第二十二天 集合
一、集合的由来
通常,我们的程序需要根据程序运行时才知道创建多少个对象。但若非程序运行,程序开发阶段,我们根本不知道到底需要多少个数量的对象,甚至不知道它的准确类型。为了满足这些常规的编程需要,我们要求能在任何时候,任何地点创建任意数量的对象,而这些对象用什么来容纳呢?首先我们前面讲解了数组,但是数组一方面只能存放同一类型的数据,另一方面其长度是固定的,显然不满足前面的需求,所以集合便应运而生了!
二、集合是什么?
Java集合类存放于 java.util 包中,是一个用来存放对象的容器。
注意:
①、集合只能存放对象。比如你存一个 int 型数据 1放入集合中,其实它是自动转换成 Integer 类后存入的,Java中每一种基本类型都有对应的引用类型。
②、集合存放的是多个对象的引用,对象本身还是放在堆内存中。
③、集合可以存放不同类型,不限数量的数据类型。
三、Java 集合框架图
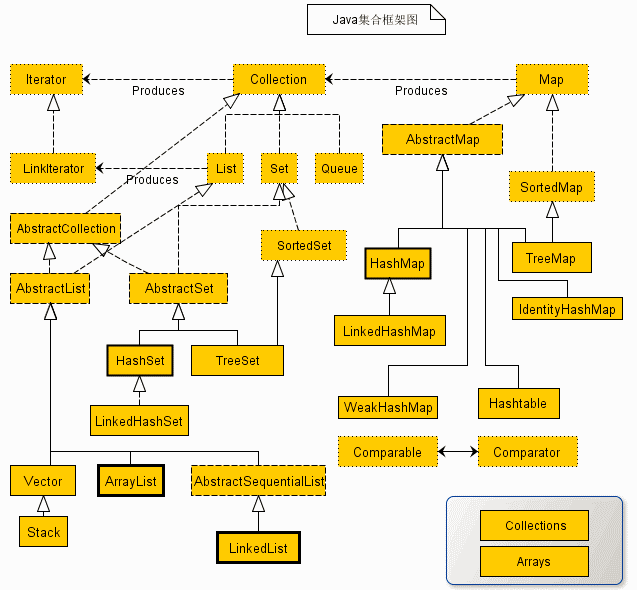
从上面的集合框架图可以看到,Java 集合框架主要包括两种类型的容器,一种是集合(Collection),存储一个元素集合,另一种是图(Map),存储键/值对映射。Collection 接口又有 3 种子类型,List、Set 和 Queue,再下面是一些抽象类,最后是具体实现类,常用的有 ArrayList、LinkedList、HashSet、LinkedHashSet、HashMap、LinkedHashMap 等等。
四、集合详解
①Iterator:迭代器,它是Java集合的顶层接口(不包括 map 系列的集合,Map接口 是 map 系列集合的顶层接口)
Object next():返回迭代器刚越过的元素的引用,返回值是 Object,需要强制转换成自己需要的类型
boolean hasNext():判断容器内是否还有可供访问的元素
void remove():删除迭代器刚越过的元素
所以除了 map 系列的集合,我们都能通过迭代器来对集合中的元素进行遍历。
注意:我们可以在源码中追溯到集合的顶层接口,比如 Collection 接口,可以看到它继承的是类 Iterable
那这就得说明一下 Iterator 和 Iterable 的区别:
Iterable :存在于 java.lang 包中。
我们可以看到,里面封装了 Iterator 接口。所以只要实现了只要实现了Iterable接口的类,就可以使用Iterator迭代器了。
Iterator :存在于 java.util 包中。核心的方法next(),hasnext(),remove()。
这里我们引用一个Iterator 的实现类 ArrayList 来看一下迭代器的使用:
import java.util.ArrayList; import java.util.Collection; import java.util.Iterator; public class Demo { public static void main(String[] args) { ////Collection集合的遍历 Collection collection = new ArrayList();//新申请一个arraylist对象,并赋值给类型为collection的变量c collection.add("张3"); collection.add("张4"); collection.add("张5"); // 第一步:使用集合中的方法 iterator() 获取送代器的实现类对象 // 第二步:使用Iterator接口接收(多态) Iterator iterator = collection.iterator();//构造list的迭代器 // 第三步:使用Iterator接口中的方法hasNext来判断还有没有下一个元素 while (iterator.hasNext()) { //通过迭代器遍历元素 // 第四步:使用Iterator接口中的方法next来取出集合中的下一个元素 String str = (String) iterator.next(); System.out.println(str); } } }
②Collection:List 接口和 Set 接口的父接口
看一下 Collection 集合的使用例子:
public class Demo { public static void main(String[] args) { //新申请一个arraylist对象,并赋值给类型为collection的变量c Collection collection = new ArrayList(); //添加元素 collection.add("张1"); collection.add("张2"); collection.add("张3"); collection.add("张4"); //while集合的遍历 Iterator iterator = collection.iterator(); while (iterator.hasNext()) { String name = (String) iterator.next(); System.out.println("iterator:"+name); } collection.add("张5"); // //for集合的遍历 for(Object obj:collection) { System.out.println("for"+obj); } //删除一个元素张5 //collection.remove("张5"); //删除全部元素 collection.removeAll(collection); for(Object obj:collection) { System.out.println("for"+obj); } //集合是否为空 System.out.println(collection.isEmpty()); } }
③List :有序,可以重复的集合。
由于 List 接口是继承于 Collection 接口,所以基本的方法如上所示。
1、List 接口的三个典型实现:
①、List list1 = new ArrayList();
底层数据结构是数组,查询快,增删慢; 线程不安全,效率高
②、List list2 = new Vector();
底层数据结构是数组,查询快,增删慢; 线程安全,效率低,几乎已经淘汰了这个集合
③、List list3 = new LinkedList();
底层数据结构是链表,查询慢,增删快; 线程不安全,效率高
怎么区别底层数据结构是数组的ArrayList和底层数据结构是链表的LinkedList呢?怎么记呢?我们可以想象:
数组就像身上编了号站成一排的人,要找第10个人很容易,根据人身上的编号很快就能找到。但插入、删除慢,要往某个位置插入或删除一个人时,后面的人身上的编号都要变。当然,加入或删除的人始终末尾的也快。
链表就像手牵着手站成一圈的人,要找第10个人不容易,必须从第一个人一个个数过去。但插入、删除快。插入时只要解开两个人的手,并重新牵上新加进来的人的手就可以。删除一样的道理。
2、除此之外,List 接口遍历还可以使用普通 for 循环进行遍历,指定位置添加元素,替换元素等等。
//产生一个 List 集合,典型实现为 ArrayList
List list = new ArrayList();
//添加三个元素
list.add("Tom");
list.add("Bob");
list.add("Marry");
//构造 List 的迭代器
Iterator it = list.iterator();
//通过迭代器遍历元素
while(it.hasNext()){
Object obj = it.next();
//System.out.println(obj);
}
//在指定地方添加元素,2是索引,0是要插入的值
list.add(2, 0);
//在指定地方替换元素,2是索引,1是要替换原目标的值
list.set(2, 1);
//获得指定对象的索引
int i=list.indexOf(1);
System.out.println("索引为:"+i);
//遍历:普通for循环
for(int j=0;j<list.size();j++){
System.out.println(list.get(j));
}
④Set:典型实现 HashSet()是一个无序,不可重复的集合
1、Set hashSet = new HashSet();
①、HashSet:不能保证元素的顺序;不可重复;不是线程安全的;集合元素可以为 NULL;
②、其底层其实是一个数组,存在的意义是加快查询速度。我们知道在一般的数组中,元素在数组中的索引位置是随机的,元素的取值和元素的位置之间不存在确定的关系,因此,在数组中查找特定的值时,需要把查找值和一系列的元素进行比较,此时的查询效率依赖于查找过程中比较的次数。而 HashSet 集合底层数组的索引和值有一个确定的关系:index=hash(value),那么只需要调用这个公式,就能快速的找到元素或者索引。
③、对于 HashSet: 如果两个对象通过 equals() 方法返回 true,这两个对象的 hashCode 值也应该相同。
1、当向HashSet集合中存入一个元素时,HashSet会先调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据hashCode值决定该对象在HashSet中的存储位置
1.1、如果 hashCode 值和现存的对象的都不同,直接把该元素存储到 hashCode() 指定的位置
1.2、如果 hashCode 值和现存的对象中某一个对象的相同,那么会继续判断该元素和集合对象的 equals() 作比较
1.2.1、hashCode 相同,equals 为 true,则视为同一个对象,不保存在 hashSet()中
1.2.2、hashCode 相同,equals 为 false,则存储在之前对象同槽位的链表上,这非常麻烦,我们应该约束这种情况,即保证:如果两个对象通过 equals() 方法返回 true,这两个对象的 hashCode 值也应该相同。(着也是前面强调重写equals方法一定要重写hashCode方法的原因)
注意:每一个存储到 哈希 表中的对象,都得提供 hashCode() 和 equals() 方法的实现,用来判断是否是同一个对象
对于 HashSet 集合,我们要保证如果两个对象通过 equals() 方法返回 true,这两个对象的 hashCode 值也应该相同。
3、Set treeSet = new TreeSet();
TreeSet:有序;不可重复,底层使用 红黑树算法,擅长于范围查询。
* 如果使用 TreeSet() 无参数的构造器创建一个 TreeSet 对象, 则要求放入其中的元素的类必须实现 Comparable 接口,所以, 在其中不能放入 null 元素
* 必须放入同样类的对象.(默认会进行排序) 否则可能会发生类型转换异常.我们可以使用泛型来进行限制
Set treeSet = new TreeSet();
treeSet.add(1); //添加一个 Integer 类型的数据
treeSet.add("a"); //添加一个 String 类型的数据
System.out.println(treeSet); //会报类型转换异常的错误
以上三个 Set 接口的实现类比较:
共同点:1、都不允许元素重复
2、都不是线程安全的类,解决办法:Set set = Collections.synchronizedSet(set 对象)
不同点:
HashSet:不保证元素的添加顺序,底层采用 哈希表算法,查询效率高。判断两个元素是否相等,equals() 方法返回 true,hashCode() 值相等。即要求存入 HashSet 中的元素要覆盖 equals() 方法和 hashCode()方法
LinkedHashSet:HashSet 的子类,底层采用了 哈希表算法以及 链表算法,既保证了元素的添加顺序,也保证了查询效率。但是整体性能要低于 HashSet
TreeSet:不保证元素的添加顺序,但是会对集合中的元素进行排序。底层采用 红-黑 树算法(树结构比较适合范围查询)
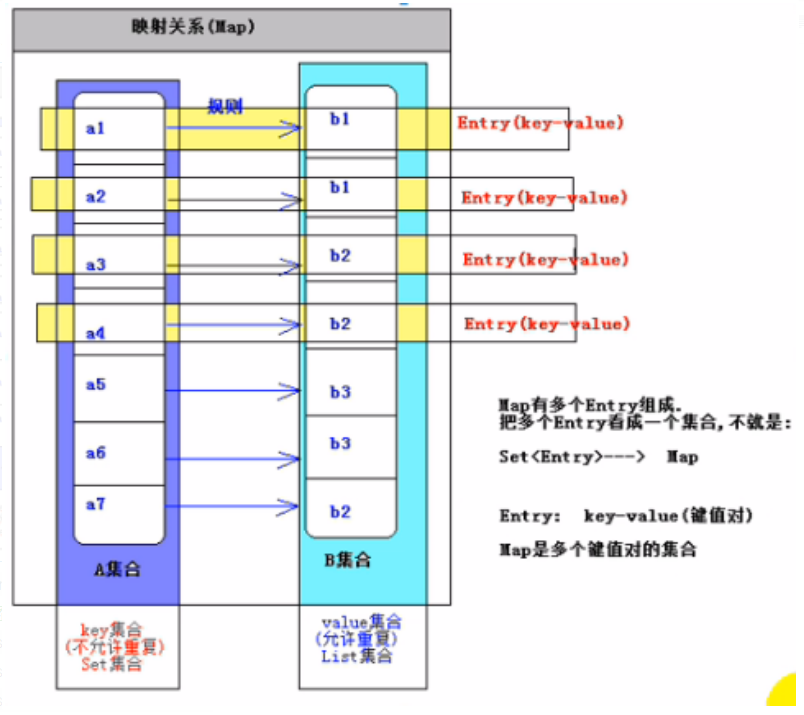
⑤Map:key-value 的键值对,key 不允许重复,value 可以
1、严格来说 Map 并不是一个集合,而是两个集合之间 的映射关系。
2、这两个集合每一条数据通过映射关系,我们可以看成是一条数据。即 Entry(key,value)。Map 可以看成是由多个 Entry 组成。
3、因为 Map 集合即没有实现于 Collection 接口,也没有实现 Iterable 接口,所以不能对 Map 集合进行 foreach 遍历。
Map<String,Object> hashMap = new HashMap<>();
//添加元素到 Map 中
hashMap.put("key1", "value1");
hashMap.put("key2", "value2");
hashMap.put("key3", "value3");
hashMap.put("key4", "value4");
hashMap.put("key5", "value5");
//删除 Map 中的元素,通过 key 的值
hashMap.remove("key1");
//通过 get(key) 得到 Map 中的value
Object str1 = hashMap.get("key1");
//可以通过 添加 方法来修改 Map 中的元素
hashMap.put("key2", "修改 key2 的 Value");
//通过 map.values() 方法得到 Map 中的 value 集合
Collection<Object> value = hashMap.values();
for(Object obj : value){
//System.out.println(obj);
}
//通过 map.keySet() 得到 Map 的key 的集合,然后 通过 get(key) 得到 Value
Set<String> set = hashMap.keySet();
for(String str : set){
Object obj = hashMap.get(str);
//System.out.println(str+"="+obj);
}
//通过 Map.entrySet() 得到 Map 的 Entry集合,然后遍历
Set<Map.Entry<String, Object>> entrys = hashMap.entrySet();
for(Map.Entry<String, Object> entry: entrys){
String key = entry.getKey();
Object value2 = entry.getValue();
System.out.println(key+"="+value2);
}
System.out.println(hashMap);
Map 的常用方法:
⑥Map 和 Set 集合的关系
1、都有几个类型的集合。HashMap 和 HashSet ,都采 哈希表算法;TreeMap 和 TreeSet 都采用 红-黑树算法;LinkedHashMap 和 LinkedHashSet 都采用 哈希表算法和红-黑树算法。
2、分析 Set 的底层源码,我们可以看到,Set 集合 就是 由 Map 集合的 Key 组成。
一、集合的由来
通常,我们的程序需要根据程序运行时才知道创建多少个对象。但若非程序运行,程序开发阶段,我们根本不知道到底需要多少个数量的对象,甚至不知道它的准确类型。为了满足这些常规的编程需要,我们要求能在任何时候,任何地点创建任意数量的对象,而这些对象用什么来容纳呢?首先我们前面讲解了数组,但是数组一方面只能存放同一类型的数据,另一方面其长度是固定的,显然不满足前面的需求,所以集合便应运而生了!
二、集合是什么?
Java集合类存放于 java.util 包中,是一个用来存放对象的容器。
注意:
①、集合只能存放对象。比如你存一个 int 型数据 1放入集合中,其实它是自动转换成 Integer 类后存入的,Java中每一种基本类型都有对应的引用类型。
②、集合存放的是多个对象的引用,对象本身还是放在堆内存中。
③、集合可以存放不同类型,不限数量的数据类型。
三、Java 集合框架图
从上面的集合框架图可以看到,Java 集合框架主要包括两种类型的容器,一种是集合(Collection),存储一个元素集合,另一种是图(Map),存储键/值对映射。Collection 接口又有 3 种子类型,List、Set 和 Queue,再下面是一些抽象类,最后是具体实现类,常用的有 ArrayList、LinkedList、HashSet、LinkedHashSet、HashMap、LinkedHashMap 等等。
四、集合详解
①Iterator:迭代器,它是Java集合的顶层接口(不包括 map 系列的集合,Map接口 是 map 系列集合的顶层接口)
Object next():返回迭代器刚越过的元素的引用,返回值是 Object,需要强制转换成自己需要的类型
boolean hasNext():判断容器内是否还有可供访问的元素
void remove():删除迭代器刚越过的元素
所以除了 map 系列的集合,我们都能通过迭代器来对集合中的元素进行遍历。
注意:我们可以在源码中追溯到集合的顶层接口,比如 Collection 接口,可以看到它继承的是类 Iterable
那这就得说明一下 Iterator 和 Iterable 的区别:
Iterable :存在于 java.lang 包中。
我们可以看到,里面封装了 Iterator 接口。所以只要实现了只要实现了Iterable接口的类,就可以使用Iterator迭代器了。
Iterator :存在于 java.util 包中。核心的方法next(),hasnext(),remove()。
这里我们引用一个Iterator 的实现类 ArrayList 来看一下迭代器的使用:
//产生一个 List 集合,典型实现为 ArrayList。
List list = new ArrayList();
//添加三个元素
list.add("Tom");
list.add("Bob");
list.add("Marry");
//构造 List 的迭代器
Iterator it = list.iterator();
//通过迭代器遍历元素
while(it.hasNext()){
Object obj = it.next();
System.out.println(obj);
}
②Collection:List 接口和 Set 接口的父接口
看一下 Collection 集合的使用例子:
//我们这里将 ArrayList集合作为 Collection 的实现类
Collection collection = new ArrayList();
//添加元素
collection.add("Tom");
collection.add("Bob");
//删除指定元素
collection.remove("Tom");
//删除所有元素
collection.removeAll(collection);
//检测是否存在某个元素
collection.contains("Tom");
//判断是否为空
collection.isEmpty();
//利用迭代器 Iterator
Iterator iterator = collection.iterator();
while(iterator.hasNext()){
Object obj = iterator.next();
System.out.println(obj);
}
//利用增强for循环遍历集合
for(Object obj : collection){
System.out.println(obj);
}
③List :有序,可以重复的集合。
由于 List 接口是继承于 Collection 接口,所以基本的方法如上所示。
1、List 接口的三个典型实现:
①、List list1 = new ArrayList();
底层数据结构是数组,查询快,增删慢; 线程不安全,效率高
②、List list2 = new Vector();
底层数据结构是数组,查询快,增删慢; 线程安全,效率低,几乎已经淘汰了这个集合
③、List list3 = new LinkedList();
底层数据结构是链表,查询慢,增删快; 线程不安全,效率高
怎么区别底层数据结构是数组的ArrayList和底层数据结构是链表的LinkedList呢?怎么记呢?我们可以想象:
数组就像身上编了号站成一排的人,要找第10个人很容易,根据人身上的编号很快就能找到。但插入、删除慢,要往某个位置插入或删除一个人时,后面的人身上的编号都要变。当然,加入或删除的人始终末尾的也快。
链表就像手牵着手站成一圈的人,要找第10个人不容易,必须从第一个人一个个数过去。但插入、删除快。插入时只要解开两个人的手,并重新牵上新加进来的人的手就可以。删除一样的道理。
2、除此之外,List 接口遍历还可以使用普通 for 循环进行遍历,指定位置添加元素,替换元素等等。
//产生一个 List 集合,典型实现为 ArrayList
List list = new ArrayList();
//添加三个元素
list.add("Tom");
list.add("Bob");
list.add("Marry");
//构造 List 的迭代器
Iterator it = list.iterator();
//通过迭代器遍历元素
while(it.hasNext()){
Object obj = it.next();
//System.out.println(obj);
}
//在指定地方添加元素,2是索引,0是要插入的值
list.add(2, 0);
//在指定地方替换元素,2是索引,1是要替换原目标的值
list.set(2, 1);
//获得指定对象的索引
int i=list.indexOf(1);
System.out.println("索引为:"+i);
//遍历:普通for循环
for(int j=0;j<list.size();j++){
System.out.println(list.get(j));
}
④Set:典型实现 HashSet()是一个无序,不可重复的集合
1、Set hashSet = new HashSet();
①、HashSet:不能保证元素的顺序;不可重复;不是线程安全的;集合元素可以为 NULL;
②、其底层其实是一个数组,存在的意义是加快查询速度。我们知道在一般的数组中,元素在数组中的索引位置是随机的,元素的取值和元素的位置之间不存在确定的关系,因此,在数组中查找特定的值时,需要把查找值和一系列的元素进行比较,此时的查询效率依赖于查找过程中比较的次数。而 HashSet 集合底层数组的索引和值有一个确定的关系:index=hash(value),那么只需要调用这个公式,就能快速的找到元素或者索引。
③、对于 HashSet: 如果两个对象通过 equals() 方法返回 true,这两个对象的 hashCode 值也应该相同。
1、当向HashSet集合中存入一个元素时,HashSet会先调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据hashCode值决定该对象在HashSet中的存储位置
1.1、如果 hashCode 值和现存的对象的都不同,直接把该元素存储到 hashCode() 指定的位置
1.2、如果 hashCode 值和现存的对象中某一个对象的相同,那么会继续判断该元素和集合对象的 equals() 作比较
1.2.1、hashCode 相同,equals 为 true,则视为同一个对象,不保存在 hashSet()中
1.2.2、hashCode 相同,equals 为 false,则存储在之前对象同槽位的链表上,这非常麻烦,我们应该约束这种情况,即保证:如果两个对象通过 equals() 方法返回 true,这两个对象的 hashCode 值也应该相同。(着也是前面强调重写equals方法一定要重写hashCode方法的原因)
注意:每一个存储到 哈希 表中的对象,都得提供 hashCode() 和 equals() 方法的实现,用来判断是否是同一个对象
对于 HashSet 集合,我们要保证如果两个对象通过 equals() 方法返回 true,这两个对象的 hashCode 值也应该相同。
3、Set treeSet = new TreeSet();
TreeSet:有序;不可重复,底层使用 红黑树算法,擅长于范围查询。
* 如果使用 TreeSet() 无参数的构造器创建一个 TreeSet 对象, 则要求放入其中的元素的类必须实现 Comparable 接口,所以, 在其中不能放入 null 元素
* 必须放入同样类的对象.(默认会进行排序) 否则可能会发生类型转换异常.我们可以使用泛型来进行限制
Set treeSet = new TreeSet();
treeSet.add(1); //添加一个 Integer 类型的数据
treeSet.add("a"); //添加一个 String 类型的数据
System.out.println(treeSet); //会报类型转换异常的错误
以上三个 Set 接口的实现类比较:
共同点:1、都不允许元素重复
2、都不是线程安全的类,解决办法:Set set = Collections.synchronizedSet(set 对象)
不同点:
HashSet:不保证元素的添加顺序,底层采用 哈希表算法,查询效率高。判断两个元素是否相等,equals() 方法返回 true,hashCode() 值相等。即要求存入 HashSet 中的元素要覆盖 equals() 方法和 hashCode()方法
LinkedHashSet:HashSet 的子类,底层采用了 哈希表算法以及 链表算法,既保证了元素的添加顺序,也保证了查询效率。但是整体性能要低于 HashSet
TreeSet:不保证元素的添加顺序,但是会对集合中的元素进行排序。底层采用 红-黑 树算法(树结构比较适合范围查询)
⑤Map:key-value 的键值对,key 不允许重复,value 可以
1、严格来说 Map 并不是一个集合,而是两个集合之间 的映射关系。
2、这两个集合每一条数据通过映射关系,我们可以看成是一条数据。即 Entry(key,value)。Map 可以看成是由多个 Entry 组成。
3、因为 Map 集合即没有实现于 Collection 接口,也没有实现 Iterable 接口,所以不能对 Map 集合进行 foreach 遍历。
Map<String,Object> hashMap = new HashMap<>();
//添加元素到 Map 中
hashMap.put("key1", "value1");
hashMap.put("key2", "value2");
hashMap.put("key3", "value3");
hashMap.put("key4", "value4");
hashMap.put("key5", "value5");
//删除 Map 中的元素,通过 key 的值
hashMap.remove("key1");
//通过 get(key) 得到 Map 中的value
Object str1 = hashMap.get("key1");
//可以通过 添加 方法来修改 Map 中的元素
hashMap.put("key2", "修改 key2 的 Value");
//通过 map.values() 方法得到 Map 中的 value 集合
Collection<Object> value = hashMap.values();
for(Object obj : value){
//System.out.println(obj);
}
//通过 map.keySet() 得到 Map 的key 的集合,然后 通过 get(key) 得到 Value
Set<String> set = hashMap.keySet();
for(String str : set){
Object obj = hashMap.get(str);
//System.out.println(str+"="+obj);
}
//通过 Map.entrySet() 得到 Map 的 Entry集合,然后遍历
Set<Map.Entry<String, Object>> entrys = hashMap.entrySet();
for(Map.Entry<String, Object> entry: entrys){
String key = entry.getKey();
Object value2 = entry.getValue();
System.out.println(key+"="+value2);
}
System.out.println(hashMap);
Map 的常用方法:
⑥Map 和 Set 集合的关系
1、都有几个类型的集合。HashMap 和 HashSet ,都采 哈希表算法;TreeMap 和 TreeSet 都采用 红-黑树算法;LinkedHashMap 和 LinkedHashSet 都采用 哈希表算法和红-黑树算法。
2、分析 Set 的底层源码,我们可以看到,Set 集合 就是 由 Map 集合的 Key 组成。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号