面试十三、mysql
1、存储引擎
MyISAM:mysql5.1之前作为默认引擎
1)不支持事务,不支持外键
2)非聚集索引:数据文件和索引分开存放,索引存放的是数据文件的地址指针。
主键和辅助索引是独立的,两者没有本质区别,所以主键也是非必需的。
3)保存表的具体行树,所以select count(*)不带条件只需要把该值读出来即可,速度很快
4)只支持表级锁,curd操作都会对整个表加锁
5)查询效率高,因为索引直接指向数据
6)支付fulltext类型的全文搜索
InnoDB:新版本默认引擎
1)支持事务,支持外键
2)聚集索引:数据文件存放在主键索引的叶子节点上,因此必须要有主键。
且因为主键和数据文件放一起,通过主键索引效率很高。
但是辅助索引要查询两次,先通过辅助索引查到主键,再通过主键索引查数据,
所以主键不应设置过大,否则会导致其他索引也很大。
3)不保存表的具体行数,所有select count(*)不带条件需要全表扫描
4)支持行级锁,增加了并发能力。因为行锁是实现在索引上的,
所有当不能确定扫描范围的情况时(即无法命中索引),将退化为对整张表加锁。
5)查询效率不高,因为存在二次查询
6)不支持fulltext类型的全文搜索,5.7后支持
2、事务隔离级别
事务导致的问题:
1)脏读:事务1修改数据a为b,事务2读到了b,但是事务a因为错误回滚为a,
这时事务2读到的数据b,就是脏数据
2)不可重复读:事务1在查询数据是需要多次读取数据而且需要保证每次读到的数据一致,
但是事务2将数据a改为b,事务1再查询时读到了数据b,就是不可重复读
3)幻读:事务1再查询数据时需要多次根据条件查询,第一次查到了5条,
事务2插入了满足条件的一条数据,事务1再查询是查到了6条,就是幻读
不可重复读和幻读区别在于:不可重复读是对于数据记录的值不同,幻读是对于数据记录的数量不同
read uncommited:所有事务可读到其他事务未提交的数据,脏读
read commited:一个事务只能读到其他事务已提交的数据,有可能同一select结果不同。不可重复读
repeatable read:可重复读,数据库默认事务。确保同一个事务在select时看到相同的数据。可重复读
serializabel:串行事务,确保事务不会发生冲突。有可能会导致大量超时和锁竞争。可重复读
2、索引
2.1、索引类型:
1)normal:普通索引
2)unique:唯一索引,表里只能有一条
3)fulltext:全文索引,适合长文本
4)spatial:空间索引,没用过
hash索引:基于hash表,索引效率高。只支持等值查询不提供范围查询,不支持排序。
BTree索引:基于B+树,相对索引效率低。支持范围查询,支持排序
为什么使用B+树而不是B树(请看树文章)
索引失效:
1)or条件,保证条件里的列都有索引,索引才会生效
2)like查询"%"开头,索引会失效
3)列类型是字符串,如果不用单引号可能出现数据类型隐式转化为int类型,索引会失效
4)索引不能存null,条件中使用is null不会走索引,索引会失效
5)条件中使用!= <>,索引失效
联合索引:
1)最左匹配原则
例如:索引为idx_a_b_c,条件是where a = 1 and c = 3 and b = 2
sql会先优化为最佳执行where a = 1 and b = 2 and c = 3
如果b没有查到数据则c不走索引
2)最左匹配原则原理:
构建一颗B+树只能根据一个值来构建,以下面index_a_b_c为例:
非叶子节点存的是第一个关键字的索引a,叶子节点存的是三个关键字的数据。
可以看出a是有序的(树)而bc是无序的,但是当a确定时b是有序的c是无序的
当b确定时c时有序的。
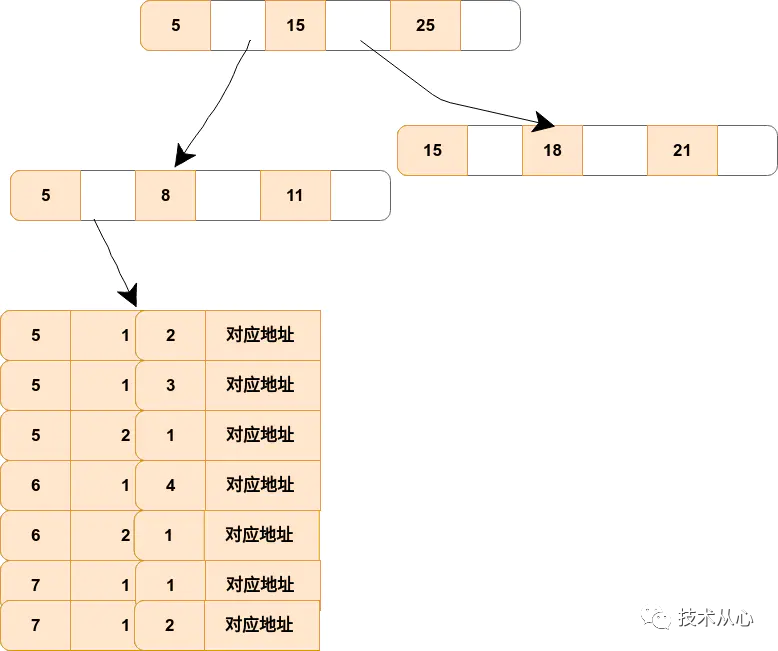
联合索引失效:
1)where a = 1 and b = 2 and c = 3,b=2没有数据,索引失效
2)where a = 1 and b > 2 and c = 3,b>2查到的是一个范围,里面的c无序,索引失效
3)where a = 1 and b != 2 and b = 3,b!=2查到的是一个范围,里面的c无序,索引失效
3、连表查询
1 // test1表 2 CREATE TABLE `test1` ( 3 `id` bigint(20) NOT NULL, 4 `name` varchar(255) CHARACTER SET utf8mb4 NOT NULL DEFAULT '', 5 PRIMARY KEY (`id`) 6 ) ENGINE=InnoDB DEFAULT CHARSET=utf8; 7 INSERT INTO `dev_obp_order`.`test1`(`id`, `name`) VALUES (1, '张'); 8 INSERT INTO `dev_obp_order`.`test1`(`id`, `name`) VALUES (2, '李'); 9 INSERT INTO `dev_obp_order`.`test1`(`id`, `name`) VALUES (3, '王'); 10 INSERT INTO `dev_obp_order`.`test1`(`id`, `name`) VALUES (4, '赵'); 11 12 // test2表 13 CREATE TABLE `test2` ( 14 `id` bigint(20) NOT NULL, 15 `aid` bigint(20) NOT NULL DEFAULT '0', 16 `name` varchar(255) CHARACTER SET utf8mb4 NOT NULL DEFAULT '', 17 PRIMARY KEY (`id`) 18 ) ENGINE=InnoDB DEFAULT CHARSET=utf8; 19 INSERT INTO `dev_obp_order`.`test2`(`id`, `aid`, `name`) VALUES (1, 1, '一'); 20 INSERT INTO `dev_obp_order`.`test2`(`id`, `aid`, `name`) VALUES (2, 1, '二'); 21 INSERT INTO `dev_obp_order`.`test2`(`id`, `aid`, `name`) VALUES (3, 2, '一'); 22 INSERT INTO `dev_obp_order`.`test2`(`id`, `aid`, `name`) VALUES (4, 5, '一');
表数据
// test1 id name 1 张 2 李 3 王 4 赵 // test2 id aid name 1 1 一 2 1 二 3 2 一 4 5 一
inner join:返回test1和test2都有的数据(交集)
1 SELECT a.*, b.* from test1 a INNER JOIN test2 b on (a.id = b.aid); 2 3 结果: 4 1 张 1 1 一 5 1 张 2 1 二 6 2 李 3 2 一
left join:以左表数据为基础,左表有的数据会全部展示,右表数据如果满足on条件则展示,不满足则null
SELECT a.*, b.* from test1 a LEFT JOIN test2 b on (a.id = b.aid); 结果: 1 张 1 1 一 1 张 2 1 二 2 李 3 2 一 3 王 4 赵
right join:以右表数据为基础,右表有的数据会全部展示,左表数据如果满足on条件则展示,不满足则null
1 SELECT a.*, b.* from test1 a RIGHT JOIN test2 b on (a.id = b.aid); 2 3 结果: 4 1 张 1 1 一 5 1 张 2 1 二 6 2 李 3 2 一 7 4 5 一
3、三范式
1)每一列要保持原子性不可再分割,同一列不可有多个值
2)有主键,非主键字段必须依赖于主键
3)非主键字段之间不能有依赖
4、explain
调优
5、回表查询
当要查的数据刚好是索引的列(因为mysql的索引是按照索引列的值排序的)或者通过
一次索引就能查询到数据就不用回表。
如果查询的数据不是索引列,就要从表中查列的信息,这就叫回表。
例如:没有使用主键时,需要先根据其他索引查询到主键,再通过主键查询到数据,就是回表。
posted on 2021-08-26 23:40 Iversonstear 阅读(44) 评论(0) 编辑 收藏 举报

