

postgresql CPU使用率告警处理过程
postgresql CPU使用率告警 处理过程
背景
某项目业务数据库在2月底出现频繁的CPU使用率告警,其中在2月28日一天就出现多达25次的告警,特别是在15:35-16:35时间段出现持续10分钟平线无限接近100%的使用率,监控CPU情况如下:

系统情况如下:
PostgreSQL 10.8 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-36), 64-bit处理步骤
工具:
第一步
使用top 查看当前使用CPU情况, 确认造成CPU使用率告警的源头是Postgresql;
第二步
select *from pg_stat_activity where state not in ('idle') and pid <>pg_backend_pid();查看现场的进程情况:
- 可以通过top 中最高CPU使用率的PID ,对应在pg_stat_activity 查询的PID 查看具体的语句,当然可直接使用auto_explain;
- 同时基本可以判断主要是哪个业务库的消耗引起;
第三步
第二步需实时监控,可能因某些原因会错过了事故现场,就比较难实时获取问题代码,基于这个原因,我们需使用【pg_stat_statements】该插件实时收取执行统计信息;
我们可以使用如下代码查看百分比占比最高的前5个语句:
SELECT
round(
(
100 * A .total_time / SUM (A .total_time) OVER ()
) :: NUMERIC,
2
) percent,
--a.dbid,
b.datname,
round(A .total_time :: NUMERIC, 2) AS total,
A .calls,
round(A .mean_time :: NUMERIC, 2) AS mean,
A .query
FROM
pg_stat_statements A
INNER JOIN pg_stat_database b ON A .dbid = b.datid
ORDER BY
total_time DESC
LIMIT 5;通过上述3个步骤就可以定位到问题如下:
SELECT
K .lineid AS lineid,
K .linename AS linename,
K .linestatus AS linestatus,
K .userid AS userid,
K .account AS account,
K .tn_saleareaid AS tn_saleareaid,
K .tn_linetype AS tn_linetype,
K .tn_weekday AS tn_weekday,
K .tn_createtime AS tn_createtime,
SUM (
CASE
WHEN strpos(kx.customertype, '终端') > 0 THEN
1
ELSE
0
END
) AS storecount,
SUM (
CASE
WHEN strpos(kx.customertype, '渠道') > 0 THEN
1
ELSE
0
END
) AS channelcount,
SUM (
CASE
WHEN kx.customertype != '' THEN
1
ELSE
0
END
) AS customercount,
CASE K .linestatus
WHEN 1 THEN
'启用'
ELSE
'停用'
END AS linestatustext,
K .tn_linetype,
CASE
WHEN K .tn_weekday = '0' THEN
'星期天'
WHEN K .tn_weekday = '1' THEN
'星期一'
WHEN K .tn_weekday = '2' THEN
'星期二'
WHEN K .tn_weekday = '3' THEN
'星期三'
WHEN K .tn_weekday = '4' THEN
'星期四'
WHEN K .tn_weekday = '5' THEN
'星期五'
WHEN K .tn_weekday = '6' THEN
'星期六'
ELSE
'无'
END AS tn_weekdaytext,
K .tn_weekday
FROM
kx_visit_line AS K
LEFT JOIN kx_visit_linecustomer AS kx ON kx.lineid = K .lineid
AND kx.platstatus = 1
WHERE
1 = 1
AND NOT EXISTS (
SELECT
ID
FROM
(
SELECT
kx_kq_store. ID,
kx_kq_store.status
FROM
kx_kq_store AS kx_kq_store
WHERE
kx_kq_store.presentative LIKE '%' || '1215946224222474240' || '%'
AND kx_kq_store.platstatus = 1
UNION ALL
SELECT
ka_kq_channelcustomers. ID,
ka_kq_channelcustomers.status
FROM
ka_kq_channelcustomers AS ka_kq_channelcustomers
WHERE
ka_kq_channelcustomers.bizmanager LIKE '%' || '1215946224222474240' || '%'
AND ka_kq_channelcustomers.platstatus = 1
) s
WHERE
s. ID = kx.customerid
AND s.status != 1
)
AND K .userid = '1215946224222474240'
AND K .tn_linetype = '1'
AND K .platstatus = 1
GROUP BY
K .linename,
K .lineid,
K .tn_linetype
ORDER BY
K .tn_createtime DESC
LIMIT 20 OFFSET 0对应的执行计划如下:
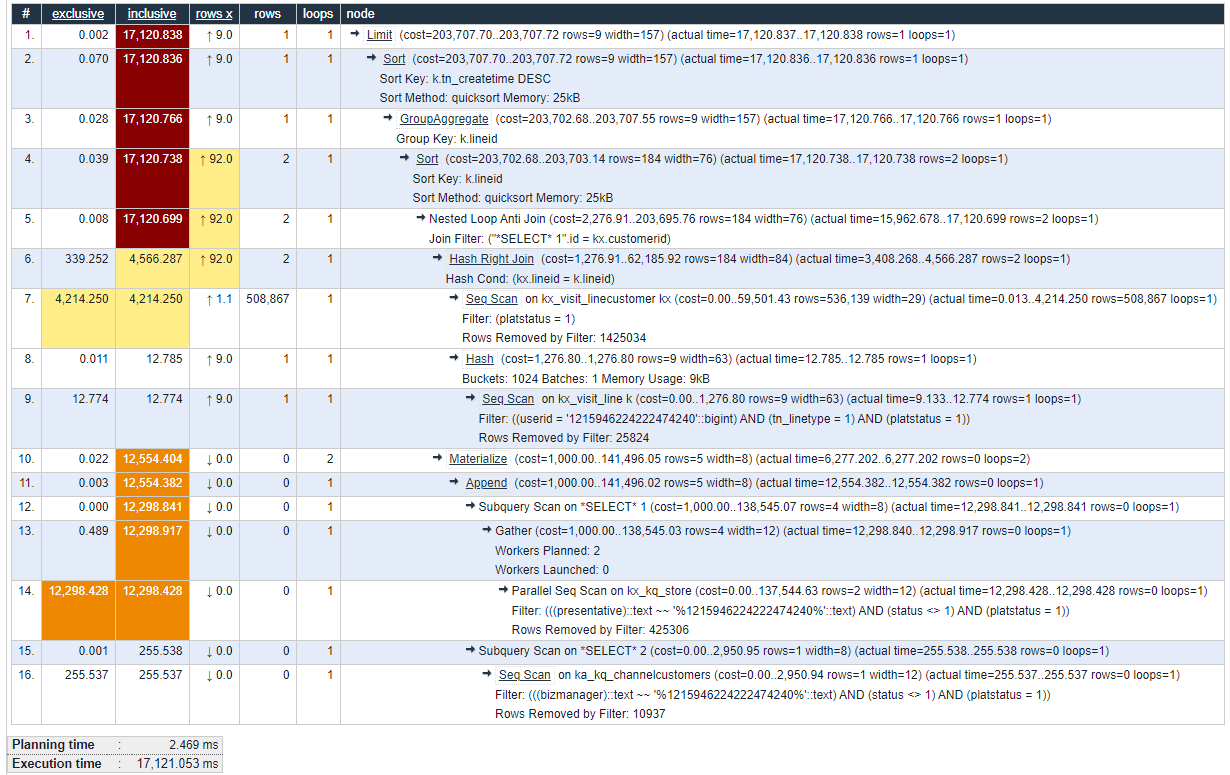
表【kx_visit_line】、【kx_kq_store】、【kx_visit_linecustomer】 和 【ka_kq_channelcustomers】缺失索引造成,在维护窗口新建如下索引;
CREATE INDEX CONCURRENTLY IX_kx_kq_store_presentative ON kx_kq_store USING gin (presentative gin_trgm_ops);
CREATE INDEX CONCURRENTLY ix_kx_visit_line_ ON kx_visit_line (
userid,
tn_linetype,
platstatus
);
CREATE INDEX CONCURRENTLY ix_kx_visit_linecustomer_platstatus ON kx_visit_linecustomer (platstatus);
CREATE INDEX CONCURRENTLY ix_ka_kq_channelcustomers_presentative ON ka_kq_channelcustomers USING gin (bizmanager gin_trgm_ops);
优化后的执行效果如下:

调整后查看上周的监控系统表现如下:

从上图可以看出CPU使用率已出现较明显的改善,但还有个别的突发的瞬时尖峰,后续可持续根据pg_stat_statements的统计信息进行分析;
总结
索引的缺失会造成CPU资源出现瓶颈;
