面试二十二、rocketMq
1、作用
1)解藕
2)有些任务没有实时性要求,当前因为请求量瞬间值高导致服务撑不住,
这时可以把任务放在mq里慢慢消费调。例如统计优惠券使用数量
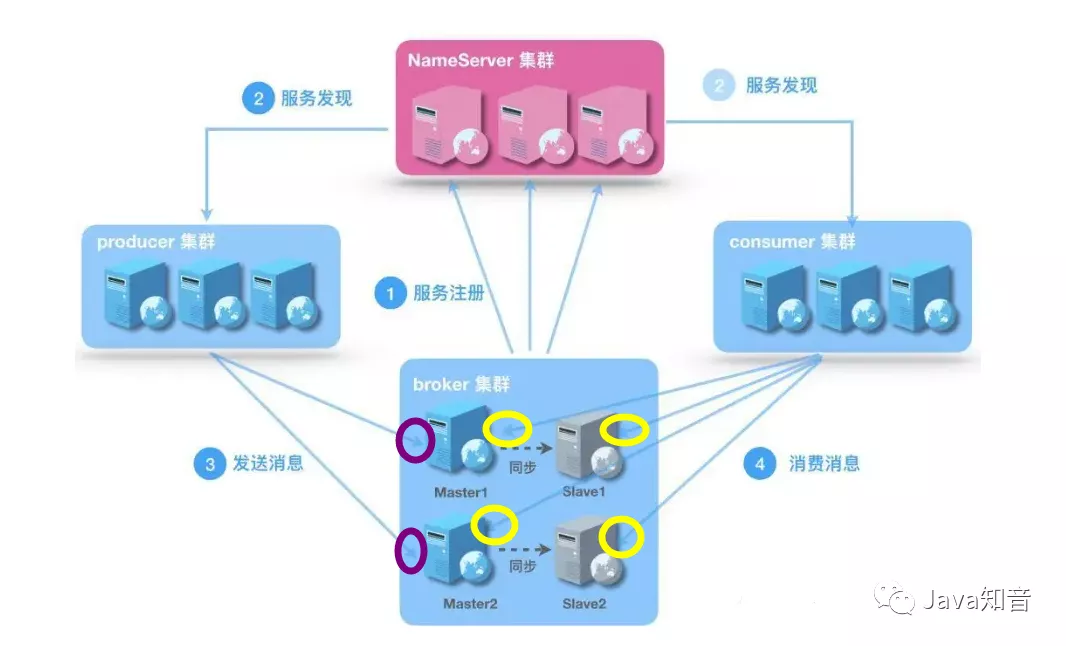
2、rocketmq有哪些角色组成,作用是什么
1)nameserver:服务发现者,producer、borker、consumer都需定时向其上报自己的信息
以便互相发现彼此,如超时不上报则会从列表删除。
2)producer:生产者,随机获得一个nameserver节点建立长连接,
获取topic信息(topic路由、topic下queue、queue分布在哪些broker)
和topic的master节点建立长连接(只有master可以写消息)
3)broker:mq本身,负责收发、持久化消息
4)consumer:消费者,通过nameserver获取topic信息,连接上对的broker消费消息。
因为master和slave都可以读消息,所以consumer和两者都会建立连接
3、broker中消息被消费后,消息会立即删除吗
不会,消息会持久化在commitlog里,每个connsumer会记录当前消费的offset
4、消息什么时候删除
- 检查这个文件最后访问时间
- 判断是否大于过期时间
- 指定时间删除,默认凌晨4点
1 /** 2 * {@link org.apache.rocketmq.store.DefaultMessageStore.CleanCommitLogService#isTimeToDelete()} 3 */ 4 private boolean isTimeToDelete() { 5 // when = "04"; 6 String when = DefaultMessageStore.this.getMessageStoreConfig().getDeleteWhen(); 7 // 是04点,就返回true 8 if (UtilAll.isItTimeToDo(when)) { 9 return true; 10 } 11 // 不是04点,返回false 12 return false; 13 } 14 15 /** 16 * {@link org.apache.rocketmq.store.DefaultMessageStore.CleanCommitLogService#deleteExpiredFiles()} 17 */ 18 private void deleteExpiredFiles() { 19 // isTimeToDelete()这个方法是判断是不是凌晨四点,是的话就执行删除逻辑。 20 if (isTimeToDelete()) { 21 // 默认是72,但是broker配置文件默认改成了48,所以新版本都是48。 22 long fileReservedTime = 48 * 60 * 60 * 1000; 23 deleteCount = DefaultMessageStore.this.commitLog.deleteExpiredFile(72 * 60 * 60 * 1000, xx, xx, xx); 24 } 25 } 26 27 /** 28 * {@link org.apache.rocketmq.store.CommitLog#deleteExpiredFile()} 29 */ 30 public int deleteExpiredFile(xxx) { 31 // 这个方法的主逻辑就是遍历查找最后更改时间+过期时间,小于当前系统时间的话就删了(也就是小于48小时)。 32 return this.mappedFileQueue.deleteExpiredFileByTime(72 * 60 * 60 * 1000, xx, xx, xx); 33 }
5、消费模式有哪些
1)集群模式:一条消息只会被同一个group里的一个consumer消费;
多个group订阅topic时,每个group会有一个consumer消费到消息
2)广播模式:所有订阅了topic的group下的所有consumer都会消费到消息
6、消费消息是pull还是push
使用的pull
使用pull模式,消费者能更好的控制消费节奏。
如果使用push模式会导致消息push过快而消费速度慢,导致消息在消费者中堆积确无法被其他消费者消费的情况。
7、负载均衡
1)producer端
通过一定策略将数据发送到不同borker里,来实现负载均衡
策略:
1.1)如果不设置策略
第一步:获取一个随机数
第二步:轮询每个queue找到可用的
第三步:如果全部不可用,开启容错时选择一个相对较好的queue
不开启容错则随机选择一个queue
1.3)SelectMessageQueueByHash,通过hash
1.4)SelectMessageQueueByRandom
1.5)也可以自行实现MessageQueueSelector接口中的select方法
(比如订单可以用订单号hash来确定broker,使一个订单号的消息都在同一台broker)
1 MessageQueue select(final List<MessageQueue> mqs, final Message msg, final Object arg);
2)consumer端
策略:
1)默认采用平均分配方法来实现负载均衡
如果consumer个数和queue数不对等时:
consumer个数比queue个数多,多个consumer消费一个queue
consumer个数和queue个数一样,一个consumer消费一个queue
consumer个数比queue个数少,一个consumer消费多个queue
2)AllocateMessageQueueConsistentHash:一致性哈希
何时reblance:
1)当一个consumer宕机最多20秒执行reblance,新consumer重新消费
2)当有新consumer接入时,立即执行reblance。
8、重复消费
正常情况下消息消费完后,consumer会发生ack,通知broker将消息从queue中剔除
当意外原因导致broker没有收到ack时,broker会认为消费没有被消费于是重新再把消息投送给consumer
解决方案:
消息消费前,将消息主键在带有唯一约束性的字段中insert
9、如何保证消息顺序消费
1)同一个queue:消息最终会放在queue里,一个queue是FIFO的,但是多个queue是无法保证消息顺序的
所以方案就是将要顺序消费的消息存入到一个queue中即可(实现MessageQueueSelector的select方法)
2)消费者单线程
3)生产者单线程
10、消息实体转byte[]
1 public BaseMessage(BaseMqEntity dto, String topic, String tag) { 2 if (dto != null) { 3 this.setBody(JSONObject.toJSONBytes(dto, new SerializerFeature[0])); 4 } 5 6 this.setTopic(topic); 7 this.setTag(tag); 8 }
11、如何保证消息可靠
1)producer端:可以采用同步发生方式、重试机制
2)consumer端:ack确认、重试机制
3)broker端:1、修改刷盘策略为同步。
默认异步刷盘:当borker收到消息时会存入cache并通知producer已经存储成功,
而后异步将cache数据持久化到硬盘。
2、集群部署主从模式高可用
12、消息持久化
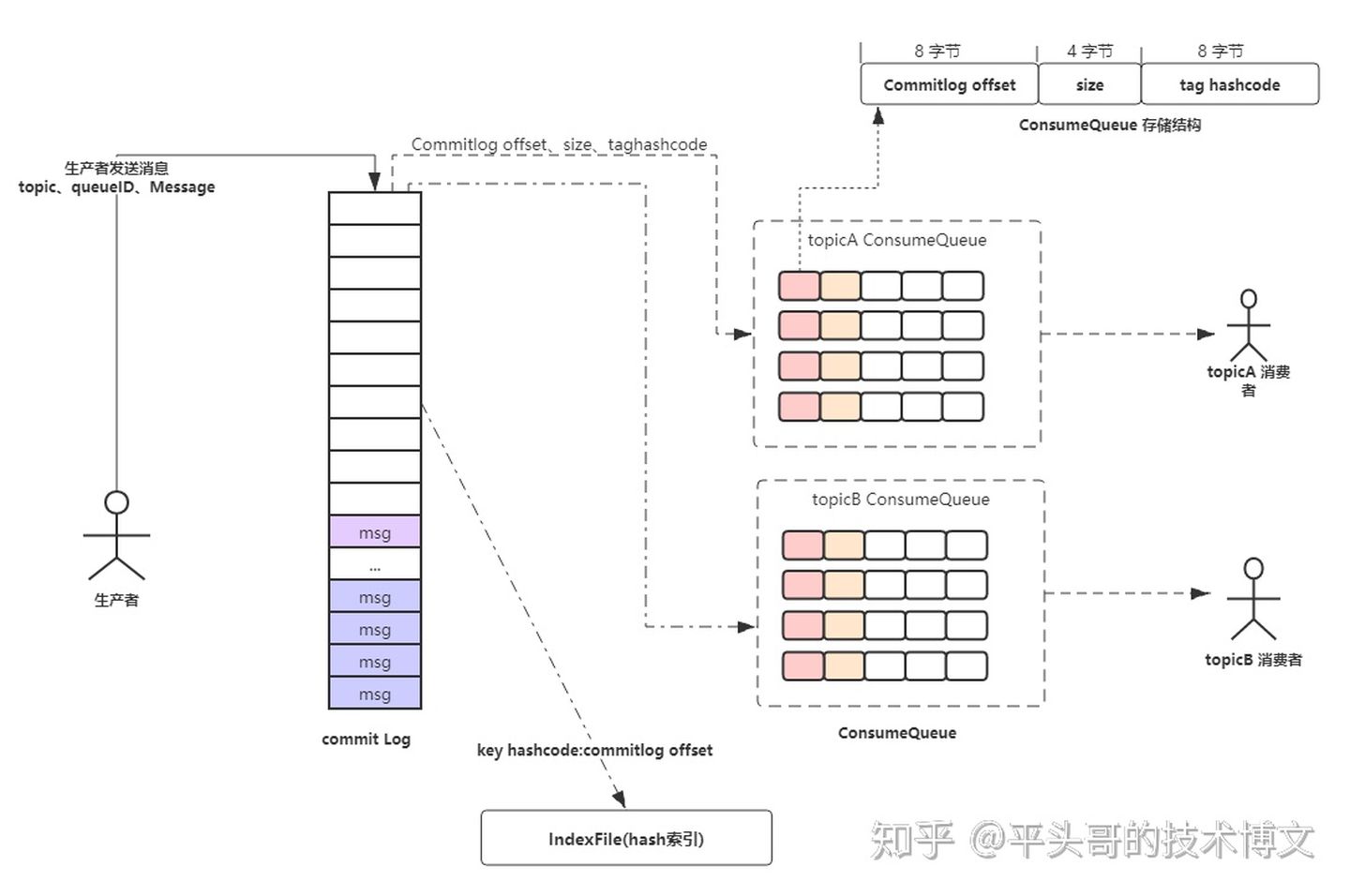
commitLog:消息会顺序写入磁盘文件commitLog中,实际存储消息的文件
consumerQueue:producer生成完消息后会先进入consumerQueue。
消费消息时消费者只能订阅一个topic,
但是一个topic在commitLog中不可能是连续的 这样查询消息就会变慢,
为了解决这个问题引入了consumerQueue,里面只存储了对应topic的消息,
consumer只需要去取consumerQueue里的消息即可。
刷盘模式:
异步刷盘模式则直接返回成功,当数据量累积到一定时会写入commitLog
同步刷屏模式则直接将数据写入commitLog
indexFile:索引文件,记录的消息key和offset
13、事务消息
当发送mq后事务回滚了,这时需要使用事务消息回滚mq。
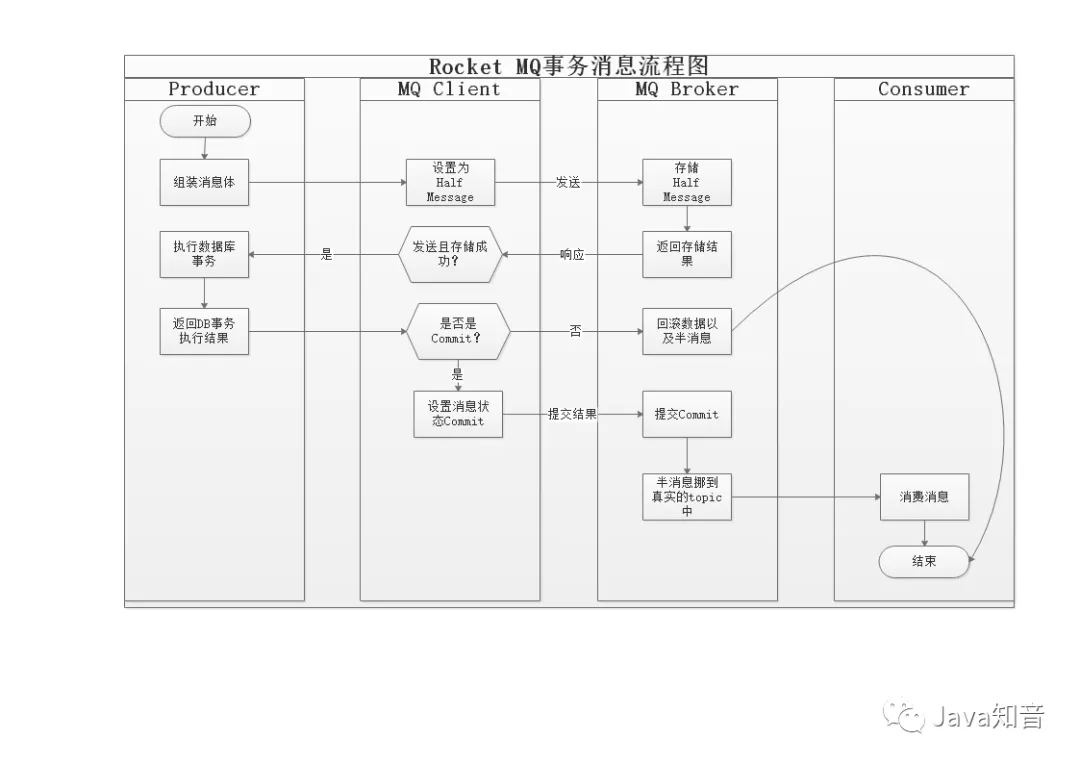
过程:
1)生产者将Half Message发生给broker
2)执行本地事务
3)执行结果返回commit,则发生mq到queue供消费结束
返回rollback,则删除之前到Half Message结束
返回unknow,则启动主动查询
4)主动查询结果返回commit,则发送mq到queue供消费结束
返回rollback,则删除之前的Half Message结束
返回unknow,则继续主动查询
实现:
使用TransactionMQProducer
设置TransactionCheckListener,实现checkLocalTransactionState方法
1 public static void main(String[] args) { 2 TransactionMQProducer producer = new TransactionMQProducer(); 3 producer.setNamesrvAddr(""); 4 producer.setTransactionCheckListener(new TransactionCheckListener() { 5 @Override 6 public LocalTransactionState checkLocalTransactionState(MessageExt msg) { 7 return LocalTransactionState.COMMIT_MESSAGE; 8 } 9 }); 10 }
14、实操:目前是接入阿里云的ons(Open Notification Service)
15、为什么不用zookeeper而是自己写一套nameserver:
1)zookeeper是满足cp的,也就是无法保证服务高可用。
2)zookeeper的写是不能扩展的,而nameserver可以通过增加机器扩展,每个节点都可写无主备
3)zookeeper整体太笨重,例如:zookeeper一个功能是选举出master,
而rocketMq是通过配置设定主从节点,也就没必要用选举功能
4)zookeeper每个节点同步数据,
nameserver互相之间不通信由broker、produce、consumer自己上报给每一个nameserver节点
参考文章:https://www.cnblogs.com/javazhiyin/p/13327925.html
posted on 2021-08-30 15:02 Iversonstear 阅读(223) 评论(0) 编辑 收藏 举报

