面试十、java内存模型
1、模型
堆、栈、方法区
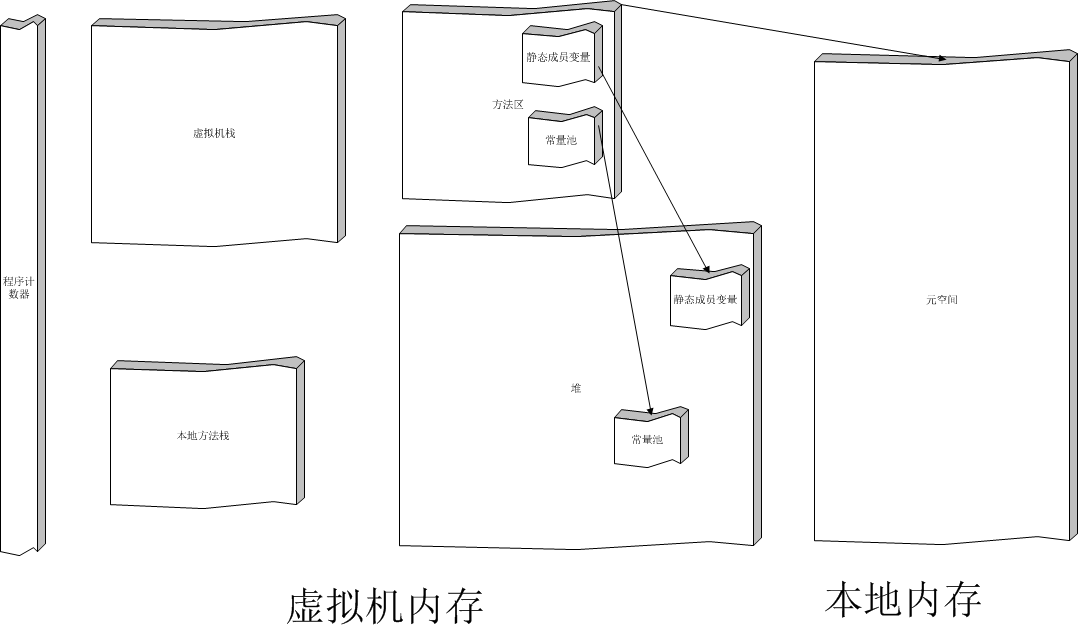
程序计数器:pc寄存器,存放下一条要执行的指令的地址
虚拟机栈:每个线程拥有独立的栈,存放局部变量、对象引用、操作数栈、方法出口
堆:由所有线程共享,运行时申请内存在堆分配,存放对象、数组,jdk1.8后静态变量和常量池放入堆中
本地方法区:本地方法
方法区:jdk1.8前存放类的信息、静态变量、常量池、方法代码。
元空间:jdk1.8后取消了永久代,推出元空间,存放类的信息和方法代码。使用的不是虚拟机内存而是本地内存
存放在堆里的对象可以别持有该对象引用的线程访问,当一个线程可以访问对象时也可以访问它的成员变量,多个线程可以同时访问调用一个对象的方法和成员变量只是线程自己会拥有对
对象的私有拷贝。
2、为何要去除永久代
字符串存在永久代容易造成内存溢出
类信息和方法信息大小比较难确定,导致不好分配永久代大小,太小容易永久代溢出太大容易老年代溢出
GC效率低
3、堆内存模型
3.1、新生代:
1)Eden:存储最新创建的对象、数组等
2)S0/S1:存储Eden gc后的对象和数组
gc过程(复制算法):
新创建的对象存放在Eden中
当Eden容量第一次触发gc时,会将Eden中存活的对象复制放入S0中
当Eden触发第二次gc时,会将Eden和S0中存活的对象复制放入S1中
如此循环
3.2、老年代:
新生代多次gc后依旧存活的对象晋升入老年代
gc过程(标记-整理):
将死亡的对象清除
然后整理内存空间
为什么不用复制:此处的对象可能很大,复制浪费资源
3.3、永久代/元空间(jdk1.8)
jdk1.8后引入元空间,使用的是本机内存而不是虚拟几内存(原因看上面)
3.4、如何判断对象是否存活
1)引用计数:对象被引用值加1,值为0时即无引用可gc
2)可达性分析:从GC-Root作为起点开始搜索所有节点,如果对象没有在节点上可gc
3.5、gc算法
1)标记-清除:将对象标记存活还是死亡,gc时清除死亡对象。
缺点:标记效率低,清除后导致内存碎片
2)复制:将内存分为A/B两块,当A用完了将存活的复制进入B并清空A,如此循环
优点:只需标记存活对象,效率有提高
缺点:可用空间只有一半
3)标记-整理:将存活对象标记移动到一端,将边界外的清空
老年代存活对象多使用复制算法效率低
3.6、收集器
1)Serial收集器:采用单线程基于复制算法的串行收集器,工作在新生代(默认)
2)parNew收集器:多线程其余和Serail一致
3)SerailOld收集器:采用单线程基于标记-整理算法的串行收集器,工作在老年代(默认)
4)ParOld收集器:多线程其余和SerailOld一致
5)cms:基于标记-清除算法并发gc,工作在老年代
6)G1:基于标记-整理,工作在新生代和老年代。分代收集不需其他收集器就可同时管理整个堆
posted on 2021-08-26 21:05 Iversonstear 阅读(159) 评论(0) 编辑 收藏 举报

