python入门
0. Python 是什么类型的语言?
脚本语言(Scripting language)是电脑编程语言
1. IDLE 是什么?
IDLE是一个Python Shell,像我们Windows那个cmd窗口,像Linux那个黑乎乎的命令窗口,他们都是shell,利用他们,我们就可以给操作系统下达命令。同样的,我们可以利用IDLE这个shell与Python进行互动。
2. print() 的作用是什么?
print() 会在输出窗口中显示一些文本
3.为什么 >>>print('I love fishc.com ' * 5) 可以正常执行,但 >>>print('I love fishc.com ' + 5) 却报错?
在 Python 中不能把两个完全不同的东西加在一起,比如说数字和文本
5. 如果我需要在一个字符串中嵌入一个双引号,正确的做法是?
可以利用反斜杠(\)对双引号转义:\",或者用单引号引起这个字符串。例如:' I l"o"ve fishc.com '。
定义变量:变量名 = 值 ⼤驼峰:MyName ⼩驼峰:myName 下划线:my_name

输出

输入:input("提示信息")

转换数据类型:

运算符:

条件语句:if elif

if elif else

双重if嵌套:

循环:



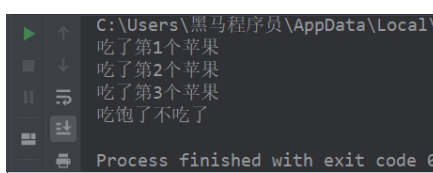


嵌套循环:






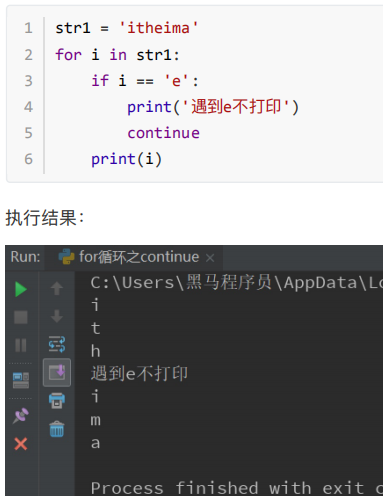
for循环:





切⽚:是指对操作的对象截取其中⼀部分的操作

查找:字符串序列.find(⼦串, 开始位置下标, 结束位置下标)
find():检测某个⼦串是否包含在这个字符串中,如果在返回这个⼦串开始的位置下标,否则则返回-1。
rfind(): 和fifind()功能相同,但查找⽅向为右侧开始。

index():检测某个⼦串是否包含在这个字符串中,如果在返回这个⼦串开始的位置下标,否则报异常。
rindex():和index()功能相同,但查找⽅向为右侧开始。
字符串序列.index(⼦串, 开始位置下标, 结束位置下标)

计数:count():返回某个⼦串在字符串中出现的次数
字符串序列.count(⼦串, 开始位置下标, 结束位置下标)

修改:replace():替换
字符串序列.replace(旧⼦串, 新⼦串, 替换次数)

分割split():按照指定字符分割字符串。
![]()
字符串序列.split(分割字符, num)

合并join():⽤⼀个字符或⼦串合并字符串,即是将多个字符串合并为⼀个新的字符串。
字符或⼦串.join(多字符串组成的序列)

大写capitalize():将字符串第⼀个字符转换成⼤写。
title():将字符串每个单词⾸字⺟转换成⼤写。
upper():将字符串中⼩写转⼤写。



小写lower():将字符串中⼤写转⼩写。


lstrip():删除字符串左侧空⽩字符。
rstrip():删除字符串右侧空⽩字符。
strip():删除字符串两侧空⽩字符。
ljust():返回⼀个原字符串左对⻬,并使⽤指定字符(默认空格)填充⾄对应⻓度 的新字符串。
字符串序列.ljust(⻓度, 填充字符)
rjust():返回⼀个原字符串右对⻬,并使⽤指定字符(默认空格)填充⾄对应⻓度 的新字符串,语法和ljust()相同。
center():返回⼀个原字符串居中对⻬,并使⽤指定字符(默认空格)填充⾄对应⻓度 的新字符串,语法和ljust()相同。
startswith():检查字符串是否是以指定⼦串开头,是则返回 True,否则返回 False。如果设置开始和结束位置下标,则在指定范围内检查。
字符串序列.startswith(⼦串, 开始位置下标, 结束位置下标)
endswith()::检查字符串是否是以指定⼦串结尾,是则返回 True,否则返回 False。如果设置开始和结束位置下标,则在指定范围内检查
字符串序列.endswith(⼦串, 开始位置下标, 结束位置下标)
isalpha():如果字符串⾄少有⼀个字符并且所有字符都是字⺟则返回 True, 否则返回 False。
isdigit():如果字符串只包含数字则返回 True 否则返回 False。
isalnum():如果字符串⾄少有⼀个字符并且所有字符都是字⺟或数字则返 回 True,否则返回
False。
isspace():如果字符串中只包含空⽩,则返回 True,否则返回 False。
列表:列表可以⼀次性存储多个数据,但是列表中的数据允许更改。
列表可以⼀次性存储多个数据,且可以为不同数据类型。
列表的作⽤是⼀次性存储多个数据,程序员可以对这些数据进⾏的操作有:增、删、改、查。

元组:特点:定义元组使⽤⼩括号,且逗号隔开各个数据,数据可以是不同的数据类型。元组数据不⽀持修改,只⽀持查找


按下标查找数据
index():查找某个数据,如果数据存在返回对应的下标,否则报错,语法和列表、字符串的index⽅法相同。
count():统计某个数据在当前元组出现的次数。
len():统计元组中数据的个数。

列表查找:

index():返回指定数据所在位置的下标 。
列表序列.index(数据, 开始位置下标, 结束位置下标)

count():统计指定数据在当前列表中出现的次数。

len():访问列表⻓度,即列表中数据的个数。

in:判断指定数据在某个列表序列,如果在返回True,否则返回False

not in:判断指定数据不在某个列表序列,如果不在返回True,否则返回False


增加:增加指定数据到列表中
append():列表结尾追加数据
列表序列.append(数据)


extend():列表结尾追加数据,如果数据是⼀个序列,则将这个序列的数据逐⼀添加到列表。
列表序列.extend(数据)


insert():指定位置新增数据。
列表序列.insert(位置下标, 数据)

删除del:del ⽬标


pop():删除指定下标的数据(默认为最后⼀个),并返回该数据。
列表序列.pop(下标)

remove():移除列表中某个数据的第⼀个匹配项。
列表序列.remove(数据)

clear():清空列表

修改

逆置:reverse()

排序:sort()
列表序列.sort( key=None, reverse=False)

复制:copy()

列表的循环遍历:


列表嵌套:

创建集合使⽤ {} 或 set() , 但是如果要创建空集合只能使⽤ set() ,因为 {} ⽤来创建空字典。
1. 集合可以去掉重复数据;
2. 集合数据是⽆序的,故不⽀持下标

增加数据:add()
update(), 追加的数据是序列。


删除数据
remove(),删除集合中的指定数据,如果数据不存在则报错。
discard(),删除集合中的指定数据,如果数据不存在也不会报错。
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
pop(),随机删除集合中的某个数据,并返回这个数据。



查找数据

思考1: 如果有多个数据,例如:'Tom', '男', 20,如何快速存储?
答:列表
思考2:如何查找到数据'Tom'?
答:查找到下标为0的数据即可。
思考3:如果将来数据顺序发⽣变化,如下所示,还能⽤ list1[0] 访问到数据'Tom'吗?。
list1 = ['男', 20, 'Tom']
答:不能,数据'Tom'此时下标为2。
字典⾥⾯的数据是以键值对形式出现,字典数据和数据顺序没有关系,即字典不⽀持下标,
后期⽆论数据如何变化,只需要按照对应的键的名字查找数据即可。
①符号为⼤括号②数据为键值对形式出现③各个键值对之间⽤逗号隔开
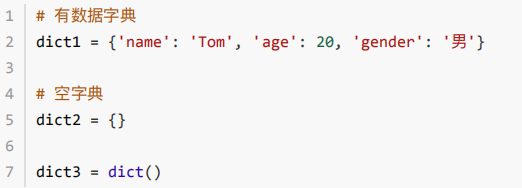
增:字典序列[key] = 值

删del() / del:删除字典或删除字典中指定键值对。
clear():清空字典


改
写法:字典序列[key] = 值
注意:如果key存在则修改这个key对应的值 ;如果key不存在则新增此键值对。
查
key值查找

get()
字典序列.get(key, 默认值)
注意:如果当前查找的key不存在则返回第⼆个参数(默认值),如果省略第⼆个参数,则返回None。

keys()

values()

items()

字典的循环遍历
遍历字典的key

遍历字典的value

遍历字典的元素

遍历字典的键值对


 浙公网安备 33010602011771号
浙公网安备 33010602011771号