容器监控解决方案对比
容器监控解决方案对比
容器监控解决方案有很多,有些开源有些商用。本文主要从high-level对比几款容器监控的解决方案,希望能够在选择解决方案时缩小范围。
本文非原创,主要翻译自Comparing 10 Container Monitoring Solutions for Rancher
容器监控解决方案对比
本文分析的容器监控解决方案包括:
能力对比
我们选取了监控解决方案共有的从几个方面能力进行对比,抽象为7个层次:
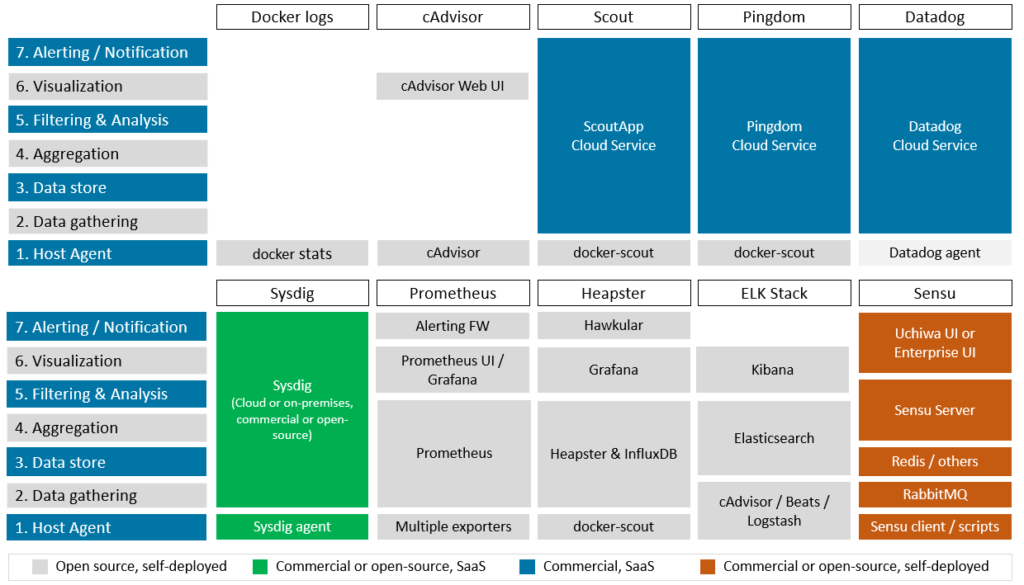
- Host Agent - 单个host上的指标数据收集。Agent部署在host上(通常以容器运行),并通过API或日志文件采集指标时序数据。
- Data gathering framework - 汇总所有host上的指标数据保存到一个共享的存储节点的机制。
- Datastore - 指标数据的存储可能是传统的数据库,或者专为时序数据存储的分布式时序数据库。有些方案使用本地存储,而有些则使用可插入的开源时序数据库。
- Aggregation engine - 聚和引擎主要提供指标数据的聚和查询功能,包括纵向聚和(如多个host上同一个指标的聚和)和时间聚和(聚和成1小时、1天等)。
- Filtering & Analysis - 过滤和分析功能差异较大,有些解决方案提供了可自定义的仪表板,嵌入式查询语言和复杂的分析功能。
- Visualization tier - 监视工具通常具有可视化Web界面用于交互以生成图表、定制查询、甚至定义警报条件。可视化层通常与过滤和分析功能紧密耦合。
- Alerting & Notification - 监控系统的另一个共同特征是警报子系统,如果满足或超过预定义的阈值,该子系统可以提供通知。
如下图显示了我们的10个监控解决方案的能力对比视图,哪些组件实现了每个层次的功能以及组件所在的位置:
其他方面的对比
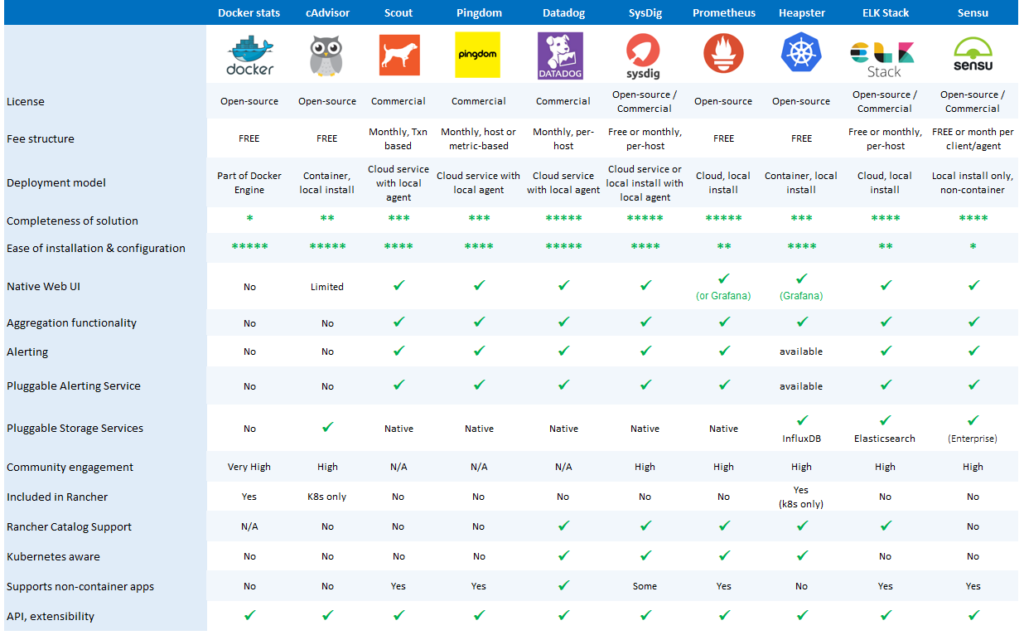
除了基本能力之外,我们通常还关心监控系统方案如下图所示的其他方面:
容器监控解决方案简介
Docker Stats
Docker提供了内建的docker stats命令用于获取docker hosts的监控信息。管理员可以通过该命令查询获取详细和实时的容器资源消耗指标信息,包括CPU、内存的使用率,磁盘和网络I/O,以及运行的进程个数等。
Docker stats不能获取历史信息,并且只能获取单个host。通常和Docker日志文件和docker events命令一起使用来满足监控服务的需求。因单个host的局限性,docker stats不太适用于Kubernetes和Swarm集群的监控。从监控系统能力上看,docker stats只提供了Host Agent的部分能力。
cAdvisor
cAdvisor是谷歌的开源项目,用于采集和展示容器的资源使用信息。它最初是用于管理谷歌的lmctfy容器,现在已经支持了Docker容器。它被实现为一个守护进程,用于收集,聚合,处理和导出有关正在运行的容器的信息。它可以安装和运行在docker主机上或者docker容器里。
cAdvisor支持Web界面用于生成指标图表,但和docker stats一样,它只能展示一个Docker host上的指标数据。
cAdvisor默认只保留60s的数据,其支持通过外部的存储服务保存时序数据,如Prometheus和InfluxDB。cAdvisor常作为Host Agent用作其他监控系统方案的一部分。
Scout
Scout是一家位于科罗拉多州的公司,提供基于云的应用程序和数据库监控服务,主要针对Ruby和Elixir环境。Scout提供全面的数据收集,过滤和监控功能,灵活的警报和与第三方警报服务的集成。Scout不是开源的,在30天试用之后需要付费才能继续试用。
Scout支持利用其现有的监控和警报框架监控Docker容器,提供了使用Ruby和StatsD编写脚本以获取Docker Stats和Docker event API以及将指标中继到Scout进行监控的方法。
Scout应用作为托管云服务(a hosted cloud service),在快速启动和运行容器监控解决方案时可以省去很多麻烦。如果您正在部署Ruby应用程序或运行Scout支持的数据库环境,那么整合Docker,应用程序和数据库级监视并使用Scout解决方案是个不错的选择。
Pingdom
Pingdom是由德克萨斯州奥斯汀的SolarWinds运营的托管云服务,该公司专注于监控IT基础架构。虽然Pingdom的主要用例是网站监控,但作为其服务器监控平台的一部分,Pingdom提供了大约90个插件。其实Pingdom维护着docker-scout,与Scout使用的StatsD agent相同。当然它也是商用的,其定价非常灵活,用户客户以选择基于服务器的方案或者基于StatsD指标数量的方案。
对于需要易于设置和管理的全栈监控解决方案以及希望监控容器管理平台之外的其他服务的用户而言,Pingdom也是个不错的选择。
Datadog
Datadog和Scout、Pingdom一样也是一个商用的托管云服务监控解决方案。Datadog还提供了一个Agent可以部署在Docker主机上,并开发了一个StatsD的增强版DogStatsD。Datadog Agent收集并转发Docker API提供的全套指标,并提供更详细,更精细的监控。与其他服务一样,Datadog也可用于监控其他服务和应用程序,它拥有一个包含200多个集成的库。
Datadog优于其他一些云服务的一个优点是它具有Docker之外的集成,可以从Kubernetes,Mesos等等收集指标。Datadog-Kubernetes监控解决方案使用Kubernetes中的DaemonSets自动将数据收集Agent部署到每个集群节点。
Sysdig
Sysdig是一家加利福尼亚州的公司,提供基于云的监控解决方案。与目前为止描述的一些基于云的监控解决方案不同,Sysdig更侧重于监控容器环境,包括Docker,Swarm,Mesos和Kubernetes。Sysdig在其开源项目中提供了部分的功能,并可以选择在云或者本地进行部署。商用Sysdig Monitor监控,警报和故障排除功能,包括Docker,Kubernetes,Mesos和Swarm-aware。
Prometheus
Prometheus是最初由SoundCloud创建的一种流行的开源监控和警报工具包。它现在是一个CNCF项目(并且已经毕业),这是该公司继Kubernetes之后的第二个托管项目。和其他解决方案不同,Prometheus是一种模块化的自托管方式,而不是作为云服务提供。因此可以用户可以在其集群上部署Prometheus,无论是内部部署还是云驻留。
Prometheus不是将数据推送到云服务,而是通过HTTP向安装在每个Docker主机上的exporters“抓取”数据。一些exporters作为Prometheus GitHub项目的一部分正式维护,而其他exporters则是外部贡献。Prometheus服务器从各种源获取时间序列数据,并将数据存储在其内部数据存储中。Prometheus提供服务发现,针对特定指标的单独推送网关等功能,并具有擅长查询多维数据的嵌入式查询语言(PromQL)。它还具有嵌入式Web UI和API。 Prometheus中的Web UI提供了良好的功能,但需要用户了解PromQL,因此一些用户更喜欢使用Grafana作为图表和查看指标的界面。
Prometheus有一个独立的告警管理器,具有独特的UI,可以处理存储在Prometheus中的数据。与其他告警管理器一样,它可以与各种外部告警服务配合使用,包括电子邮件,Hipchat,Pagerduty,#Slack,OpsGenie,VictorOps等。
由于Prometheus由许多组件组成,并且需要根据所监控的服务选择和安装exporters,因此安装起来比较困难。虽然不像Datadog或Sysdig这样的工具那么精致,但Prometheus提供类似的功能,广泛的第三方软件集成和一流的云监控解决方案。
Heapster
Heapster是另一种经常与监控容器环境相关的解决方案。 Heapster是Kubernetes旗下的一个项目,有助于实现容器集群监控和性能分析。Heapster专门支持Kubernetes和OpenShift。人们经常将Heapster描述为一种监控解决方案,但它更确切地说是“集群范围内的监控和事件数据聚合器”。Heaps不会单独部署,它是一堆开源组件的一部分。 Heapster监控堆栈通常包括:
- 数据采集层 - 如cAdvisor
- 可插拔存储后端 - 例如ElasticSearch,InfluxDB,Kafka,Graphite等
- 数据可视化组件 - Grafana或Google Cloud Monitoring
ELK Stack
另一个可用于监视容器环境的开源软件栈是ELK,由Elastic提供的三个开源项目组成。ELK堆栈功能多样,广泛用于各种分析应用程序,日志文件监控是关键应用程序。ELK以其关键组件命名:
- Elasticsearch - 一个基于Lucene的分布式搜索引擎
- Logstash - 一个数据处理管道,它接收数据并将其发送到Elasticsearch(或其他“stashes”)
- Kibana - Elasticsearch的可视化搜索仪表板和分析工具
Beats是Elastic堆栈的无名成员,项目开发人员描述其为“轻量级数据托运人”。有各种现成的Beats托运人,包括Filebeat(用于日志文件),Metricbeat(用于收集数据指标)和Heartbeat用于简单的正常运行时间监控等。Metricbeat支持Docker,作者提供了有关如何使用它来提取主机指标和监视Docker容器中的服务的指导。有商业ELK堆栈提供商,如logz.io和Elastic Co本身,它们提供“ELK as a service”,通过告警功能补充堆栈的功能。
虽然可以使用ELK进行容器监控,但与Sysdig,Prometheus或Datadog相比,这是一个更难实施的解决方案。
Sensu
Sensu是一种通用的self-hosted监控解决方案,支持各种监控应用。免费的Sensu Core版本在MIT许可下可用,而具有附加功能的企业版本为50个client每月99刀。Sensu使用术语client来指代其监控agent,因此根据您监控的主机和应用程序环境的数量,企业版可能会变得昂贵。
Sensu在容器管理之外具有令人印象深刻的功能。Sensu插件的数量持续增长,并且有许多Sensu和社区支持的插件允许从各种来源提取指标。插件往往是用Ruby编写的,需要在Docker主机上运行基于gem的安装脚本。 用户可以使用他们选择的语言开发其他插件。 Sensu插件不会部署在自己的容器中,这与我们考虑过的其他监控解决方案一样。不同的用户希望根据他们的监视要求混合和匹配插件,因此为每个插件分配容器将变得难以处理,这可能是未在容器部署的原因。可以使用Chef,Puppet和Ansible等平台部署插件。例如,对于Docker,有六个独立的插件可以从各种来源收集与Docker相关的数据,包括Docker stats, container counts, container health, Docker ps等等。
Sensu使用使用RabbitMQ实现的消息总线来进行Client和Sensu服务器之间的通信。Sensu使用Redis存储数据,但它旨在将数据路由到外部时间序列数据库。支持的数据库包括Graphite,Librato和InfluxDB。安装和配置Sensu需要付出一些努力。 安装Sensu的先决条件是Redis和RabbitMQ,Sensu服务器,Sensu客户端和Sensu仪表板需要单独安装。为方便起见,可以使用运行redis,rabbitmq-server,uchiwa(开源Web层)和Sensu服务器组件的Docker镜像(hiroakis / docker-sensu-server),但这个软件包只能用于测试,而不是生产环境。如果运行Kubernetes,Sensu将不是一个很好的方案,因为其众多插件中并没有支持Kubernetes的。
其他方案
- Graylog - 是另一个在监控Docker时出现的开源解决方案。与ELK一样,Graylog适用于Docker日志文件分析。它可以接受和解析来自多个数据源的日志和事件数据,并支持第三方收集器,如Beats,Fluentd和NXLog。
- Nagios - 通常被认为更适合监控主机集群而不是容器,但对于监控主机集群的人来说,Nagios更受欢迎。
- Netsil - 是一家硅谷初创公司,为Docker,Kubernetes,Mesos以及各种应用程序和云提供商提供监控应用程序。Netsil的应用运营中心(AOC)为云应用服务提供框架感知监控。 与所讨论的其他一些监控框架一样,它以云/ SaaS或自托管方式提供。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号