

Spring的bean加载以及JVM类加载过程
背景:
在使用谷歌开源的本地缓存解决经常查询数据库导致的查询效率低下,将从数据库查询好的数据放入到缓存中,然后设计过期时间,接着设计一个get方法缓存汇总获取数据,进一步将整个流程封装成一个CacheSerice,然后在Controller层调用这个Service,从Service中获取数据。
问题:
需要对CacheService进行初始化,设计的初衷是:当Service的bean被加载之后,其中的缓存数据就已经被初始化(即利用数据库查询Service获取数据,并塞入缓存),而这个初始化的过程被我放到了CacheService类的构造函数中。结果在发布的时候就一直报空指针。
@Service("test")
public class Test implements IAppnameCache {
@Autowired
IAppnameService iAppnameService;
public Test(){
iAppnameService.queryAppname();// 抛出空指针
}
@Override
public List<AppnameViewModel> get(String app){
return iAppnameService.queryAppname();
}
}
问题定位:
经过查询日志,发现是CacheService的构造函数在执行的时候发生空指针问题。那么有可能是引入的谷歌开源库的问题有可能不是,采用排除法很快就发现了不是这个库的问题,不含谷歌开源库的测试类采用这种写法也发生了空指针的问题。
问题思考:
既然跟引入的谷歌开源库没有关系,那就说明当CacheService被构造的时候(采用构造函数),里面依赖的其他bean还没有被构造出来,因而导致空指针问题。针对这个问题进一步对Spring的bean构造过程进行研究。
Spring的bean加载过程:
bean的主要生成过程如下:
1,AbstractBeanFactory.getBean(String) 2,AbstractBeanFactory.doGetBean(String, Class<T>, Object[], boolean) 3,DefaultSingletonBeanRegistry.getSingleton(String) 4,AbstractAutowireCapableBeanFactory.createBean(String, RootBeanDefinition, Object[]) 5,AbstractAutowireCapableBeanFactory.doCreateBean(String, RootBeanDefinition, Object[]) 6,AbstractAutowireCapableBeanFactory.createBeanInstance(String, RootBeanDefinition, Object[]) 7,AbstractAutowireCapableBeanFactory.instantiateBean(String, RootBeanDefinition) 8,SimpleInstantiationStrategy.instantiate(RootBeanDefinition, String, BeanFactory) 9, AbstractAutowireCapableBeanFactory.populateBean(String, RootBeanDefinition, BeanWrapper) 10,AbstractAutowireCapableBeanFactory.initializeBean(String, Object, RootBeanDefinition) 11,AbstractAutowireCapableBeanFactory.invokeAwareMethods(String, Object) 12,AbstractAutowireCapableBeanFactory.applyBeanPostProcessorsBeforeInitialization(Object, String) 13,AbstractAutowireCapableBeanFactory.invokeInitMethods(String, Object, RootBeanDefinition) 14,AbstractAutowireCapableBeanFactory.applyBeanPostProcessorsAfterInitialization(Object, String)
(1)在通过BeanFactory获取bean实例对象的时候,会先去单例集合中找是否已经创建了对应的实例,如果有就直接返回了,这里是第一次获取,所以没有拿到;
(2)然后AbastractBeanFactory会根据bean的名称获取对应的BeanDefinition对象,BeanDefinition对象代表了对应类的各种元数据,所以根据BeanDefinition对象就可以判断是否是单例,是否依赖其他对象,如果依赖了其他对象那么先生成其依赖,这里是递归调用。
在步骤7之前都是为了生成bean做准备,真正生成bean是在AbstractAutowireCapableBeanFactory的instantiateBean方法:
protected BeanWrapper instantiateBean(final String beanName, final RootBeanDefinition mbd) {
try {
Object beanInstance;
final BeanFactory parent = this;
if (System.getSecurityManager() != null) {
beanInstance = AccessController.doPrivileged(new PrivilegedAction<Object>() {
@Override
public Object run() {
return getInstantiationStrategy().instantiate(mbd, beanName, parent);
}
}, getAccessControlContext());
}
else {
beanInstance = getInstantiationStrategy().instantiate(mbd, beanName, parent);
}
BeanWrapper bw = new BeanWrapperImpl(beanInstance);
initBeanWrapper(bw);
return bw;
}
catch (Throwable ex) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Instantiation of bean failed", ex);
}
}
-----------------------------------------------------------------------------------------------------
@Override
public Object instantiate(RootBeanDefinition bd, String beanName, BeanFactory owner) {
// Don't override the class with CGLIB if no overrides.
if (bd.getMethodOverrides().isEmpty()) {
Constructor<?> constructorToUse;
synchronized (bd.constructorArgumentLock) {
//这里一堆安全检查
}
//默认使用构造函数利用反射实例化bean
return BeanUtils.instantiateClass(constructorToUse);
}
else {
// Must generate CGLIB subclass.
return instantiateWithMethodInjection(bd, beanName, owner);
}
} 可以看到实际上bean的生成是直接使用BeanUtils工具类通过反射获取类的实例。
而反射获取类实例的过程如下:
Class<?> cls = Class.forName("cn.mldn.demo.Person"); // 取得Class对象
Object obj = cls.newInstance() //反射实例化对象
Constructor<?> cons = cls.getConstructor(String.class, int.class);//获得构造方法
Method m3 = cls.getDeclaredMethod("getName"); //获得get方法
Field nameField = cls.getDeclaredField("name"); // 获得name属性
同时在JVM进行类加载的时,再进行到初始化这一步骤的时候,首先会调用默认构造器进行变量初始化:
- 类构造器<clinit>()方法是由编译器自动收集类中的所有类变量的赋值动作和静态语句块(static块)中的语句合并产生的,编译器收集的顺序是由语句在源文件中出现的顺序所决定的,静态语句块中只能访问到定义在静态语句块之前的变量,定义在它之后的变量,在前面的静态语句快可以赋值,但是不能访问。
- 类构造器<clinit>()方法与类的构造函数(实例构造函数<init>()方法)不同,它不需要显式调用父类构造,虚拟机会保证在子类<clinit>()方法执行之前,父类的<clinit>()方法已经执行完毕。因此在虚拟机中的第一个执行的<clinit>()方法的类肯定是java.lang.Object。
- 由于父类的<clinit>()方法先执行,也就意味着父类中定义的静态语句快要优先于子类的变量赋值操作。
- <clinit>()方法对于类或接口来说并不是必须的,如果一个类中没有静态语句,也没有变量赋值的操作,那么编译器可以不为这个类生成<clinit>()方法。(默认值是内存分配的时候赋予的,与初始化过程无关)
- 接口中不能使用静态语句块,但接口与类不同是,执行接口的<clinit>()方法不需要先执行父接口的<clinit>()方法。只有当父接口中定义的变量被使用时,父接口才会被初始化。另外,接口的实现类在初始化时也一样不会执行接口的<clinit>()方法。
- 虚拟机会保证一个类的<clinit>()方法在多线程环境中被正确加锁和同步,如果多个线程同时去初始化一个类,那么只会有一个线程执行这个类的<clinit>()方法,其他线程都需要阻塞等待,直到活动线程执行<clinit>()方法完毕。如果一个类的<clinit>()方法中有耗时很长的操作,那就可能造成多个进程阻塞。
CacheService类中没有赋值行为,然后则会调用默认的构造函数,所以在CacheService类中,被反射获取构造器的时候会调用明确的构造器。回归到本次的问题,在构造器中使用了其他的bean,而Spring的bean生成其实是没有规律的(也就是依赖的bean还没有被注入),所以抛出空指针的异常。
那么问题来了,Spring说好的有自动检测依赖的功能呢?
请列位看官慢慢往下看,请小生为各位一一分解。
我们把目光往前看,如果在容器中没有拿到目标bean,然后AbastractBeanFactory会根据bean的名称获取对应的BeanDefinition对象,BeanDefinition对象代表了对应类的各种元数据,
// 运行到这里说明bean没有被创建,先获取此bean依赖的bean
String[] dependsOn = mbd.getDependsOn();
if (dependsOn != null) {
for (String dep : dependsOn) {
if (isDependent(beanName, dep)) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Circular depends-on relationship between '" + beanName + "' and '" + dep + "'");
}
registerDependentBean(dep, beanName);
//实例化依赖的bean
getBean(dep);
}
}
可以看到是通过getDependsOn方法获取依赖的bean,而这个过程是通过Setter将CacheService的属性bean进行注入,然后获取bean。那么既然属性注入的时候
IAppnameService就已经完成bean注入了,为何构造器还是抛出了异常呢?原来上述过程注入明确指出的依赖,即在bean的配置中加入depends-on(也支持注解),
如果没有配置,那么CacheService的属性注入是在getbean()完成之后。所以在执行CacheService的构造函数时当然抛出异常啦!那么也就是说Spring的依赖检查其实没有开启的,
是需要手动在配置文件中开启的,在Spring中有四种依赖检查的方式。依赖检查有四种模式:simple,objects,all,none,都通过bean的dependency-check属性进行模式设置。
当然Spring中的加载过程中,其加载过程还是遵循JVM的加载过程。
JVM的主要加载过程
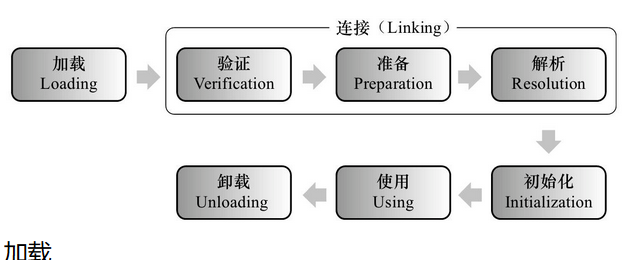
在JVM中是通过类加载器以及类的全限定名来保证类的唯一性的,也就是说如果两个类的路径名称完全一样,但是只要是加载它们的类加载器不一样就可以认为是两个不一样的类。而在JVM中含有如下几种类加载器:
JVM中包括集中类加载器:
1 BootStrapClassLoader 引导类加载器
2 ExtClassLoader 扩展类加载器
3 AppClassLoader 应用类加载器
4 CustomClassLoader 用户自定义类加载器
并且在JVM中使用双亲委派模型进行加载。什么是双亲委派模型呢?就是在2,3,4的类加载器加载类的时候,都会向上调用父类加载器来实现,也就是说最后都是交给BootStrapClassLoader加载器完成加载的。这样做的好处一是因为安全性,因为JVM的类加载过程中有验证这一步骤,会对class文件进行校验,判断是否符合JVM规范。二是因为保证类不会被重复加载,因为在执行new的时候,会首先从元数据区查找类符号,如果没有则会加载相应的文件。所以为了避免在这个过程中重复加载的现象,最终都是通过系统提供的类加载器完成加载。
加载细节:
(未完待续)参考资料:
1. 深入理解JVM虚拟机
2. https://blog.51cto.com/wenshengzhu/1950146
3. https://blog.csdn.net/h12kjgj/article/details/54312766
4. https://www.cnblogs.com/kjitboy/p/12076303.html [Spring Bean的装配方式

