ROIAlign
1.线性插值:
已知数据 (x0, y0) 与 (x1, y1),要计算 [x0, x1] 区间内某一位置 x 在直线上的y,使用如下公式:
公式1:(y-y0)/(x-x0) = (y1-y0)/(x1-x0)
公式2:y=(x1-x)/(x1-x0)*y0+(x-x0)/(x1-x0)*y1
就是用x和x0,x1的距离作为一个权重,用于y0和y1的加权。
2.双线性插值:
本质上就是在两个方向上做线性插值。有两个变量的插值函数的线性插值扩展,其核心思想是在两个方向分别进行线性插值。
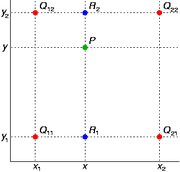
假如我们想得到未知函数 f 在点 P = (x, y) 的值,假设我们已知函数 f 在 Q11 = (x1, y1)、Q12 = (x1, y2), Q21 = (x2, y1) 以及 Q22 = (x2, y2) 四个点的值。最常见的情况,f就是一个像素点的像素值。首先在 x 方向进行两次线性插值,得到
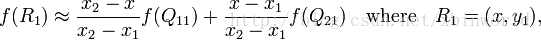
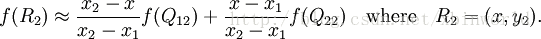
然后在 y 方向进行线性插值,得到
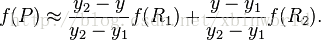
综合起来就是双线性插值最后的结果:
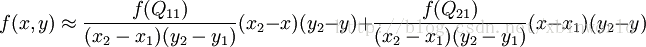
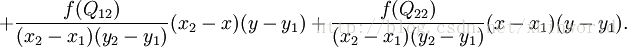
由于图像双线性插值只用到相邻的4个点,因此上述公式分母都是1.
优化方法:
1) 用整数计算代替float,同乘2048就变11位小数为整数,相当于右移22位。
2)源图与目标图像同何中心对齐
scrX=(dstX+0.5)*(srcWidth/dstWidth)-0.5
scrY=(dstY+0.5)*(srcHeight/dstHeight)-0.5
3) 图像原点设为左上角。
3.ROIPooling
在常见的两级检测框架(比如Fast-RCNN,Faster-RCNN,RFCN)中,ROI Pooling 的作用是根据预选框的位置坐标在特征图中将相应区域池化为固定尺寸的特征图,以便进行后续的分类和包围框回归操作。
由于预选框的位置通常是由模型回归得到的,一般来讲是浮点数,而池化后的特征图要求尺寸固定。故ROI Pooling这一操作存在两次量化的过程。
- 将候选框边界量化为整数点坐标值。
- 将量化后的边界区域平均分割成 k x k 个单元(bin),对每一个单元的边界进行量化。
经过上述两次量化,此时的候选框已经和最开始回归出来的位置有一定的偏差,这个偏差会影响检测或者分割的准确度。
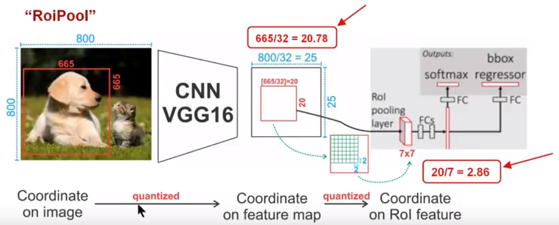
以下是一个Faster-RCNN检测框架。输入一张800*800的图片,图片上有一个665*665的包围框(框着一只狗)。图片经过主干网络提取特征后,特征图缩放步长(stride)为32。因此,图像和包围框的边长都是输入时的1/32。800正好可以被32整除变为25。但665除以32以后得到20.78,带有小数,于是ROI Pooling 直接将它量化成20。接下来需要把框内的特征池化7*7的大小,因此将上述包围框平均分割成7*7个矩形区域。显然,每个矩形区域的边长为2.86,又含有小数。于是ROI Pooling 再次把它量化到2。经过这两次量化,候选区域已经出现了较明显的偏差(如图中绿色部分所示)。更重要的是,该层特征图上0.1个像素的偏差,缩放到原图就是3.2个像素。那么0.8的偏差,在原图上就是接近30个像素点的差别,这一差别不容小觑。
累加操作计算F上离散的特征值,做的最近邻采样操作.
4.ROIAlign
为了解决ROI Pooling的上述缺点,作者提出了ROI Align,取消量化操作,使用双线性内插的方法获得坐标为浮点数的像素点上的图像数值,从而将整个特征聚集过程转化为一个连续的操作.
- 遍历每一个候选区域,保持浮点数边界不做量化。
- 将候选区域分割成k x k个单元,每个单元的边界也不做量化。
- 在每个单元中计算固定四个坐标位置,用双线性内插的方法计算出这四个位置的值,然后进行最大池化操作。
补充说明下:这个固定位置是指在每一个矩形单元(bin)中按照固定规则确定的位置。比如,如果采样点数是1,那么就是这个单元的中心点。如果采样点数是4,那么就是把这个单元平均分割成四个小方块以后它们分别的中心点。显然这些采样点的坐标通常是浮点数,所以需要使用插值的方法得到它的像素值。在相关实验中,作者发现将采样点设为4会获得最佳性能,甚至直接设为1在性能上也相差无几。事实上,ROI Align 在遍历取样点的数量上没有ROIPooling那么多,但却可以获得更好的性能,这主要归功于解决了misalignment的问题。值得一提的是,我在实验时发现,ROI Align在VOC2007数据集上的提升效果并不如在COCO上明显。经过分析,造成这种区别的原因是COCO上小目标的数量更多,而小目标受misalignment问题的影响更大(比如,同样是0.5个像素点的偏差,对于较大的目标而言显得微不足道,但是对于小目标,误差的影响就要高很多)

下图为ROI插值方法示例:

反向传播:
1)ROIPooling:
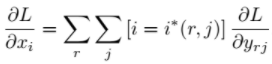
其中,xi代表池化前特征图上的像素点;yrj代表池化后的第r个候选区域的第j个点;i*(r,j)代表点yrj像素值的来源(最大池化的时候选出的最大像素值所在点的坐标)。由上式可以看出,只有当池化后某一个点的像素值在池化过程中采用了当前点Xi的像素值(即满足i=i*(r,j)),才在xi处回传梯度。
2)ROIAlign:
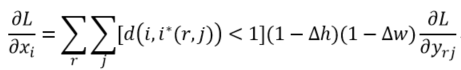
xi*(r,j)是一个浮点数的坐标位置(前向传播时计算出来的采样点),在池化前的特征图中,每一个与 xi*(r,j) 横纵坐标均小于1的点都应该接受与此对应的点yrj回传的梯度,d(.)表示两点之间的距离,Δh和Δw表示 xi 与 xi*(r,j) 横纵坐标的差值,这里作为双线性内插的系数乘在原始的梯度上.
3) ROIAlign


参照caffe2的RoIAlign官方代码学习下,看看的头文件pytorch/caffe2/operators/roi_align_op.h: // Copyright 2004-present Facebook. All Rights Reserved. #ifndef ROI_ALIGN_OP_H_ #define ROI_ALIGN_OP_H_ #include "caffe2/core/context.h" #include "caffe2/core/logging.h" #include "caffe2/core/operator.h" namespace caffe2 { template <typename T, class Context> class RoIAlignOp final : public Operator<Context> { public: RoIAlignOp(const OperatorDef& operator_def, Workspace* ws) : Operator<Context>(operator_def, ws), order_(StringToStorageOrder(this->template GetSingleArgument<string>("order", "NCHW"))), spatial_scale_(this->template GetSingleArgument<float>("spatial_scale", 1.)), pooled_height_(this->template GetSingleArgument<int>("pooled_h", 1)), pooled_width_(this->template GetSingleArgument<int>("pooled_w", 1)), sampling_ratio_(this->template GetSingleArgument<int>("sampling_ratio", -1)) { DCHECK_GT(spatial_scale_, 0); DCHECK_GT(pooled_height_, 0); DCHECK_GT(pooled_width_, 0); DCHECK_GE(sampling_ratio_, 0); DCHECK(order_ == StorageOrder::NCHW || order_ == StorageOrder::NHWC); } USE_OPERATOR_CONTEXT_FUNCTIONS; bool RunOnDevice() override { CAFFE_NOT_IMPLEMENTED; } protected: StorageOrder order_; // 数据存储格式 float spatial_scale_; // 采样stride,如 1 / 16; int pooled_height_; // RoIAlign后的grid数,如6 x 6 grid int pooled_width_; // RoIAlign后的grid数,如6 x 6 grid int sampling_ratio_; // 每个bin内高和宽方向的采样率,论文中默认是2,即每个bin采样2*2=4个点 }; } // namespace caffe2 #endif // ROI_ALIGN_OP_H_

 浙公网安备 33010602011771号
浙公网安备 33010602011771号