如何入门Pytorch之三:如何优化神经网络
在上一节中,我们介绍了如何使用Pytorch来搭建一个经典的分类神经网络。
一般情况下,搭建完模型后不会训练一次就能达到比较好的效果,这样,就需要不断的调整和优化模型的各个部分。从而引出了本文的主旨:如何优化模型。
在本节中,我们将介绍从数据集到模型各个部分的调整,从而可以有一个完整的解决思路。
1、数据集部分
1.1 数据集划分
一般情况下,我们会把数据集分成三个部分:训练集,验证集和测试集。依据数据集的大小,如果数据集比较大,数万或数十万个,可以将数据集采用7:2:1或8:1:1的比例来划分。而如果数据集比较小,只有几百条,就不能简单的使用这个方法了。这时,需要使用K折验证法(具体方法可自行百度)。
当然,还有一些需要考虑的问题:数据表征,时间敏感性和数据冗余。在数据表征中,随机打乱(shuffle)是一个不错的选择;时间敏感性主要是针对回归问题象预测股票,不同的月份对回归结果有一个不同的贡献;数据冗余指的是,在数据集中,存在着一些相同的数据会对训练和测试结果产生影响,所以,需要事先过滤掉。
1.2数据预处理
数据向量化:数据源形式各异,需要提前把它转换成框架可以识别的形式,Pytorch统一使用向量(Vector)来表示数据。
正则化:数据的范围大小不一,如果直接使用,训练的收敛会很慢,甚至会出现异常。所以,需要统一数据的范围大小,也就是去除纲量,使用【0,1】区间来统一度量。
缺失数据的处理:如果没有对缺失数据进行处理,训练过程中会直接导致数据的权重分配异常,进而直接影响训练效果。
特征工程:对数据集的特征进行有效提取,是保证模型正常训练的前提。
1.3过拟合与欠拟合
过拟合:训练效果好而验证效果不好。
欠拟合:训练效果不好。
欠拟合的处理相对容易些,针对欠拟合,我们一般采用加大训练周期,降低训练损失,提高训练精度。
过拟合策略:
1、获取更多数据
2、减小网络规模
原始模型: class Architecture1(nn.Module): def __init__(self, input_size, hidden_size, num_classes): super(Architecture1, self).__init__() self.fc1 = nn.Linear(input_size, hidden_size) self.relu = nn.ReLU() self.fc2 = nn.Linear(hidden_size, num_classes) self.relu = nn.ReLU() self.fc3 = nn.Linear(hidden_size, num_classes) def forward(self, x): out = self.fc1(x) out = self.relu(out) out = self.fc2(out) out = self.relu(out) out = self.fc3(out) return out
减小规模后的模型: class Architecture2(nn.Module): def __init__(self, input_size, hidden_size, num_classes): super(Architecture2, self).__init__() self.fc1 = nn.Linear(input_size, hidden_size) self.relu = nn.ReLU() self.fc2 = nn.Linear(hidden_size, num_classes) def forward(self, x): out = self.fc1(x) out = self.relu(out) out = self.fc2(out) return out
3、使用权重正则化
正则化分为1阶正则化和2阶正则化
1阶正则化是将权重协相关系数的相差绝对值加入权重。
2阶正则化是将权重协相关系数的相差平方和加入权重。示例如下:
model = Architecture1(10,20,2)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4, weight_decay=1e-5)
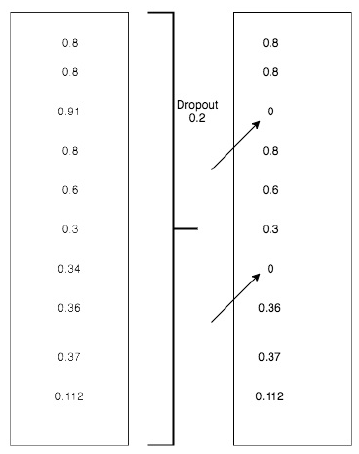
4、使用DROPOUT
在隐藏层中去除某些节点,以达到防止过拟合的问题。
dropout的比率为0.2:
dropout的比率为0.5

nn.dropout(x, training=True)
1.4问题定义与数据集获取
首先需要明确两个事情:问题的类别与数据的输入,确定是分类问题还是回归问题。
不同类别的问题有着不同的处理方法,对数据集的获取也是必须面对的一大难题。
1.5模型评估
对于分类问题,一般采用精度,ROC,AUC等方法来进行评估;
而对于排名问题,一般采用mAp;
2、模型部分
2.1 搭建完基础模型后,为了使该模型能够正常工作,我们需要做以下三部分工作:
1、选择网络输出的最后一层
不同的任务,输出最后一层也不尽相同。一般的回归问题只要输出一个标量就可以;向量回归问题则需要输出相同层的向量;对于BBOX问题,则需要输出四个值;对于二分类,我们需要使用Sigmoid,对于多分类则使用softmax。
2、选择损失函数
对于分类问题,一般采用交叉熵损失;而对于回归问题,则采用均方差。
3、优化器
如何选择一个优化器及配置相关参数是一件非常有艺术性的事。有时需要通过实验来得到。很多时候:Adam和RMSProp是个不错的选择。
Problem type Activation function Loss function Binary classification Sigmoid activation nn.CrossEntropyLoss() Multi-class classification Softmax activation nn.CrossEntropyLoss() Multi-label classification Sigmoid activation nn.CrossEntropyLoss() Regression None MSE Vector regression None MSE
2.2 提高模型规模
对于一个已搭建好的模型,如何提高模型的推理能力。可以从这三方面来提高:
1、增加更多的层
2、加入更多的权重系数
3、提高训练周期
2.3 加入泛化策略
1、加入dropout
2、使用不同的架构,不同的参数,不同的网络层数,权重。
3、使用L1或L2正则化
4、尝试不同的学习率
5、增加更多的数据或特征
2.4学习率的设置
学习率对于模型来说,是一个非常重要的超参数。它的设置很多时候直接决定着模型训练效果的好坏。所以,如何设置该参数就变得非常重要。有大量的研究就是针对于该参数进行的。
在Pytorch中,有一系列的方法:
1、stepLR:
scheduler = StepLR(optimizer, step_size=30, gamma=0.1) #step_size:多少个周期后学习率发生改变 gamma:学习率如何改变 for epoch in range(100): scheduler.step() train(...) validate(...)
2、MultiStepLR
scheduler = MultiStepLR(optimizer, milestones=[30,80], gamma=0.1)
#milestones:多少个周期后学习率发生改变 gamma:学习率如何改变
for epoch in range(100): scheduler.step() train(...) validate(...)
3、ExponentialLR
4、ReduceLROnPlateau
optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9) scheduler = ReduceLROnPlateau(optimizer, 'min') for epoch in range(10): train(...) val_loss = validate(...) # Note that step should be called after validate() scheduler.step(val_loss)
上一篇:
下一篇:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号