
Spark Streaming流式处理
Spark Streaming概述
-
-
它可以非常容易的构建一个可扩展、具有容错机制的流式应用。
-
对接很多的外部数据源
-
Kafka、Flume、Twitter、ZeroMQ和简单的TCP套接字(socket)等等
-
-
-
可以像编写离线批处理一样去编写流式程序,支持java/scala/python语言
-
-
2、容错性
-
SparkStreaming在没有额外代码和配置的情况下可以恢复丢失的工作。
-
-
3、可以融合到spark体系
-
流式处理与批处理和交互式查询相结合。
-
-
Spark Streaming 是基于spark的流式批处理引擎,其基本原理是把输入数据以某一时间间隔批量的处理,当批处理间隔缩短到秒级时,便可以用于处理实时数据流。
-
-
2、Spark Streaming计算流程
-
Dstream是sparkStreaming底层抽象,它封装了一个个批次的数据,针对于Dstream做相应操作,这个时候这些方法就作用在Dstream中RDD
-
-
3、SparkStreaming容错性
-
依赖RDD的血统+数据源端的安全性
-
-
4、SparkStreaming实时性
-
SparkStreaming实时性不是特别高,它是以某一时间批次进行处理,批次最小时间0.5s - 2s
-
其最小的Batch Size的选取在0.5~2秒钟之间(Storm目前最小的延迟是100ms左右),所以Spark Streaming能够满足除对实时性要求非常高(如高频实时交易)之外的所有流式准实时计算场景。
-
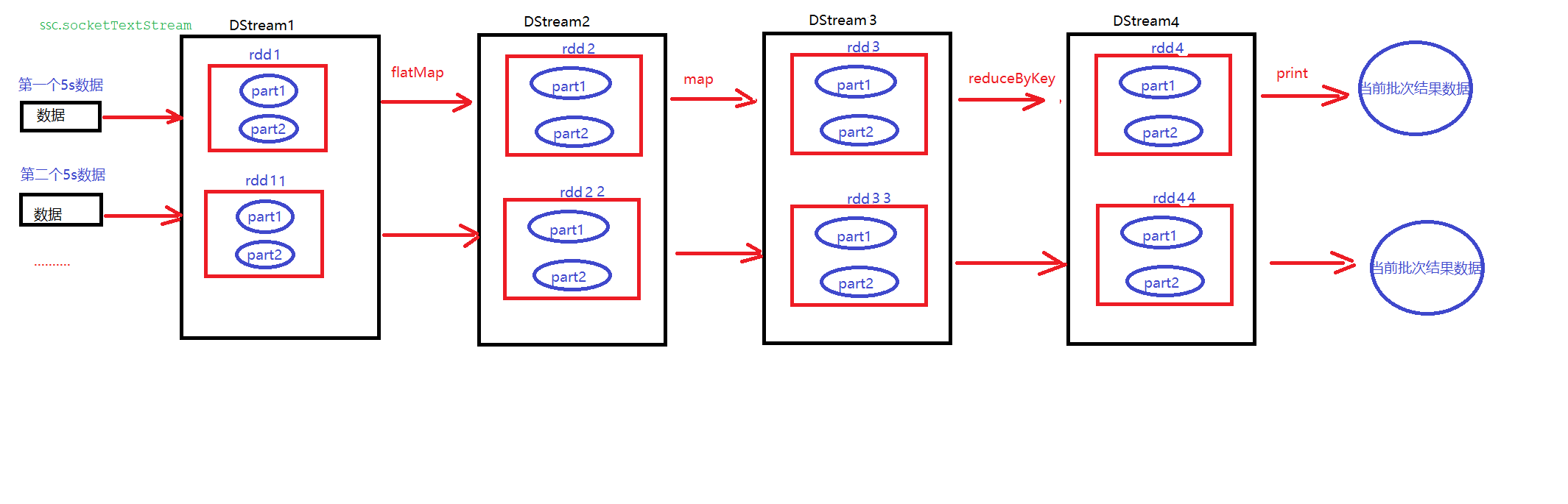
DStream相关操作
DStream上的操作与RDD的类似,分为Transformations(转换)和Output Operations(输出)两种,此外转换操作中还有一些比较特殊的操作,如:updateStateByKey()、transform()以及各种Window相关的操作
transformation
它是一个转换,它把一个Dstream转换生成一个Dstream,它也不会触发任务真正运行
|
Transformation |
Meaning |
|
map(func) |
对DStream中的各个元素进行func函数操作,然后返回一个新的DStream |
|
flatMap(func) |
与map方法类似,只不过各个输入项可以被输出为零个或多个输出项 |
|
filter(func) |
过滤出所有函数func返回值为true的DStream元素并返回一个新的DStream |
|
repartition(numPartitions) |
增加或减少DStream中的分区数,从而改变DStream的并行度 |
|
union(otherStream) |
将源DStream和输入参数为otherDStream的元素合并,并返回一个新的DStream. |
|
count() |
通过对DStream中的各个RDD中的元素进行计数,然后返回只有一个元素的RDD构成的DStream |
|
reduce(func) |
对源DStream中的各个RDD中的元素利用func进行聚合操作,然后返回只有一个元素的RDD构成的新的DStream. |
|
countByValue() |
对于元素类型为K的DStream,返回一个元素为(K,Long)键值对形式的新的DStream,Long对应的值为源DStream中各个RDD的key出现的次数 |
|
reduceByKey(func, [numTasks]) |
利用func函数对源DStream中的key进行聚合操作,然后返回新的(K,V)对构成的DStream |
|
join(otherStream, [numTasks]) |
输入为(K,V)、(K,W)类型的DStream,返回一个新的(K,(V,W))类型的DStream |
|
cogroup(otherStream, [numTasks]) |
输入为(K,V)、(K,W)类型的DStream,返回一个新的 (K, Seq[V], Seq[W]) 元组类型的DStream |
|
transform(func) |
通过RDD-to-RDD函数作用于DStream中的各个RDD,可以是任意的RDD操作,从而返回一个新的RDD |
|
updateStateByKey(func) |
根据key的之前状态值和key的新值,对key进行更新,返回一个新状态的DStream |
特殊的Transformations
(1)UpdateStateByKey Operation
UpdateStateByKey用于记录历史记录,保存上次的状态
(2)Window Operations(开窗函数)
滑动窗口转换操作:
滑动窗口转换操作的计算过程如下图所示,我们可以事先设定一个滑动窗口的长度(也就是窗口的持续时间),并且设定滑动窗口的时间间隔(每隔多长时间执行一次计算),然后,就可以让窗口按照指定时间间隔在源DStream上滑动,每次窗口停放的位置上,都会有一部分DStream被框入窗口内,形成一个小段的DStream,这时,就可以启动对这个小段DStream的计算。

Output Operations
Output Operations可以将DStream的数据输出到外部的数据库或文件系统,当某个Output Operations被调用时(与RDD的Action相同),spark streaming程序才会开始真正的计算过程。
|
Output Operation |
Meaning |
|
print() |
打印到控制台 |
|
saveAsTextFiles(prefix, [suffix]) |
保存流的内容为文本文件,文件名为 "prefix-TIME_IN_MS[.suffix]". |
|
saveAsObjectFiles(prefix, [suffix]) |
保存流的内容为SequenceFile,文件名为 "prefix-TIME_IN_MS[.suffix]". |
|
saveAsHadoopFiles(prefix, [suffix]) |
保存流的内容为hadoop文件,文件名为 "prefix-TIME_IN_MS[.suffix]". |
|
foreachRDD(func) |
对Dstream里面的每个RDD执行func |
DStream操作实战
一、
SparkStreaming接受socket数据,实现单词计数WordCount
(1)安装并启动生产者
首先在linux服务器上用YUM安装nc工具,nc命令是netcat命令的简称,它是用来设置路由器。我们可以利用它向某个端口发送数据。
yum install -y nc
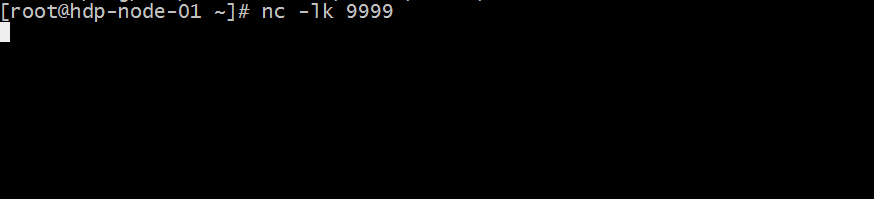
(2)通过netcat工具向指定的端口发送数据
nc -lk 9999
(3)编写Spark Streaming程序
导入依赖
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.11</artifactId> <version>2.0.2</version> </dependency>
代码开发

import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream} import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.streaming.{Seconds, StreamingContext} //todo:需求:利用sparkStreaming接受socket数据,实现单词统计WordCount object SparkStreamingSocket { def main(args: Array[String]): Unit = { //1、创建SparkConf val sparkConf: SparkConf = new SparkConf().setAppName("SparkStreamingSocket").setMaster("local[2]") //2、创建SparkContext val sc = new SparkContext(sparkConf) sc.setLogLevel("WARN") //3、创建StreamingContext对象,需要2个参数,第一是SparkContext,第二个表示批处理时间间隔 val ssc = new StreamingContext(sc,Seconds(5)) //4、通过StreamingContext对象来接受socket数据 val socketTextStream: ReceiverInputDStream[String] = ssc.socketTextStream("192.168.200.100",9999) //5、切分每一行 val wordsDstream: DStream[String] = socketTextStream.flatMap(_.split(" ")) //6、每一个单词计为1 val wordAndOneDstream: DStream[(String, Int)] = wordsDstream.map((_,1)) //7、相同单词出现的次数累加 val result: DStream[(String, Int)] = wordAndOneDstream.reduceByKey(_+_) //8、打印结果 result.print() //9、开启流式计算 ssc.start() //该方法为一直阻塞在这里,等待程序结束 ssc.awaitTermination() } }
运行程序
在liunx中输入数据
![]()
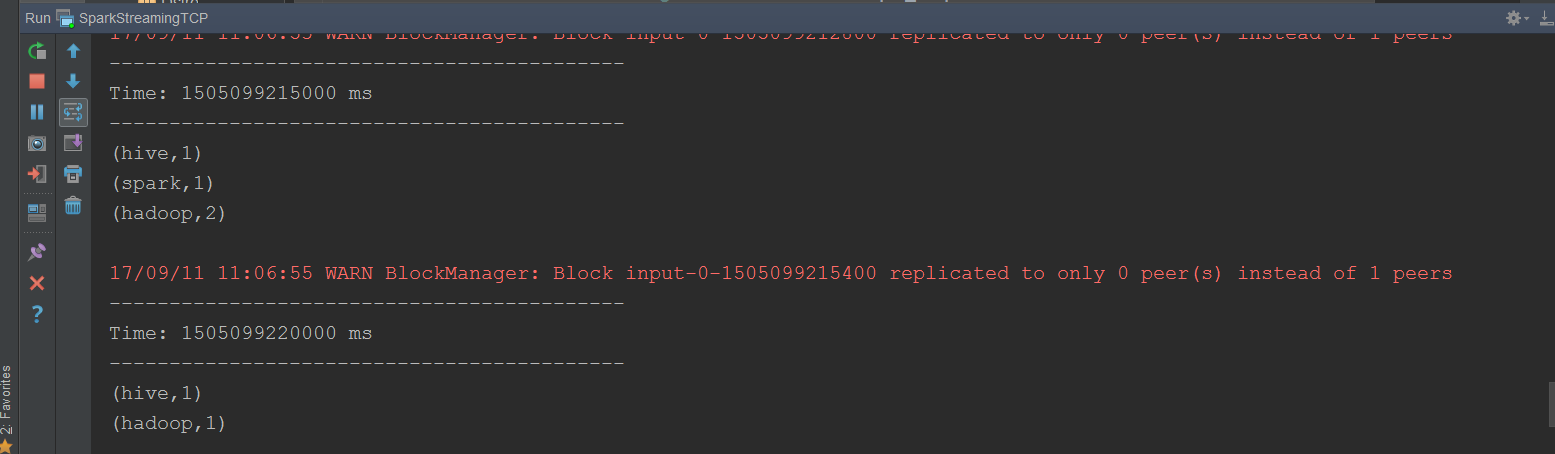
二、
SparkStreaming接受socket数据,实现所有批次单词计数结果累加
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream} import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.{SparkConf, SparkContext} //todo:需求:利用sparkStreaming接受socket数据,实现所有批次单词统计结果累加 object SparkStreamingSocketTotal { /** * (hadoop,1) (hadoop,1) (hadoop,1) (hadoop,1) * @param currentValues 它表示在当前批次中相同单词出现所有的1,把这所有的1封装在一个list集合中 (hadoop,List(1,1,1,1)) * @param historyValues 它表示在之前所有批次中每一个单词出现的次数 * @return */ def updateFunc(currentValues:Seq[Int], historyValues:Option[Int]):Option[Int] = { val newValue: Int = currentValues.sum + historyValues.getOrElse(0) Some(newValue) } def main(args: Array[String]): Unit = { //1、创建SparkConf val sparkConf: SparkConf = new SparkConf().setAppName("SparkStreamingSocketTotal").setMaster("local[2]") //2、创建SparkContext val sc = new SparkContext(sparkConf) sc.setLogLevel("WARN") //3、创建StreamingContext对象 val ssc = new StreamingContext(sc,Seconds(5)) //需要设置一个checkpoint,由于保存每一个批次中间结果数据 ssc.checkpoint("./socket") //4、接受socket是数据 val socketTextStream: ReceiverInputDStream[String] = ssc.socketTextStream("192.168.200.100",9999) //5、切分每一行 val words: DStream[String] = socketTextStream.flatMap(_.split(" ")) //6、每个单词计为1 val wordAndOne: DStream[(String, Int)] = words.map((_,1)) //7、相同单词所有批次结果累加 val result: DStream[(String, Int)] = wordAndOne.updateStateByKey(updateFunc) //8、打印结果 result.print() //9、开启流式计算 ssc.start() //该方法为一直阻塞在这里,等待程序结束 ssc.awaitTermination() } }
三、
SparkStreaming开窗函数reduceByKeyAndWindow,实现单词计数
import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream} //todo:需求:利用sparkStreaming接受socket数据,使用reduceByKeyAndWindow开窗函数实现单词统计 object SparkStreamingSocketWindow { def main(args: Array[String]): Unit = { //1、创建SparkConf val sparkConf: SparkConf = new SparkConf().setAppName("SparkStreamingSocketWindow").setMaster("local[2]") //2、创建SparkContext val sc = new SparkContext(sparkConf) sc.setLogLevel("WARN") //3、创建StreamingContext对象,需要2个参数,第一是SparkContext,第二个表示批处理时间间隔 val ssc = new StreamingContext(sc,Seconds(5)) //4、通过StreamingContext对象来接受socket数据 val socketTextStream: ReceiverInputDStream[String] = ssc.socketTextStream("192.168.200.100",9999) //5、切分每一行 val wordsDstream: DStream[String] = socketTextStream.flatMap(_.split(" ")) //6、每一个单词计为1 val wordAndOneDstream: DStream[(String, Int)] = wordsDstream.map((_,1)) //7、相同单词出现的次数累加 //方法中需要三个参数 //reduceFunc:第一个就是一个函数 //windowDuration:第二个表示窗口长度 //slideDuration :第三个表示滑动窗口的时间间隔,也就意味着每隔多久计算一次 val result: DStream[(String, Int)] = wordAndOneDstream.reduceByKeyAndWindow((x:Int,y:Int)=>x+y,Seconds(10),Seconds(5)) //8、打印结果 result.print() //9、开启流式计算 ssc.start() //该方法为一直阻塞在这里,等待程序结束 ssc.awaitTermination() } }
四、
SparkStreaming开窗函数统计一定时间内的热门词汇
-
实现一个Dstream转换成一个新的Dstream,当前这个方法需要一个函数,这个函数的输入参数是前面Dstream中的rdd,函数的返回值是一个新的RDD
import org.apache.spark.rdd.RDD import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream} import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.{SparkConf, SparkContext} //todo:需求:利用sparkStreaming接受socket数据,通过reduceByKeyAndWindow实现一定时间内热门词汇 object SparkStreamingSocketWindowHotWords { def main(args: Array[String]): Unit = { //1、创建SparkConf val sparkConf: SparkConf = new SparkConf().setAppName("SparkStreamingSocketWindowHotWords").setMaster("local[2]") //2、创建SparkContext val sc = new SparkContext(sparkConf) sc.setLogLevel("WARN") //3、创建StreamingContext val ssc = new StreamingContext(sc,Seconds(5)) //4、接受socket数据 val socketTextStream: ReceiverInputDStream[String] = ssc.socketTextStream("192.168.200.100",9999) //5、切分每一行获取所有的单词 val words: DStream[String] = socketTextStream.flatMap(_.split(" ")) //6、每个单词计为1 val wordAndOne: DStream[(String, Int)] = words.map((_,1)) //7、相同单词出现次数累加 val result: DStream[(String, Int)] = wordAndOne.reduceByKeyAndWindow((x:Int,y:Int)=>x+y,Seconds(10),Seconds(10)) //8、按照单词出现的次数降序排序 val sortedDstream: DStream[(String, Int)] = result.transform(rdd => { //按照单词次数降序 val sortedRDD: RDD[(String, Int)] = rdd.sortBy(_._2, false) //取出出现次数最多的前3位 val top3: Array[(String, Int)] = sortedRDD.take(3) //打印 println("=================top3===============start") top3.foreach(println) println("=================top3===============end") sortedRDD }) sortedDstream.print() //开启流式计算 ssc.start() ssc.awaitTermination() } }
Spark Streaming整合flume
flume作为日志实时采集的框架,可以与SparkStreaming实时处理框架进行对接,flume实时产生数据,sparkStreaming做实时处理。
Spark Streaming对接FlumeNG有两种方式,一种是FlumeNG将消息Push推给Spark Streaming,还有一种是Spark Streaming从flume 中Poll拉取数据。
Poll方式
(1)安装flume1.6以上
(2)下载依赖包
spark-streaming-flume-sink_2.11-2.0.2.jar放入到flume的lib目录下
(3)修改flume/lib下的scala依赖包版本
从spark安装目录的jars文件夹下找到scala-library-2.11.8.jar 包,替换掉flume的lib目录下自带的scala-library-2.10.1.jar。
(4)写flume的agent,注意既然是拉取的方式,那么flume向自己所在的机器上产数据就行
(5)编写flume-poll-spark.conf配置文件
a1.sources = r1 a1.sinks = k1 a1.channels = c1 #source a1.sources.r1.channels = c1 a1.sources.r1.type = spooldir a1.sources.r1.spoolDir = /root/data a1.sources.r1.fileHeader = true #channel a1.channels.c1.type =memory a1.channels.c1.capacity = 20000 a1.channels.c1.transactionCapacity=5000 #sinks a1.sinks.k1.channel = c1 a1.sinks.k1.type = org.apache.spark.streaming.flume.sink.SparkSink a1.sinks.k1.hostname=node1 a1.sinks.k1.port = 8888 a1.sinks.k1.batchSize= 2000
启动flume
bin/flume-ng agent -n a1 -c conf -f conf/flume-poll-spark.conf -Dflume.root.logger=info,console
代码实现:
引入依赖
<!--sparkStreaming整合flume--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-flume_2.11</artifactId> <version>2.0.2</version> </dependency>
代码
import java.net.InetSocketAddress import org.apache.spark.storage.StorageLevel import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream} import org.apache.spark.streaming.flume.{FlumeUtils, SparkFlumeEvent} import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.{SparkConf, SparkContext} //todo:需求:利用sparkStreaming整合flume---(poll拉模式) //通过poll拉模式整合,启动顺序---》启动flume----》sparkStreaming程序 object SparkStreamingFlumePoll { def main(args: Array[String]): Unit = { //1、创建SparkConf val sparkConf: SparkConf = new SparkConf().setAppName("SparkStreamingFlumePoll").setMaster("local[2]") //2、创建SparkContext val sc = new SparkContext(sparkConf) sc.setLogLevel("WARN") //3、创建StreamingContext val ssc = new StreamingContext(sc,Seconds(5)) //4、读取flume中的数据 val pollingStream: ReceiverInputDStream[SparkFlumeEvent] = FlumeUtils.createPollingStream(ssc,"192.168.200.100",8888) //定义一个List集合可以封装不同的flume收集数据 val address=List(new InetSocketAddress("node1",8888),new InetSocketAddress("node2",8888),new InetSocketAddress("node3",8888)) //val pollingStream: ReceiverInputDStream[SparkFlumeEvent] = FlumeUtils.createPollingStream(ssc,address,StorageLevel.MEMORY_AND_DISK_SER_2) //5、 event是flume中传输数据的最小单元,event中数据结构:{"headers":"xxxxx","body":"xxxxxxx"} val flume_data: DStream[String] = pollingStream.map(x => new String(x.event.getBody.array())) //6、切分每一行 val words: DStream[String] = flume_data.flatMap(_.split(" ")) //7、每个单词计为1 val wordAndOne: DStream[(String, Int)] = words.map((_,1)) //8、相同单词出现次数累加 val result: DStream[(String, Int)] = wordAndOne.reduceByKey(_+_) //9、打印 result.print() ssc.start() ssc.awaitTermination() } }
Push方式
编写flume-push-spark.conf配置文件
#push mode a1.sources = r1 a1.sinks = k1 a1.channels = c1 #source a1.sources.r1.channels = c1 a1.sources.r1.type = spooldir a1.sources.r1.spoolDir = /root/data a1.sources.r1.fileHeader = true #channel a1.channels.c1.type =memory a1.channels.c1.capacity = 20000 a1.channels.c1.transactionCapacity=5000 #sinks a1.sinks.k1.channel = c1 a1.sinks.k1.type = avro a1.sinks.k1.hostname=192.168.1.120 a1.sinks.k1.port = 8888 a1.sinks.k1.batchSize= 2000 [root@node1 conf]# [root@node1 conf]# [root@node1 conf]# vi flume-push-spark.conf #push mode a1.sources = r1 a1.sinks = k1 a1.channels = c1 #source a1.sources.r1.channels = c1 a1.sources.r1.type = spooldir a1.sources.r1.spoolDir = /root/data a1.sources.r1.fileHeader = true #channel a1.channels.c1.type =memory a1.channels.c1.capacity = 20000 a1.channels.c1.transactionCapacity=5000 #sinks a1.sinks.k1.channel = c1 a1.sinks.k1.type = avro a1.sinks.k1.hostname=192.168.75.57 a1.sinks.k1.port = 8888 a1.sinks.k1.batchSize= 2000
注意配置文件中指明的hostname和port是spark应用程序所在服务器的ip地址和端口。
启动flume
bin/flume-ng agent -n a1 -c conf -f conf/flume-push-spark.conf -Dflume.root.logger=info,console
代码开发
import java.net.InetSocketAddress import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream} import org.apache.spark.streaming.flume.{FlumeUtils, SparkFlumeEvent} //todo:需求:利用sparkStreaming整合flume-------(push推模式) //push推模式启动顺序:先启动sparkStreaming程序,然后启动flume object SparkStreamingFlumePush { def main(args: Array[String]): Unit = { //1、创建SparkConf val sparkConf: SparkConf = new SparkConf().setAppName("SparkStreamingFlumePush").setMaster("local[2]") //2、创建SparkContext val sc = new SparkContext(sparkConf) sc.setLogLevel("WARN") //3、创建StreamingContext val ssc = new StreamingContext(sc,Seconds(5)) //4、读取flume中的数据 val pollingStream: ReceiverInputDStream[SparkFlumeEvent] = FlumeUtils.createStream(ssc,"192.168.75.57",8888) //5、 event是flume中传输数据的最小单元,event中数据结构:{"headers":"xxxxx","body":"xxxxxxx"} val flume_data: DStream[String] = pollingStream.map(x => new String(x.event.getBody.array())) //6、切分每一行 val words: DStream[String] = flume_data.flatMap(_.split(" ")) //7、每个单词计为1 val wordAndOne: DStream[(String, Int)] = words.map((_,1)) //8、相同单词出现次数累加 val result: DStream[(String, Int)] = wordAndOne.reduceByKey(_+_) //9、打印 result.print() ssc.start() ssc.awaitTermination() } }
Spark Streaming整合kafka
-
-
这种方式默认数据会丢失,可以通过启用WAL预写日志,将接受到的数据同时也写入了到HDFS中,可以保证数据源端的安全性,当前Dstream中某个rdd的分区数据丢失了,可以通过血统,拿到原始数据重新计算恢复得到。
-
但是它保证不了数据只被处理一次。
引入依赖
<!--sparkStreaming整合kafka--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka-0-8_2.11</artifactId> <version>2.0.2</version> </dependency>
代码开发
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream} import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.streaming.kafka.KafkaUtils import scala.collection.immutable //todo:需求:利用sparkStreaming整合kafka---利用kafka高层次api(偏移量由zk维护) object SparkStreamingKafkaReceiver { def main(args: Array[String]): Unit = { //1、创建SparkConf val sparkConf: SparkConf = new SparkConf() .setAppName("SparkStreamingKafkaReceiver") .setMaster("local[4]")
.set("spark.streaming.receiver.writeAheadLog.enable","true") //开启WAL日志,保证数据源端的安全性 //2、创建SparkContext val sc = new SparkContext(sparkConf) sc.setLogLevel("WARN") //3、创建StreamingContext val ssc = new StreamingContext(sc,Seconds(5)) ssc.checkpoint("./kafka-receiver") //4、接受topic的数据 //zk服务地址 val zkQuorum="node1:2181,node2:2181,node3:2181" //消费者组id val groupId="sparkStreaming_group" //topic信息 //map中的key表示topic名称,map中的value表示当前针对于每一个receiver接受器采用多少个线程去消费数据 val topics=Map("itcast" -> 1) //(String, String):第一个String表示消息的key,第二个String就是消息具体内容 // val kafkaDstream: ReceiverInputDStream[(String, String)] = KafkaUtils.createStream(ssc,zkQuorum,groupId,topics) //这里构建了多个receiver接受数据 val receiverListDstream: immutable.IndexedSeq[ReceiverInputDStream[(String, String)]] = (1 to 3).map(x => { val kafkaDstream: ReceiverInputDStream[(String, String)] = KafkaUtils.createStream(ssc, zkQuorum, groupId, topics) kafkaDstream }) //通过调用streamingContext的union将所有的receiver接收器中的数据合并 val kafkaDstream: DStream[(String, String)] = ssc.union(receiverListDstream) // kafkaDstream.foreachRDD(rdd =>{ // rdd.foreach(x=>println("key:"+x._1+" value:"+x._2)) // }) //5、获取topic中的数据 val kafkaData: DStream[String] = kafkaDstream.map(_._2) //6、切分每一行 val words: DStream[String] = kafkaData.flatMap(_.split(" ")) //7、每个单词计为1 val wordAndOne: DStream[(String, Int)] = words.map((_,1)) //8、相同单词出现次数累加 val result: DStream[(String, Int)] = wordAndOne.reduceByKey(_+_) //9、打印 result.print() ssc.start() ssc.awaitTermination() } }
(1)启动zookeeper集群
zkServer.sh start
(2)启动kafka集群
kafka-server-start.sh /export/servers/kafka/config/server.properties
(3) 创建topic
kafka-topics.sh --create --zookeeper hdp-node-01:2181 --replication-factor 1 --partitions 3 --topic itcast
(4) 向topic中生产数据
通过shell命令向topic发送消息
kafka-console-producer.sh --broker-list hdp-node-01:9092 --topic itcast
(5)运行代码,查看控制台结果数据

总结:
通过这种方式实现,刚开始的时候系统正常运行,没有发现问题,但是如果系统异常重新启动sparkstreaming程序后,发现程序会重复处理已经处理过的数据,这种基于receiver的方式,是使用Kafka的高级API,topic的offset偏移量在ZooKeeper中。这是消费Kafka数据的传统方式。这种方式配合着WAL机制可以保证数据零丢失的高可靠性,但是却无法保证数据只被处理一次,可能会处理两次。因为Spark和ZooKeeper之间可能是不同步的。官方现在也已经不推荐这种整合方式,我们使用官网推荐的第二种方式kafkaUtils的createDirectStream()方式。
这种方式不同于Receiver接收数据,它定期地从kafka的topic下对应的partition中查询最新的偏移量,再根据偏移量范围在每个batch里面处理数据,Spark通过调用kafka简单的消费者Api(低级api)读取一定范围的数据。
相比基于Receiver方式有几个优点:
A、简化并行
不需要创建多个kafka输入流,然后union它们,sparkStreaming将会创建和kafka分区数相同的rdd的分区数,而且会从kafka中并行读取数据,spark中RDD的分区数和kafka中的topic分区数是一一对应的关系。
B、高效,
第一种实现数据的零丢失是将数据预先保存在WAL中,会复制一遍数据,会导致数据被拷贝两次,第一次是接受kafka中topic的数据,另一次是写到WAL中。而没有receiver的这种方式消除了这个问题。
C、恰好一次语义(Exactly-once-semantics)
Receiver读取kafka数据是通过kafka高层次api把偏移量写入zookeeper中,虽然这种方法可以通过数据保存在WAL中保证数据不丢失,但是可能会因为sparkStreaming和ZK中保存的偏移量不一致而导致数据被消费了多次。EOS通过实现kafka低层次api,偏移量仅仅被ssc保存在checkpoint中,消除了zk和ssc偏移量不一致的问题。缺点是无法使用基于zookeeper的kafka监控工具。
代码
import kafka.serializer.StringDecoder import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.streaming.dstream.{DStream, InputDStream} import org.apache.spark.streaming.kafka.KafkaUtils //todo:需求:利用sparkStreaming整合kafka,利用kafka低级api(偏移量不在由zk维护) object SparkStreamingKafkaDirect { def main(args: Array[String]): Unit = { //1、创建SparkConf val sparkConf: SparkConf = new SparkConf() .setAppName("SparkStreamingKafkaDirect") .setMaster("local[4]") //2、创建SparkContext val sc = new SparkContext(sparkConf) sc.setLogLevel("WARN") //3、创建StreamingContext val ssc = new StreamingContext(sc,Seconds(5)) //此时偏移量由客户端自己去维护,保存在checkpoint里面 ssc.checkpoint("./kafka-direct") //4、接受topic的数据 //配置kafka相关参数 val kafkaParams=Map("bootstrap.servers" ->"node1:9092,node2:9092,node3:9092","group.id" -> "spark_direct","auto.offset.reset" ->"smallest") //指定topic的名称 val topics=Set("itcast") //此时产生的Dstream中rdd的分区跟kafka中的topic分区一一对应 val kafkaDstream: InputDStream[(String, String)] = KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](ssc,kafkaParams,topics) //5、获取topic中的数据 val kafkaData: DStream[String] = kafkaDstream.map(_._2) //6、切分每一行 val words: DStream[String] = kafkaData.flatMap(_.split(" ")) //7、每个单词计为1 val wordAndOne: DStream[(String, Int)] = words.map((_,1)) //8、相同单词出现次数累加 val result: DStream[(String, Int)] = wordAndOne.reduceByKey(_+_) //9、打印 result.print() ssc.start() ssc.awaitTermination() } }
可以checkpoint目录来恢复StreamingContext对象
代码开发
import cn.itcast.streaming.socket.SparkStreamingSocketTotal.updateFunc import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream} //todo:利用sparkStreaming接受socket数据,实现整个程序每天24小时运行 //可以允许程序出现异常,再次重新启动,又可以恢复回来 object SparkStreamingSocketTotalCheckpoint { def createStreamingContext(checkpointPath: String): StreamingContext = { //1、创建SparkConf val sparkConf: SparkConf = new SparkConf().setAppName("SparkStreamingSocketTotalCheckpoint").setMaster("local[2]") //2、创建SparkContext val sc = new SparkContext(sparkConf) sc.setLogLevel("WARN") //3、创建StreamingContext对象 val ssc = new StreamingContext(sc,Seconds(5)) //需要设置一个checkpoint,由于保存每一个批次中间结果数据 //还会继续保存这个Driver代码逻辑,还有任务运行的资源(整个application信息) ssc.checkpoint(checkpointPath) //4、接受socket是数据 val socketTextStream: ReceiverInputDStream[String] = ssc.socketTextStream("192.168.200.100",9999) //5、切分每一行 val words: DStream[String] = socketTextStream.flatMap(_.split(" ")) //6、每个单词计为1 val wordAndOne: DStream[(String, Int)] = words.map((_,1)) //7、相同单词所有批次结果累加 val result: DStream[(String, Int)] = wordAndOne.updateStateByKey(updateFunc) //8、打印结果 result.print() ssc } def main(args: Array[String]): Unit = { val checkpointPath="./ck2018" //1、创建StreamingContext //通过StreamingContext.getOrCreate方法可以从checkpoint目录中恢复之前挂掉的StreamingContext //第一次启动程序,最开始这个checkpointPath目录没有的数据,就通过后面的函数来帮助我们产生一个StreamingContext //并且保存所有数据(application信息)到checkpoint //程序挂掉后,第二次启动程序,它会读取checkpointPath目录中数据,就从这个checkpointPath目录里面来恢复之前挂掉的StreamingContext //如果checkpoint目录中的数据损坏,这个你再次通过读取checkpoint目录中的数据来恢复StreamingContext对象不会成功,报异常 val ssc: StreamingContext = StreamingContext.getOrCreate(checkpointPath, () => { val newSSC: StreamingContext = createStreamingContext(checkpointPath) newSSC }) //启动流式计算 ssc.start() ssc.awaitTermination() } }

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步