MapReduce流程及Shuffle机制
-
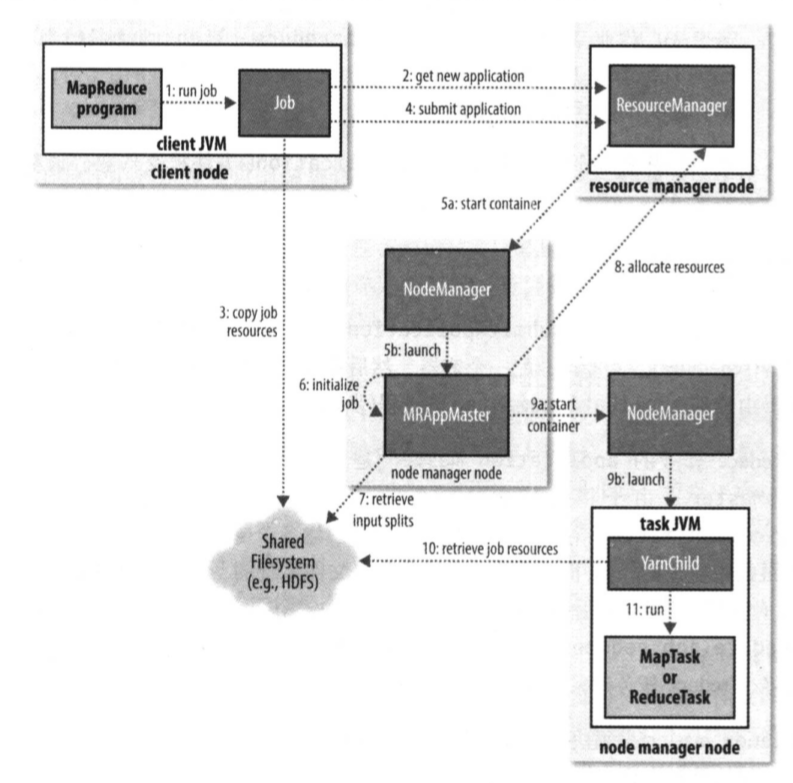
job的submit()方法创建一个Jobsubmmiter实例,调用submitJobInternal()方法。
-
资源管理器收到调用它的submitApplication()消息后,将请求传递给YARN调度器。调度器分配一个容器,然后资源管理器在节点管理器的管理下在容器启动application master的进程。application master接受来自任务的进度和完成报告,保持对作业进度的跟踪来完成对作业的初始化。接下来接受来自共享文件系统 在客户端计算的输入分片,对每一个分片创建一个map任务对象以及多个rudece任务对象(任务id在此时分配)。如果是小作业就在同一个JVM上运行任务(uber任务)。
-
任务分配:如果不是小作业,application master会为作业中的map任务和reduce任务向资源管理器请求容器。请求为任务指定内存需求和cpu数。
-
任务执行:分配容器后,application master通过与节点管理器通信来启动容器。该任务由主类为YarnChild的一个java应用程序执行。它在运行任务之前,先将资源本地化(配置 jar文件 所有来自分布式缓存的文件),最后运行map或reduce任务。
-
作业完成:application maste收到作业最后一个任务的完成消息后,把作业状态设为“成功”。Job轮询状态后打印消息由waitForCompletion()返回。最后作业完成时,application master和任务容器会清理工作状态,OutputCommitter 的commitJob()方法被调用。作业信息由作业历史服务器存档。
Shuffle
-
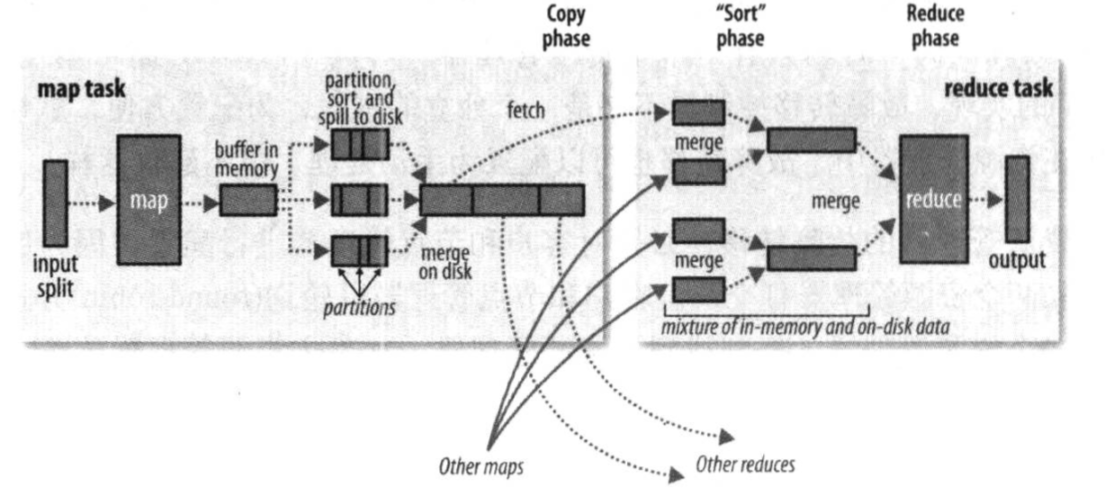
MapTask 收集我们的 map()方法输出的 kv 对,放到内存缓冲区中
-
从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件
-
多个溢出文件会被合并成大的溢出文件
-
在溢出过程及合并的过程中,都要调用 Partitioner 进行分区和针对 key 进行排序
-
ReduceTask 根据自己的分区号,去各个 MapTask 机器上取相应的结果分区数据
-
ReduceTask 会抓取到同一个分区的来自不同 MapTask 的结果文件,ReduceTask 会将这些文件再进行合并(归并排序)
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号