
sqlserver的like '%xxx%'优化,全文索引
2000万行的数据表,首先对Address字段做'%xxx%'模糊查询
这是估计的查询计划
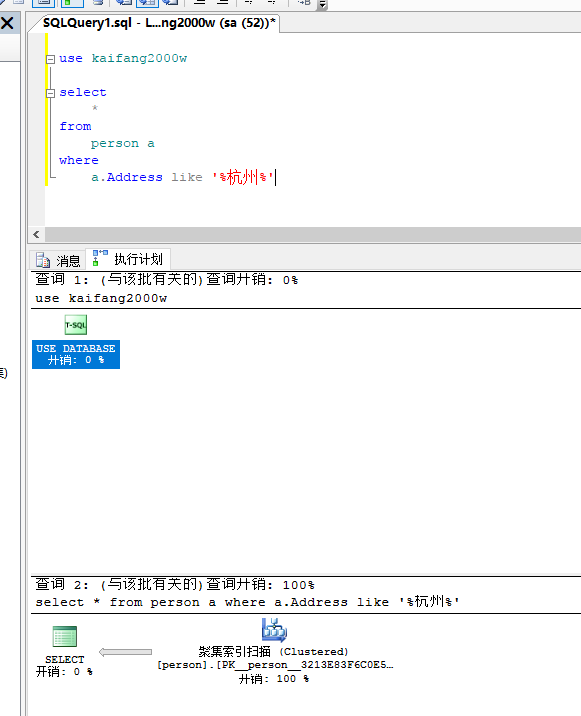
这是估计的实际查询结果,用了37秒才查询完成

还是之前的数据,但是这一次使用'xxx%'来做查询,现在还没有做索引
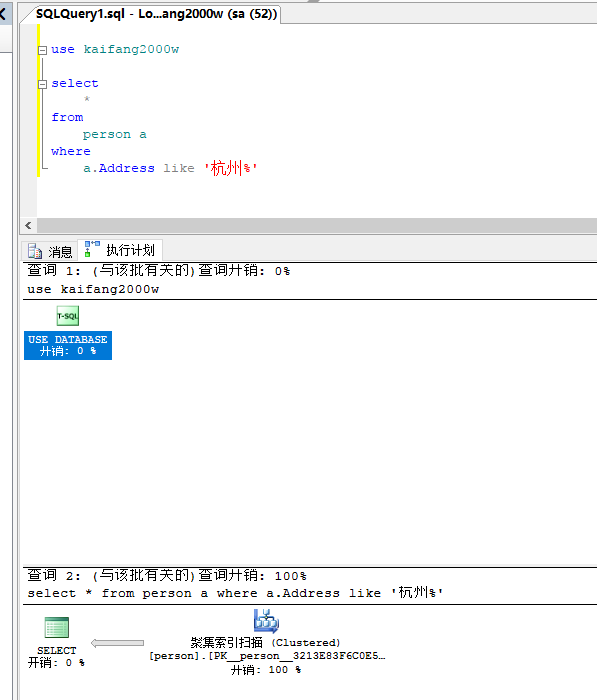
查询速度为10秒,依然是做了全表扫描

接下来的这个不是模糊查询,直接的=,查询多了一个步骤“并行度”
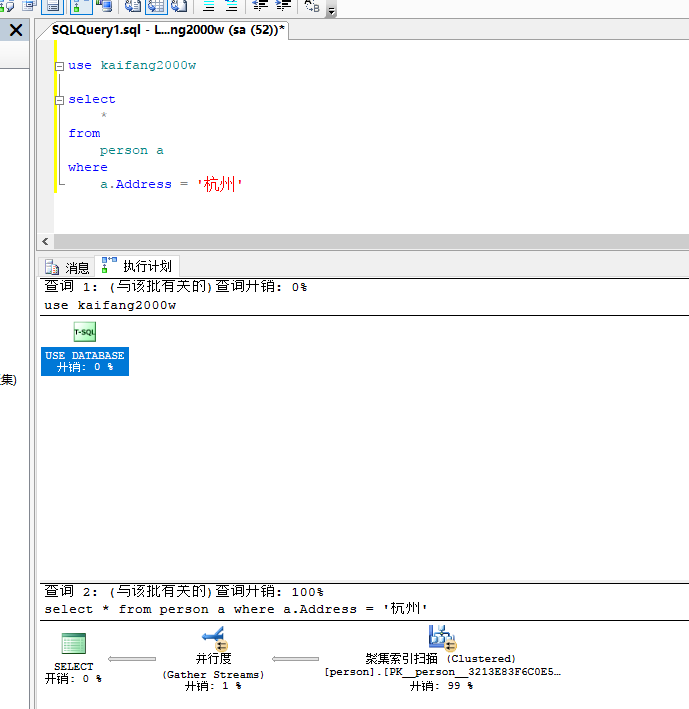
三秒钟完成查询,也是很慢的,应该都是走了全表扫描

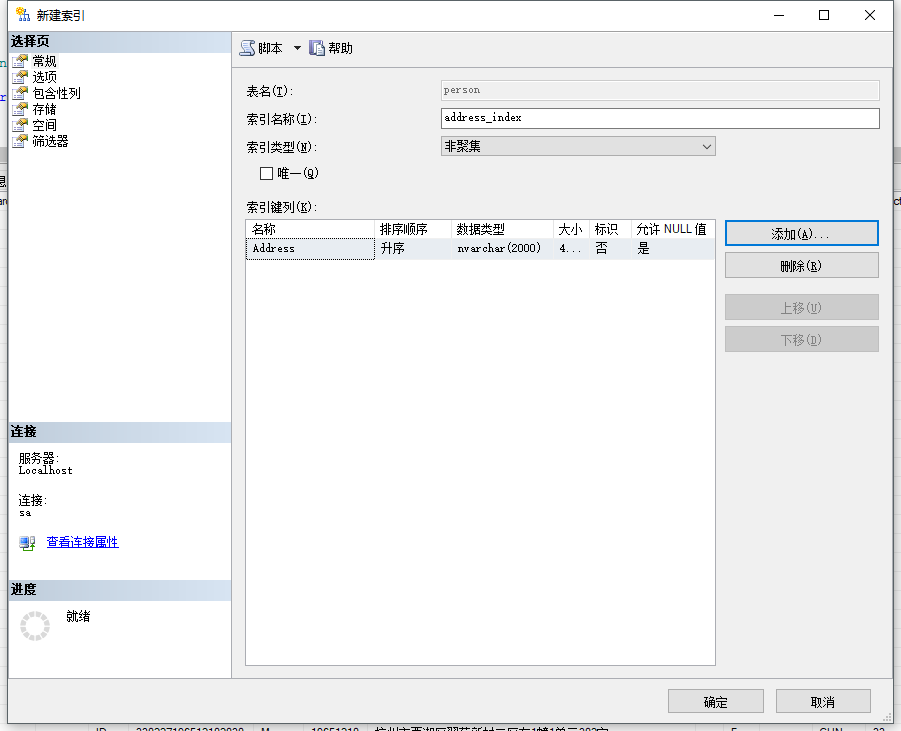
现在为Address字段建立一个普通索引
建好普通索引之后尝试进行'%xxx%'查找,从查询计划来看,'%xxx%'是无法利用到普通索引的
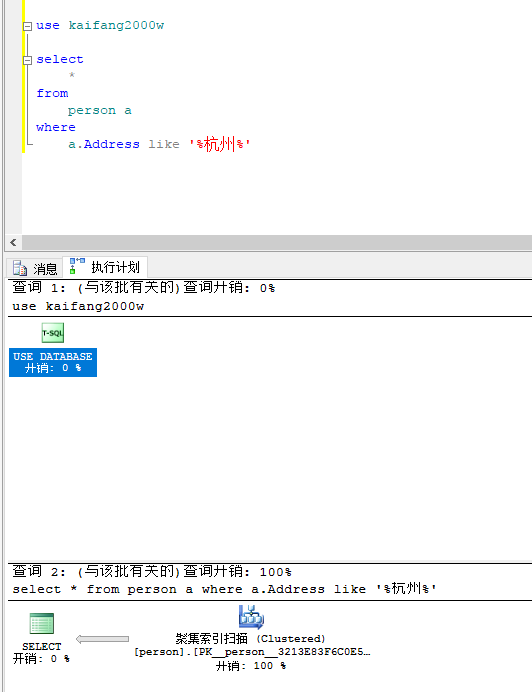
果然,查询耗时和没有建立索引之前一样,基本没变

现在尝试查询'xxx%',根据查询计划可以看到,这种查询可以走刚刚我们建立的普通索引
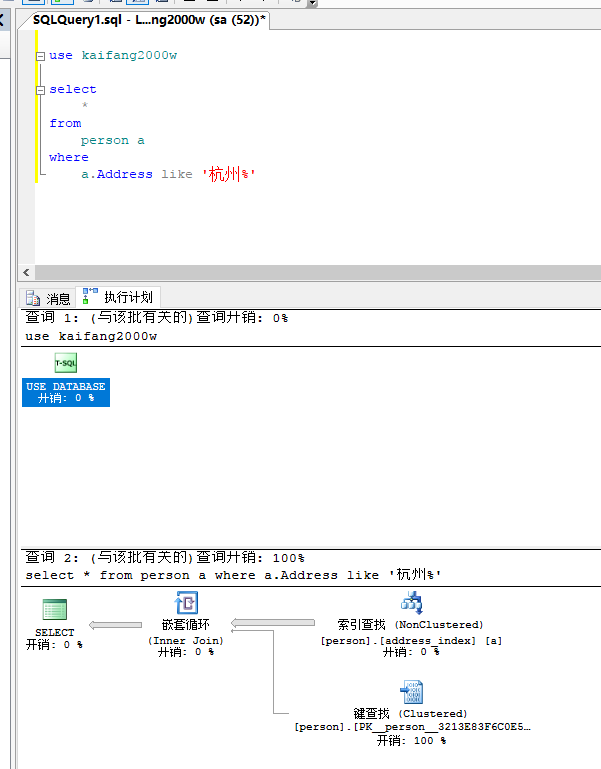
查询结果为4秒,之前没有建立索引的时候查询结果为10秒,缩小了一倍

接着,直接=查找,可以看出利用了索引
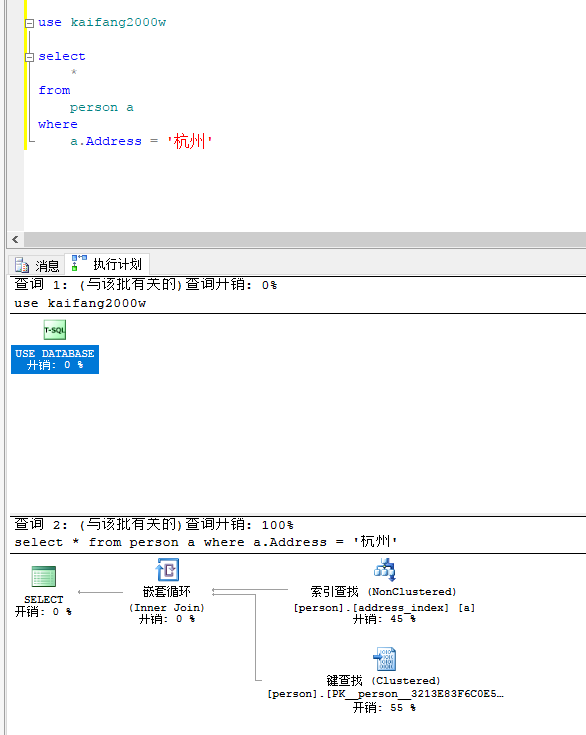
查询耗时0秒,降到了毫秒级别,从这点可以看出,普通的非聚集索引对于直接匹配(=)查询的支持是最好的,然后是like 'xxxx%',而like '%xxx%'不支持

然后我们在Address字段上建立一个全文索引
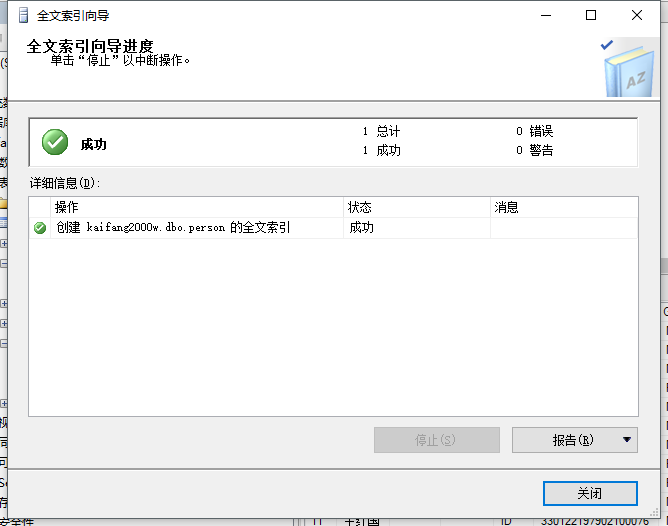
下面是全文索引的使用语法,以及查询过程
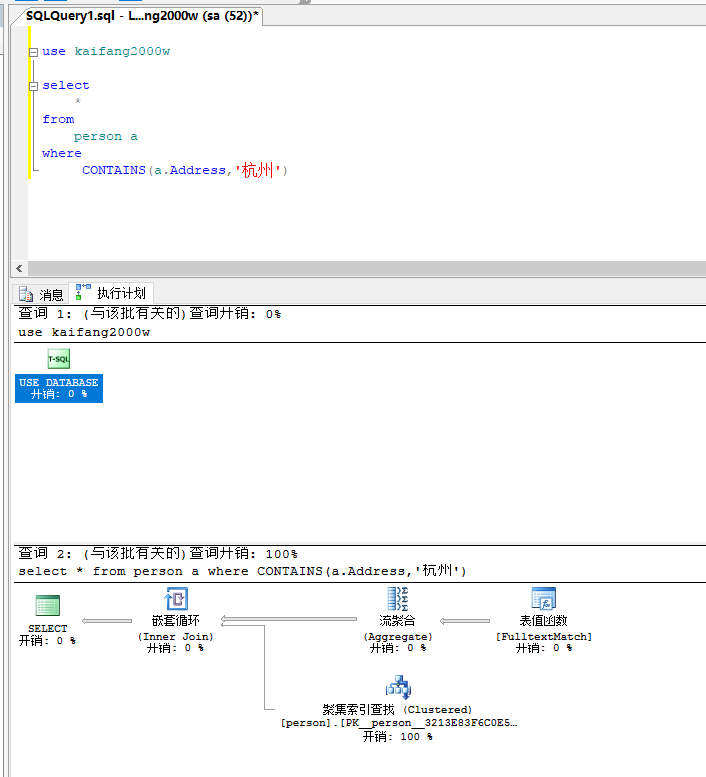
全文索引添加之后,查询时间为2秒,还是有点慢,后来测试了几次,一般是在一秒左右

另外SQLServer2008的全文索引貌似不会立马建立完成,而是需要在后台等待一段时间才能完全建立,在这段时间里面查询返回的结果是不一样的。
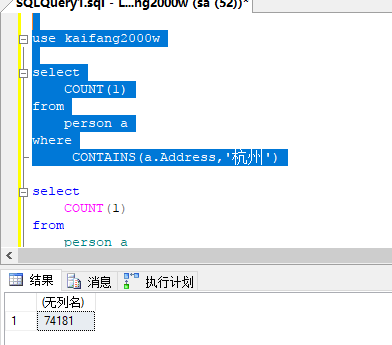
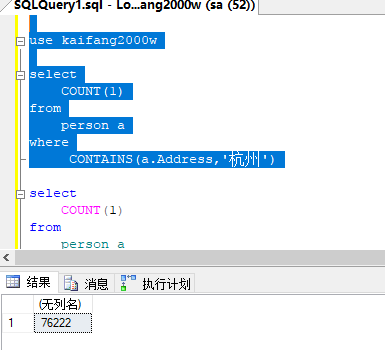
如下图,两次查询后一次的结果比前一次多,全文索引正在建立中,最后会有一个稳定的状态。


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· 没有源码,如何修改代码逻辑?
· 一个奇形怪状的面试题:Bean中的CHM要不要加volatile?
· [.NET]调用本地 Deepseek 模型
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· 微软正式发布.NET 10 Preview 1:开启下一代开发框架新篇章
· 没有源码,如何修改代码逻辑?
· PowerShell开发游戏 · 打蜜蜂
· 在鹅厂做java开发是什么体验
· WPF到Web的无缝过渡:英雄联盟客户端的OpenSilver迁移实战