/p/34044634?utm_id=0
3. 激活函数
Sigmoid:
RELU:
Softmax:
Tan:
4. BN、LN、IN、GN
5. 卷积
卷积没有平移不变性
6.池化
a 平均池化:减少过拟合,保持池化前后梯度之和不变,同时可保留背景信息
b最大池化:可提取特征纹理,减少无用信息影响,反向时需用(需记录池化时最大像素值)
c全局池化:获得全局上下文关系,以特征图为单位进行均值化
建议:前几层用最大池化,最后几层用平均池化
7.优化算法
Adam:
SGD:
Momentum
Adagrad
二、提高篇
1.欠拟合方法:
a增加特征项;b减少正则化参数;c增加模型复杂度;d增加训练次数
2.正负样本平衡:
过采样少样本类
欠采样多样本类
合成新的少样本类
3.训练不收敛
没有数据归一化
没有数据预处理
没有正则化
BS太大
学习率设置不合理
最后一层激活函数错误
网络存在坏梯度,如Relu梯度为0
参数初始化错误
网络设计不合理,太浅或太深
数据标签有问题
隐藏层神经元有问题
4.较小卷积核的好处
相同感受野下提升网络深度,有一定效果
显著减少参数量
5.数据标准化意义
去纲量,控制在相同尺度,加速训练收敛
消除过曝图片,质量不佳对权重影响
6.如何解决梯度消失
使用ReLu,ELU等激活函数
批规范化
消除W带来的放大或缩小影响
三、进阶篇
1.小目标难检测原因?a下采样后特征图上像素少;b小目标数量少;c学习时易被大目标主导;
解决方法:a数据增强,放大图片;b特征融合;c合适的训练方法;d设置更小更稠密anchor;e利用GAN放大物体;f密集遮挡时IouLoss;g匹配策略,对于小目标不设置过于严格的阈值
2.场景问题


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· 因为Apifox不支持离线,我果断选择了Apipost!
2019-12-19 目标检测后处理之NMS(非极大值抑制算法)