hdfs、zookeepeer之HA模式
HA简介
1.所谓HA,即高可用(high available)
2.消除单点故障,避免集群瘫痪,hdfs中namenode保存了整个集群的元数据,如果namenode所在机器宕机,则整个集群瘫痪,HA
能够即使将备用的namenode替代宕机节点的namenode
3.当机器出现故障,或需要升级等操作时,HA起到了很好的作用
准备工作
1.硬件需求:
三台主机(网络均能ping通、ssh免密服务)
2.软件需求:
①jdk 我使用的是jdk1.8.0_131
②hadoop 我使用hadoop-2.7.2
③zookeeper 我使用zookeeper-3.4.10
以上软件单独的配置我就不说了,网上有很多安装教程,下面我主要说明搭建HA的一些原理、步骤。
HA工作原理
图解:
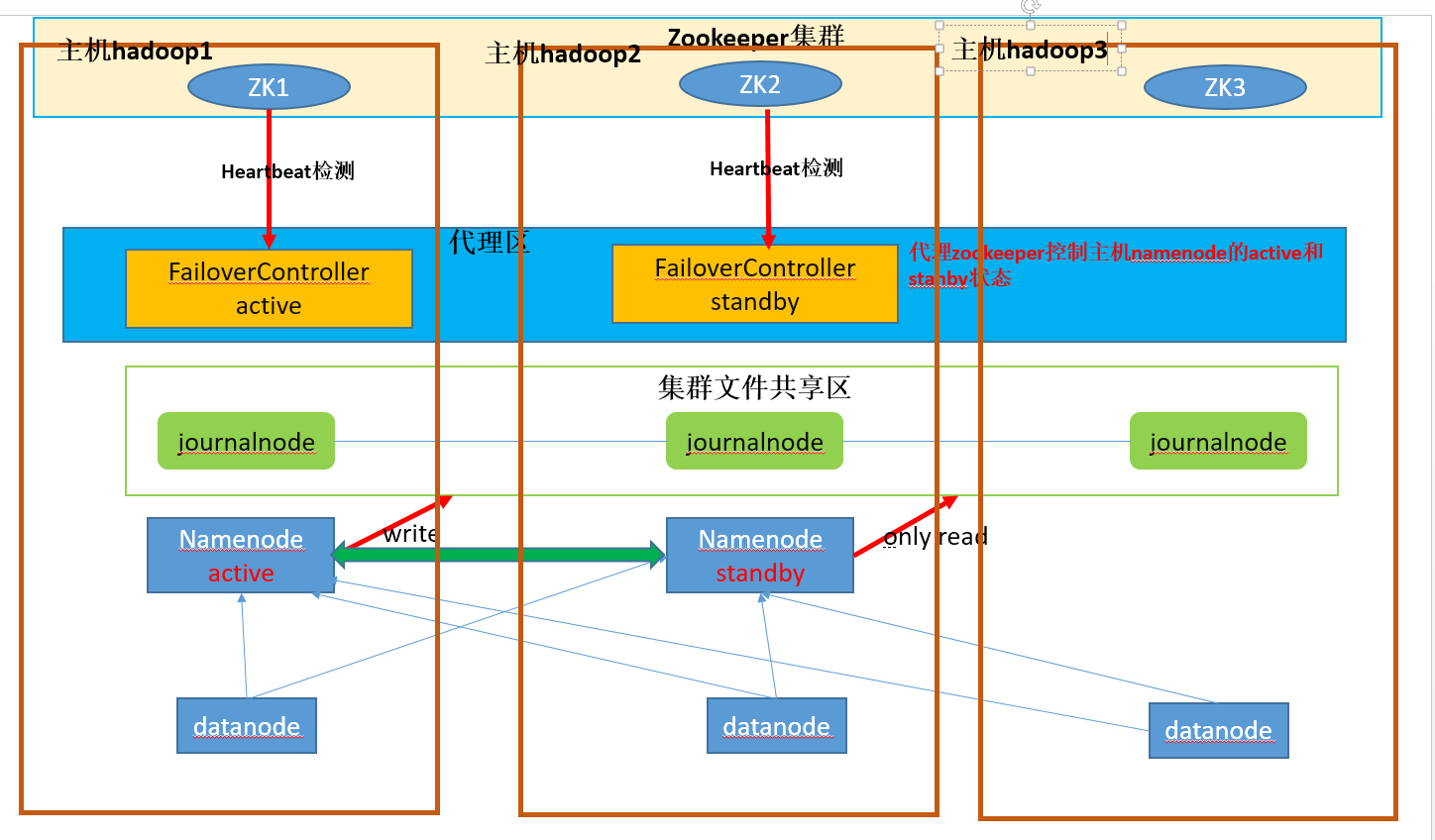
说明:
①集群文件共享区主要存放每个处于active的namenode所写的edit-profile文件和fsimage镜像,供其它备份的namenode节点(即standby namenode)
同步,及时更新集群的元数据信息
②代理区的FailoverController有active和standby两种,它们分别控制同一主机上namenode,防止脑裂现象(brain split)
如:当主机hadoop1和主机hadoop2网络连接异常时,原本hadoop1上的namenode为active,它并没有宕机,而主机hadoop2认为它宕机了,FailoverControlle
stanby 准备将自己主机上的namenode提升为active状态
为了防止脑裂现象,FailoverController stanby会先发送请求给FailoverController active去将它控制的namenode改变为stanby状态,之后hadoop2的namenode
才能为active状态
③JournalNode的作用:两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,
会告知大部分的JournalNodes进程。standby状态的NameNode有能力读取JNS中的变更信息,并且一直监控edit log的变化,把变化应用于自己的命名空间。
standby可以确保在集群出错时,命名空间状态已经完全同步了。
④zookeeper投票选举:zookeeper集群通过心跳检测,监视着集群中各个节点的健康状态,如果发现有节点下线,将自动删除该节点在zookeeper中的信息,进行重新
投票选举。
选举制度
- 默认选举节点数大的作为leader
- leader必须得到集群中半数以上的节点的选举
- 票数相当时,节点值小的节点把自己的票数给大的
hdfs-HA搭建过程
一、zookeeper集群配置
①将zookeeper安装目录下的conf文件夹下zoo-template.cfg改为zoo.cfg,并且做如下配置
修改zookeeper的启动目录:dataDir=/opt/module/zookeeper-3.4.10/data/zkData,并且在安装目录下建立出该路径文件夹
在/opt/module/zookeeper-3.4.10/data/zkData下建立一个myid文件,文件内写集群配置中对应的主机号
添加集群配置:
server.1=centos101:2888:3888 (在centos101主机上/opt/module/zookeeper-3.4.10/data/zkData/myid中写1)
server.2=centos102:2888:3888 (在centos102主机上/opt/module/zookeeper-3.4.10/data/zkData/myid中写2)
server.3=centos103:2888:3888 (在centos103主机上/opt/module/zookeeper-3.4.10/data/zkData/myid中写3)
启动zookeeper集群:分别在每台主机上启动zookeeper
cneos101中 zookeeper-3.4.10/bin/zkServer.sh start
cneos102中 zookeeper-3.4.10/bin/zkServer.sh start
cneos103中 zookeeper-3.4.10/bin/zkServer.sh start
查看启动状态
zookeeper-3.4.10/bin/zkServer.sh status
出现Mode: follower才表示zookeeper集群启动成功,注意:等所有主机都启动zookeeper后才能保证集群中有选举结果,才能查看到集群状态
二、hdfs集群配置
zookeeper结合hdfs的配置写在下面两个配置内了
hdfs-site.xml配置
<configuration> <!--规定副本数--> <property> <name>dfs.replication</name> <value>1</value> </property> <!--规定集群服务名称--> <property> <name>dfs.nameservices</name> <value>mycluster</value> </property> <!--规定指定集群下的namenode的名称--> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property> <!--指定集群下的namenode的rpc通讯地址--> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>centos101:8020</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>centos102:8020</value> </property> <!--指定集群下的namenode的http通讯地址--> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>centos101:50070</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>centos102:50070</value> </property> <!--指定集群下的所有namenode共享journal nodes的位置--> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://centos101:8485;centos102:8485;centos103:8485/mycluster</value> </property> <!--将namenode提起为active时的代理类--> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!--权限检查开关--> <property> <name>dfs.permissions.enable</name> <value>false</value> </property> <!--仿脑裂的隔离机制--> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <!--仿脑裂的隔离机制使用ssh私钥地址--> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/ljm/.ssh/id_rsa</value> </property> <!--开启自动故障转移zookeeper--> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> </configuration>
core-site.xml配置
<configuration> <!-- 指定集群 --> <property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property> <!-- 指定hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/HA/hadoop-2.7.2/data/tmp</value> </property> <!-- JournalNode存储数据的位置 --> <property> <name>dfs.journalnode.edits.dir</name> <value>/opt/module/HA/hadoop-2.7.2/data/tmp/jn</value> </property> <!-- 配置zookepeer集群地址 --> <property> <name>ha.zookeeper.quorum</name> <value>centos101:2181,centos102:2181,centos103:2181</value> </property> </configuration>
三、启动hdfs-HA集群
首次搭建需要
①启动启动所有journalnode
命令:sbin/hadoop-daemon.sh start journalnode
注意:格式化hdfs前,必须启动所有journalnode
②格式化hdfs
命令:bin/hdfs namenode -format
③启动zookeeper(可以写一个脚本一次性启动)
cneos101中 zookeeper-3.4.10/bin/zkServer.sh start
cneos102中 zookeeper-3.4.10/bin/zkServer.sh start
cneos103中 zookeeper-3.4.10/bin/zkServer.sh start
检查zookeeper
zookeeper-3.4.10/bin/zkServer.sh status
④格式化hdfs中的zkfc (即代理FailoverController)
命令:/bin/hdfs zkfc -formatZK
⑤可以一次性启动hdfs
命令:sbin/start-dfs.sh
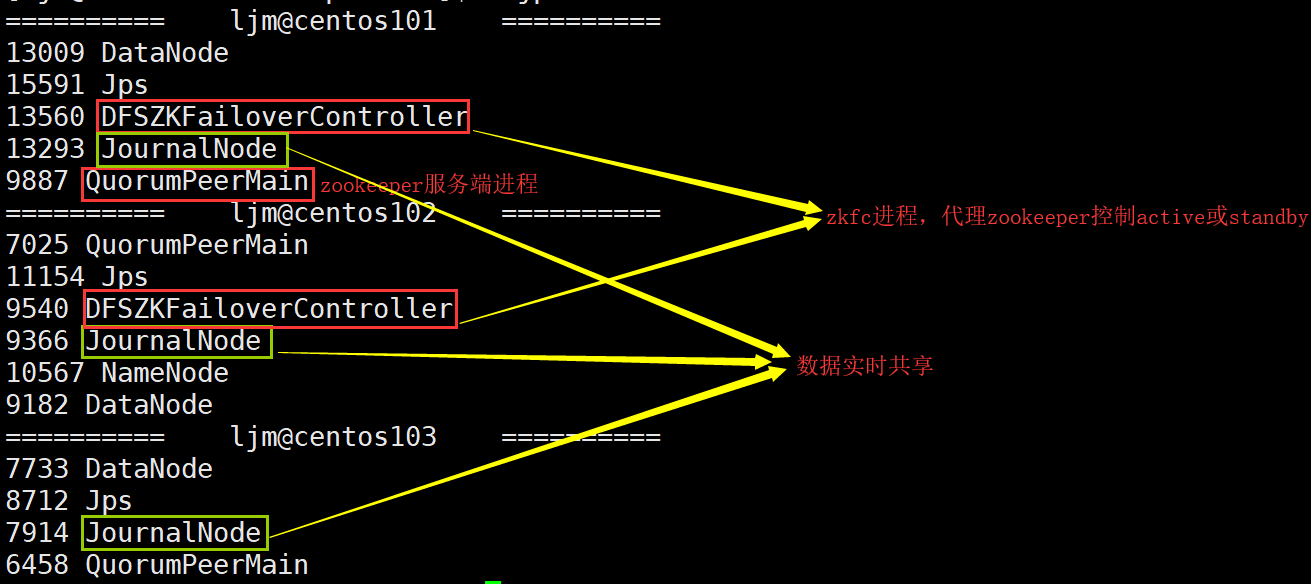
结果如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号