语义分割之RefineNet
背景介绍
近来年,深度卷积网络在目标检测方面取得了一定的成绩。但对于密集预测,仍存在一定不足,原因是频繁的卷积和池化导致最终的特征分辨率降低。
针对这个问题,目前主要采用两种方法:第一种:空洞卷积,如Deeplab,但计算资源消耗太大;下图分别是残差结构和空洞卷积在提取稠密分割结果时的操作流程:

很明显,残差结构直接损失了空间分辨率。虽然空洞卷积在一定程度上减小了残差结构空间分辨率的损失,但是其训练的代价是非常高昂的(即使在GPU上)。
一、创新点:
1、提出一种新的模块:RefineNet,利用不同层的特征来完成语义分割。主要利用了递归的方式。
2、提出了链式残差池化的思想,可以在较大的图像区域上捕获背景信息。
二、详细功能介绍:
1、多路径Refine恢复分辨率
实现将粗糙的较高层次语义特征与精细的较低层次语义特征结合,来生成高分辨率的语义分割图片;

基于ResNet网络,在4种不同的降采样阶段,将特征图输入到RefineNet模块中,产生整合后的特征图。除了RefineNet4,每个RefineNet模块都有两个输入,一个是本阶段的特征图,另一个是低层产生的经过处理的特征图。随着降采样的进行,语义信息逐渐丰富。最终得到的得分图,经过上采样恢复到原有的图片大小。
2、RefineNet模块(全局特征提取与融合)
每个RefineNet模块结构如下:
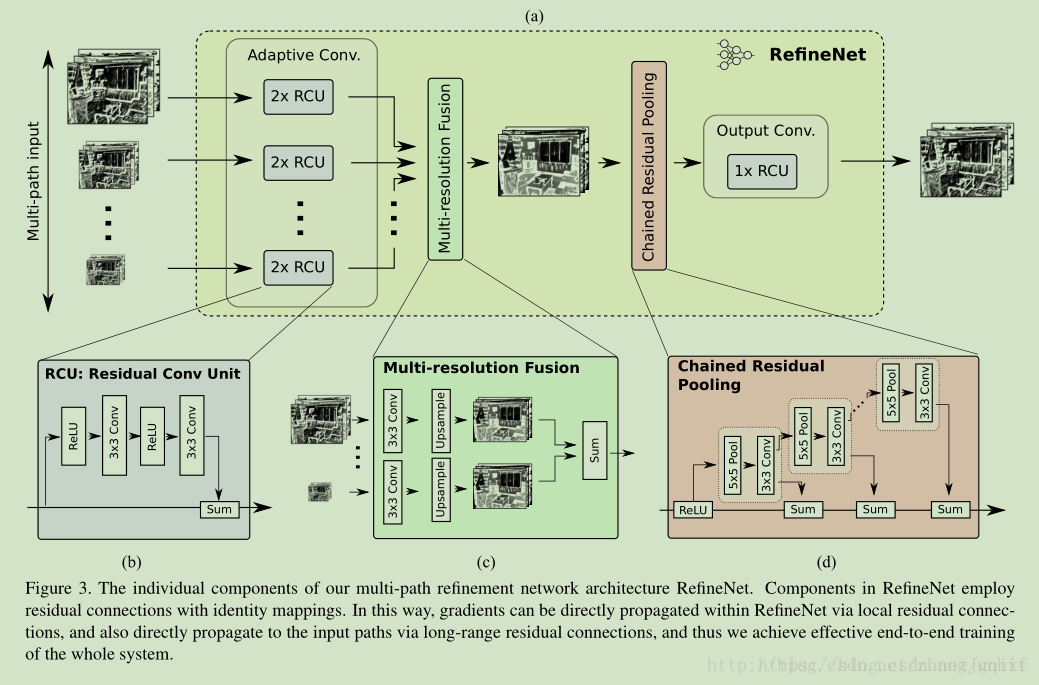
主要由4部分组成:
1)残差卷积单元RCU,用来调整预训练权重;

每个RCU模块包括一个ReLU层和一个卷积层,网络结构中,每个分辨率下应用两个串联的RCU模块,用于提取该分辨率下的分割结果的残差,最后以相加的形式校正该分辨率下的原始分割结果。
2)多分辨率融合单元,实现不同分辨率特征图的融合;

首先通过一个卷积层处理输入进来的不同分辨率下的分割结果,从而学习得到各通道下的适应性权重。随后,应用上采样,统一所有通道下的分割结果,并将各通道结果求和。求和结果送入下一个模块。
3)链式残差池化,用来捕获背景上下文信息;

通过残差校正的方式,优化前两步融合得到的分割结果。
该模块主要由一个残差结构、一个池化层和一个卷积层组成。其中,池化层加卷积层用来习得用于校正的残差。值得注意的是,RefineNet在这里用了一个比较巧妙的做法:用前一级的残差结果作为下一级的残差学习模块的输入,而非直接从校正后的分割结果上再重新习得一个独立的残差。好处是:可以使得后面的模块在前面残差的基础上,继续深入学习,得到一个更好的残差校正结果。
4)输出卷积单元,用于处理结果的最终预测。
3、恒等映射
方便进行端到端的处理。
三、详细架构图:

四、RefineNet不同变种结构:
1、单个RefineNet

2、二次级联的RefineNet

3、四次级联RefineNet

五、实验结果:
RefineNet在NYUv2数据库、PASCAL VOC 2012数据库和Cityscapes数据库下都有实验验证。下表是其在NYUv2下的结果(40类):
NYU数据集下载链接:https://cs.nyu.edu/~silberman/datasets/nyu_depth_v2.html
预处理链接:http://www.manongjc.com/article/26507.html

下表是其在Cityscapes下的结果:
CityScapes数据集下载链接:https://www.cityscapes-dataset.com/

下图是语义分割问题上的直观结果:

除了语义分割,RefineNet还可以用于目标理解(object parsing)。下表是其在目标理解上的表现:

下图是RefineNet在目标理解上的直观结果:

注:该方法可进行端到端的训练,且在不同的训练集上表现都不错。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号